对抗知识焦虑,从看懂这条开始
App 下载
复旦团队用64个令牌解决AI图像压缩死穴
图像压缩|后验坍塌|图像分词器|MacTok|复旦大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像压缩|后验坍塌|图像分词器|MacTok|复旦大学|多模态视觉|人工智能
当你让AI用64个“关键词”还原一张512×512的高清图时,它会交上来一堆模糊的色块——这是过去连续图像分词器的宿命:压缩到极致就会“摆烂”,输出的令牌全是毫无意义的噪声,连AI自己都没法还原出有效图像。这就是困扰学界多年的“后验坍塌”,堪称连续图像压缩的死穴。直到2026年3月,复旦大学团队推出的MacTok,用一套简单到近乎“粗暴”的方法,把这个死穴彻底堵上了。
你可以把连续图像分词器理解成一个“图像压缩员”,任务是把几百万像素的图片,压缩成几十个携带核心信息的“令牌”。过去的压缩员很会偷懒:反正解码器能靠高斯分布的“标准答案”兜底,它随便输出点噪声就能蒙混过关——这就是后验坍塌:编码器输出的令牌完全丧失语义,变成了标准高斯分布的噪声。
MacTok的解法是给这个“懒员工”出难题:训练时随机把图片的70%区域打上马赛克,要求它仅凭剩下的30%还原出完整图像。这就像让你仅凭半页残稿还原一整本小说,再想偷懒输出废话根本过不了关。为了完成任务,编码器必须从残片中提炼出最核心的语义信息,每一个令牌都得精准携带关键线索。
更狠的是,MacTok还会专门遮住图像中最关键的语义区域——比如狗的头部、花朵的花蕊。它先用Meta的DINOv2模型定位出这些核心区域,然后刻意把它们挡住,逼模型通过上下文推理出关键信息。这种“哪壶不开提哪壶”的训练方式,直接把AI的语义理解能力拉到了新高度。

光逼AI好好干活还不够,MacTok还得给这些令牌“安家”——让每个令牌都有明确的语义分工,同时确保所有令牌能协同表达整图的全局语义。
