对抗知识焦虑,从看懂这条开始
App 下载
机器人不再只会模仿,它开始理解物理世界了
RSS会议|因果推理|机器人物理理解|LDA模型|具身智能|人工智能
对抗知识焦虑,从看懂这条开始
App 下载RSS会议|因果推理|机器人物理理解|LDA模型|具身智能|人工智能
当你把一杯水从桌子边缘往中间推5厘米,你不需要反复练习——你知道只要用对力,杯子就会准确停在目标位置,不会突然滑出桌面,也不会穿透桌子。这是人类刻在骨子里的物理常识,但对机器人来说,曾经是一道难以逾越的坎。直到2026年5月,一款名为LDA的模型登上机器人顶会RSS,它第一次让机器人同时学会了两件事:预测环境会怎么变,以及自己该做什么。这意味着,机器人终于跳出了“模仿人类动作”的牢笼,开始像人一样理解物理世界的因果逻辑。
你可以把传统机器人的学习方式想象成照猫画虎——人类远程操控它完成动作,它把每一个关节的角度、每一次用力的大小都记下来,下次遇到一模一样的场景就复刻一遍。但只要场景有一点变化,比如杯子换了位置,或者桌面沾了点水,它就会瞬间“失忆”,成功率可能从90%跌到0%。
LDA模型彻底改写了这个逻辑。它构建了一个统一的“隐空间”——你可以把它理解成一个只装着核心信息的虚拟工具箱,里面没有无关的桌面花纹、杯子颜色,只有和物理规律相关的关键变量:物体的重量、表面的摩擦力、动作的力度方向。在这个空间里,它同时完成四件事:
这四个任务不是各自为政,而是像四个齿轮一样咬合转动:前向动力学帮它搞懂“环境会怎么变”,逆向动力学帮它想清楚“我该怎么做”,策略学习负责做决定,视觉预测则在旁边实时纠错。
过去训练机器人,大家都在抢高质量的“完美数据”——人类专家完美完成任务的示范视频。但LDA模型第一次证明,那些被当成垃圾的“失败数据”,比如机器人推杯子没推准、抓东西掉了的视频,反而更有价值。
就像学骑自行车,你不会只看别人怎么骑,摔过的那些跟头才会让你记住“车往哪边歪就往哪边拐”。LDA模型也是如此:它通过对比“动作有效”和“动作无效”的场景,能更快摸清楚物理世界的边界——比如杯子推多大会滑出桌面,用多大力能刚好抓住一个鸡蛋。

