对抗知识焦虑,从看懂这条开始
App 下载
用ls操作数据库?这个工具打通了两种数据世界
数据事务保障|文件系统挂载|命令行工具|PostgreSQL|TigerFS|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据事务保障|文件系统挂载|命令行工具|PostgreSQL|TigerFS|AI产业应用|人工智能
想象一下:你不用打开数据库客户端,不用写一行SQL,只敲一个ls命令,就能看到PostgreSQL里的所有表;用cat就能读取某条数据;甚至拖放文件,就能完成任务状态的流转——从待办到已完成,全程自带事务保障,不会出现多人修改导致的数据混乱。这不是科幻,是2026年刚上线的TigerFS正在做的事。它把数据库直接变成了一个可以挂载的文件夹,让你用最熟悉的命令行工具,操作最专业的结构化数据。为什么会有人做这样的工具?因为在AI智能体和开发者的世界里,复杂的API远不如简单的文件操作顺手。
你可以把TigerFS的核心逻辑,想象成给数据库套了一层文件系统的“皮肤”——在Linux上靠FUSE(用户空间文件系统)、在macOS上靠NFS,它能把PostgreSQL的表映射成目录,每一行数据变成一个文件,文件里的内容就是结构化的数据。
这个“皮肤”不是花架子。当你用echo '新内容' > 文件名修改文件时,TigerFS会自动把这个操作转换成数据库的事务写入,自带ACID保障——要么全部成功,要么全部回滚,绝不会出现改到一半崩溃导致的数据残缺。而当你在目录之间移动文件,比如从“待办”拖去“已完成”,这个动作会被自动转换成数据库的状态更新,多个人同时操作也不会冲突。
它甚至支持两种模式:如果你习惯先整理文件再管数据,就用“文件优先”模式——把Markdown文档丢进目录,自动获得版本控制和并发编辑能力;如果你手里已经有现成的数据库,就用“数据优先”模式——直接把数据库挂载成文件夹,用find和grep就能完成复杂查询,不用再写嵌套的SQL语句。
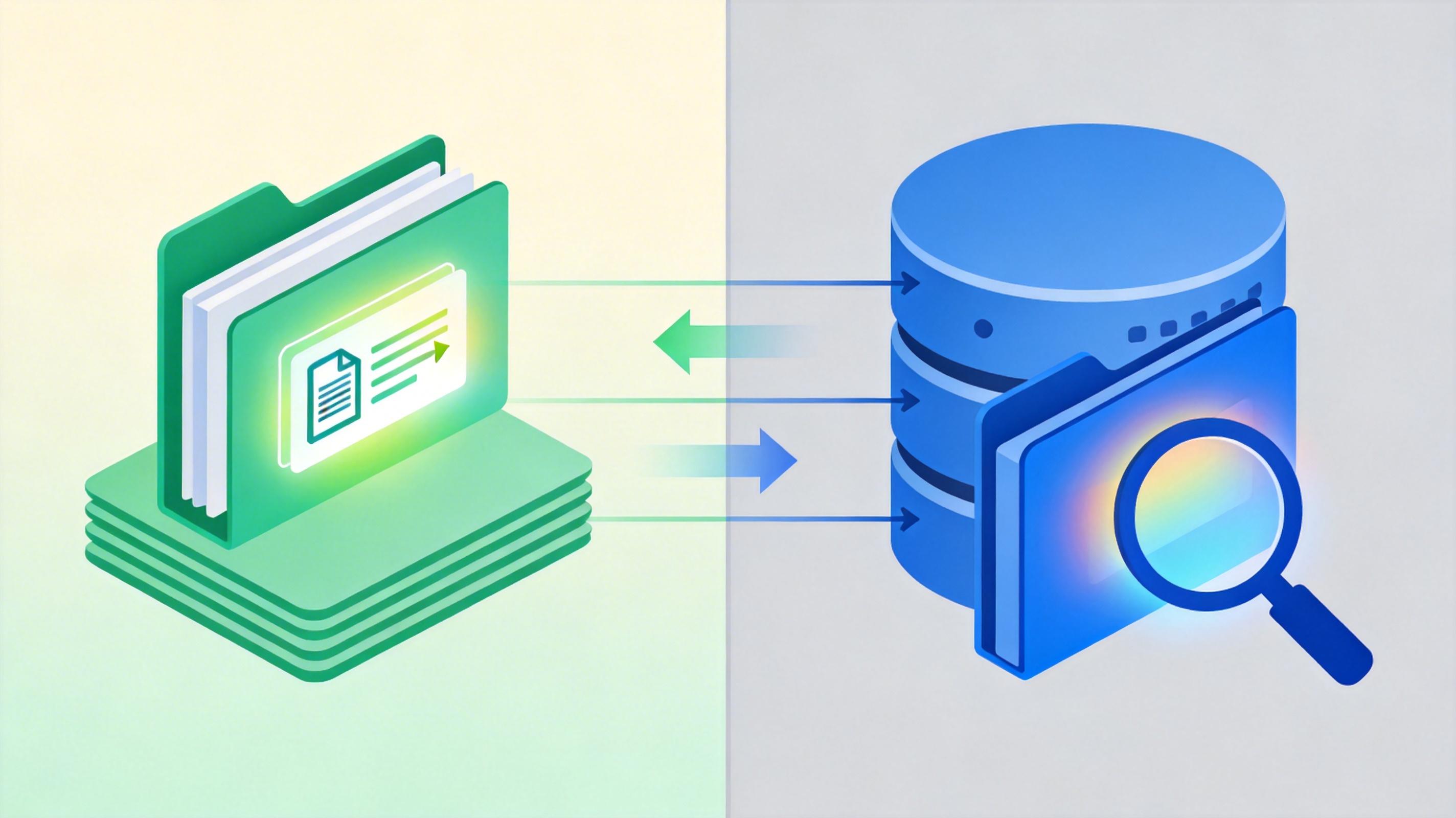