它采用了“全局+局部”的双重对齐策略:每个潜在令牌会对应DINOv2模型提取的一个局部图像块特征,保证细粒度的语义一致性;同时,所有令牌的平均结果会和DINOv2的全局特征对齐,确保整体语义准确。就像一支球队,每个球员都有自己的位置,但所有人的目标都是赢下整场比赛。
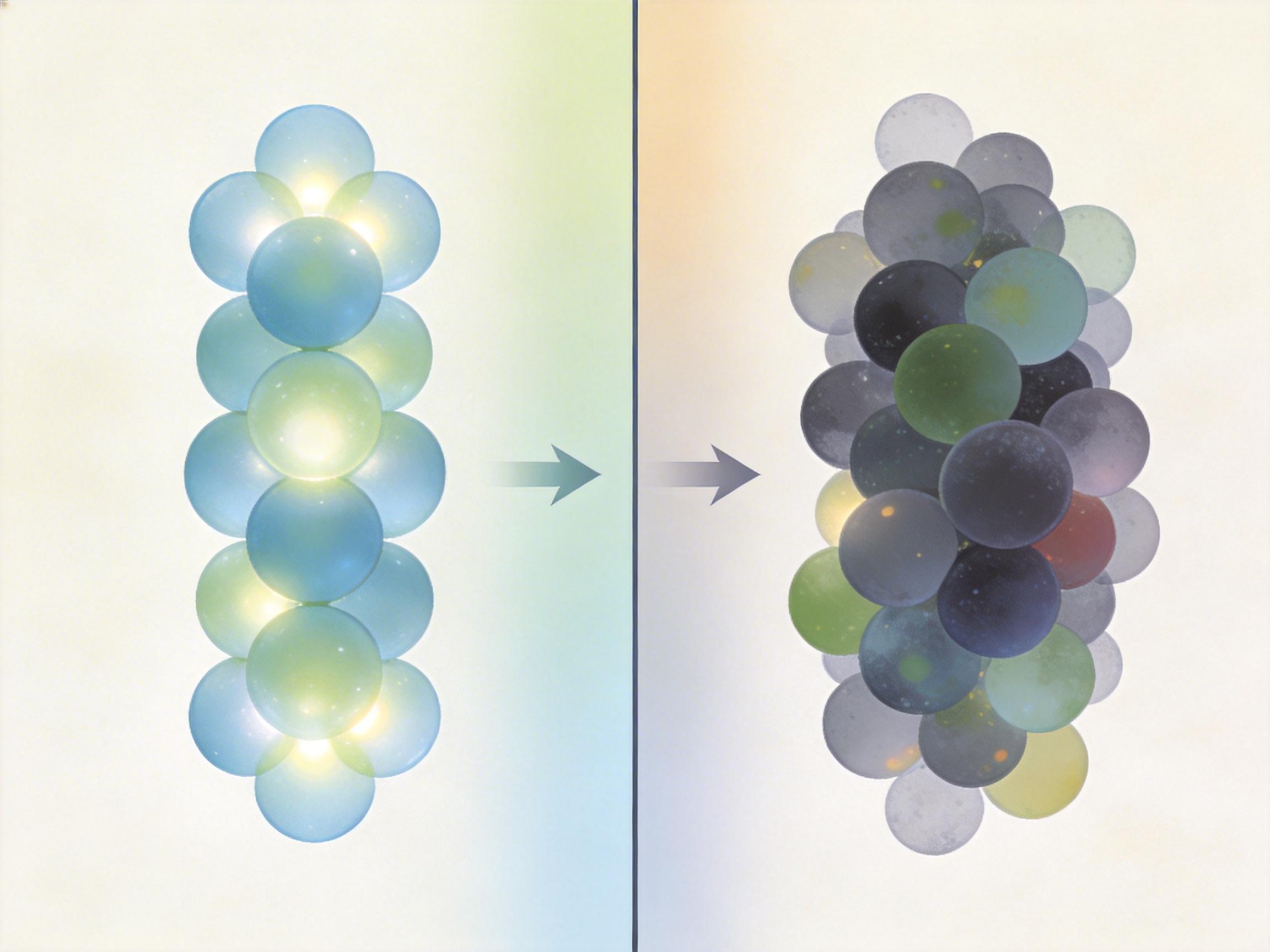
这种对齐策略带来了立竿见影的效果:MacTok的潜在空间里,语义相近的图像会自动聚成一团,不同类别之间界限清晰。而传统连续分词器的潜在空间则是一团混沌,所有图像的令牌都混在一起,根本没法区分。在ImageNet数据集上,MacTok用64个令牌就能达到gFID 1.58的生成质量,128个令牌更是能达到gFID 1.44的SOTA水平,比传统方法少用了90%以上的令牌。
不过,MacTok并非完美无缺。它的核心能力高度依赖DINOv2的预训练特征,如果换一个领域——比如医学影像、抽象艺术——DINOv2的语义定位能力会大打折扣,MacTok的表现也会随之下降。目前它在专业领域的泛化能力还未得到充分验证。
另外,MacTok的训练流程相当复杂:多损失函数、多阶段训练,还要依赖外部模型,调参难度极大,对计算资源的要求也很高。更关键的是,目前论文还未公开代码和完整数据集,这意味着其他研究团队很难复现和改进它的成果,一定程度上阻碍了技术的推广。
还有一个未解决的问题是:当令牌数低于64时,MacTok的性能会跌到什么程度?目前的研究都集中在中高令牌数的表现,极限压缩下的能力边界还不清晰。
MacTok的意义,不止于解决了后验坍塌这个技术难题,更在于它提供了一种新的思路:与其在模型结构上做复杂的加法,不如通过设计更难的训练任务,逼AI自己学会更高效的表达。
在AI图像生成越来越追求“大模型、大算力”的今天,MacTok用极少的令牌实现了SOTA级别的生成质量,为轻量化、高效化的图像生成开辟了新路径。它让我们看到,有时候最有效的技术突破,往往来自于对“懒模型”的精准“鞭策”。 金句:逼AI做难题,才是高效压缩的核心。