更重要的是,它打破了机器人对“完美数据”的依赖。低质量的网络视频、人类日常动作的无标注素材,甚至是仿真环境里生成的虚拟数据,都能被它用来学习物理常识。在测试中,只要混入30%的失败数据,机器人的执行成功率就能提升10%;而传统模型只要一碰到低质量数据,性能就会立刻下滑。
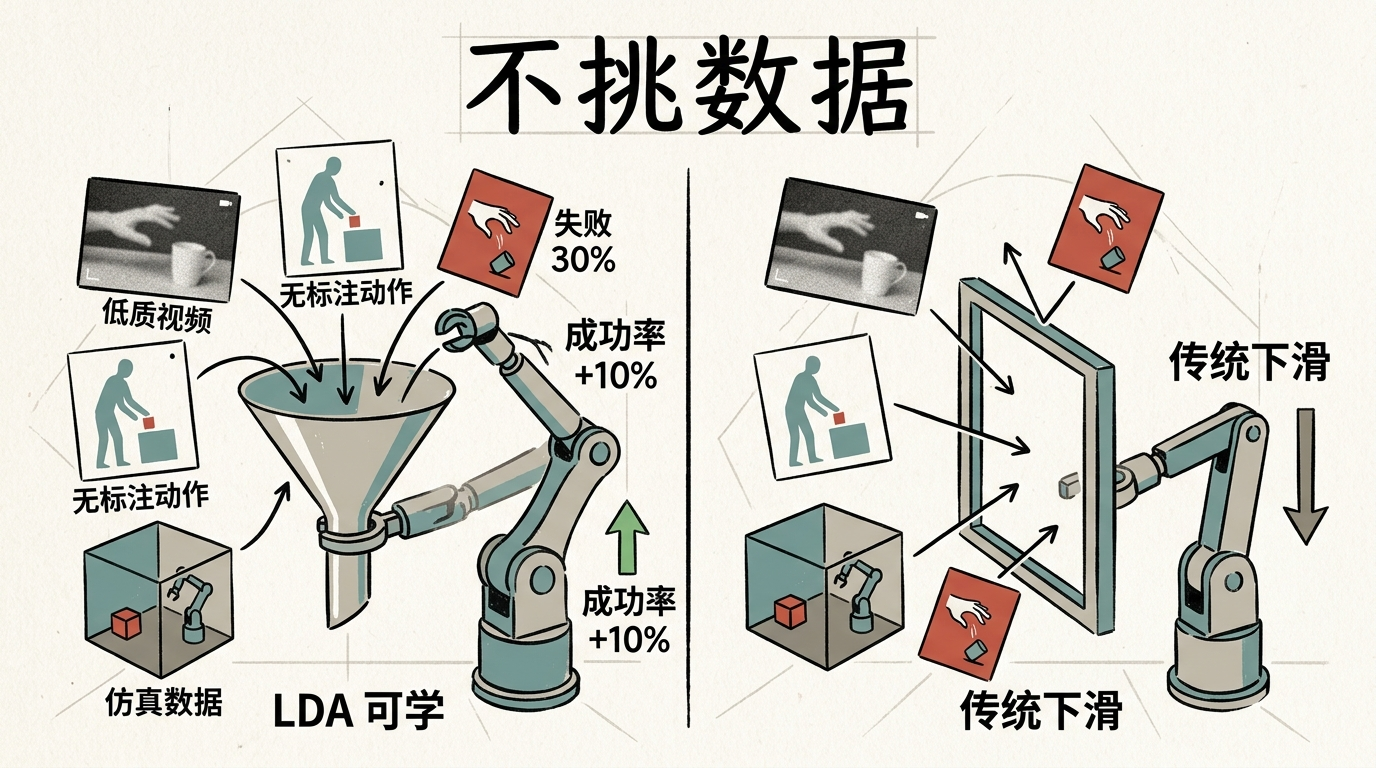
这种对数据的“不挑嘴”,直接把机器人的训练成本打了下来。过去要训练一个能完成复杂任务的机器人,可能需要上百小时的人类专家远程操作数据;现在只要用这些“野生数据”打底,再用几小时的高质量数据微调,就能达到甚至超过过去的效果。
LDA模型最让人兴奋的,是它的“跨本体泛化能力”——简单说就是学会了一个机器人的动作,换个全新的机器人,它只要花1小时就能适应。这在过去是不可想象的:每换一款机器人硬件,整个模型都要重新训练,成本高到大部分工厂都不敢尝试。
在真实的工业场景测试中,LDA模型已经展现出了落地潜力:在接触丰富的装配任务中,成功率比传统模型提升21%;在需要精细操作的拧螺丝任务中,成功率提升48%;在需要连续完成多个步骤的长时序任务中,成功率提升23%。
但它也不是没有局限。目前它还只能处理视觉和动作数据,触觉、力觉等更精细的感知信息还没完全融入;而且在一些极端复杂的动态场景中,比如人流密集的商场里导航,它的预测精度还会下降。更重要的是,具身智能的商业化,从来都不只是算法的问题——硬件的稳定性、成本的控制、场景的适配,每一环都缺一不可。
当我们谈论具身智能的“GPT时刻”,我们真正期待的从来都不是一个能完美复刻人类动作的机器人,而是一个能像人一样理解世界的机器人——它知道杯子会因为重力下落,知道推东西要用对方向,知道失败了该怎么调整。
LDA模型的出现,就是这个时刻的前奏。它没有给机器人装上更灵活的关节,也没有给它换上更清晰的摄像头,它只是给了机器人一个能理解物理世界的“大脑”。
理解世界,比模仿动作更重要。 这不仅是机器人的进化方向,也是我们对AI的最终期待:不是做人类的影子,而是做人类的伙伴。