要实现这种“无缝衔接”,核心是FUSE这个已经存在了25年的技术。简单说,FUSE就像一个翻译官:当你发出ls这样的文件系统命令,它会把命令翻译成数据库能听懂的查询,等数据库返回结果后,再把结果包装成文件列表的样子给你看。
和直接操作数据库不同,FUSE把文件系统的逻辑放在了用户空间,不用修改内核代码,这大大降低了开发门槛,但也带来了性能开销——毕竟每一次命令都要在用户态和内核态之间“跳个舞”。不过对AI智能体和开发者常用的场景来说,比如管理配置文件、任务队列、小规模知识库,这个开销完全可以接受。
更关键的是,TigerFS没有丢掉数据库的核心优势。它不是把数据复制到文件系统,而是直接把数据库当存储后端。这意味着你享受到的不仅是文件操作的简单,还有数据库的事务、版本控制、权限管理——比如你可以“fork”一个数据库文件夹做测试,测试完直接删掉,不会影响原数据。
当然,TigerFS不是万能的。社区里的开发者已经指出了它的局限:如果是处理超大规模的数据集,比如几十亿行的生产表,用grep遍历的速度肯定不如直接写SQL快;而且目前它只支持PostgreSQL,暂时还没法对接其他数据库。
但它的价值不在于替代传统数据库操作,而在于填补了一个空白——当AI智能体需要协作时,它们不需要复杂的API,就像人喜欢用文件夹整理文件一样,智能体也喜欢用ls和cat来获取信息。比如一个多智能体团队,一个智能体负责收集资料,一个负责整理,一个负责输出,它们可以共享同一个TigerFS文件夹,各自用熟悉的工具操作,不用再写复杂的同步逻辑。
就像项目创始人Michael Freedman说的:“智能体不需要复杂的API,它们喜欢文件系统。”这句话点透了TigerFS的本质——它不是为了炫技,而是为了贴合真实的使用场景。
其实,TigerFS的出现不是偶然。从2000年Oracle尝试把数据库挂载成文件系统,到2001年FUSE诞生降低文件系统开发门槛,再到现在AI智能体对简单数据接口的需求,它是技术积累到一定阶段的必然产物。
它真正的意义,是打破了“文件系统”和“数据库”之间的墙——原来我们不用在“简单易用”和“专业可靠”之间二选一,把两者结合起来,就能诞生出更贴合用户需求的工具。
工具的终极进化,是让用户忘记工具的存在。当你用ls操作数据库时,你不会觉得这是一个黑科技,只会觉得:“哦,原来数据本来就该这么用。”