对抗知识焦虑,从看懂这条开始
App 下载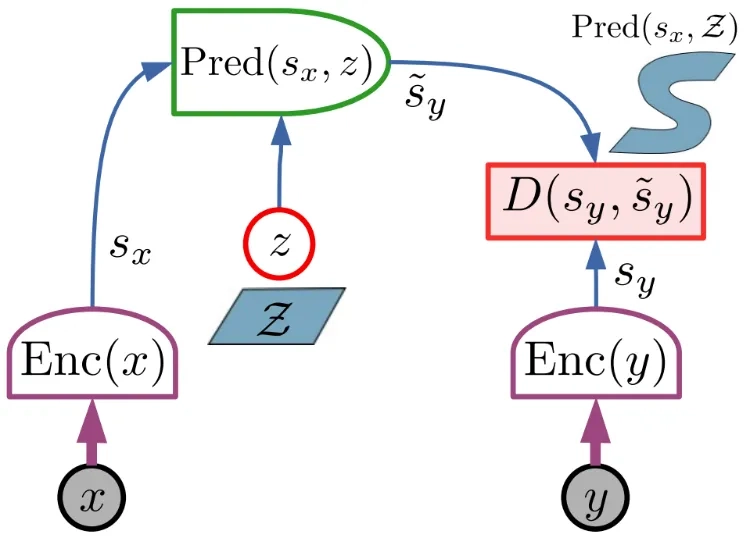
机器人学会了“做梦”,但离做家务还远
人类动作视频|强化学习|物理世界规则|机器人做梦|世界模型|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载人类动作视频|强化学习|物理世界规则|机器人做梦|世界模型|AI智能体|人工智能
一台从未见过鞋带的机器人,俯下身抓住鞋带,轻轻一抽就解开了——它没学过这个动作,只是“看”了几千小时人类系鞋带、拆快递、叠衣服的视频,在自己的“想象”里反复预演了无数次。这就是最近吸金超百亿美元的“世界模型”:让AI像人类一样在脑子里构建物理世界的规则,预测动作的后果。但当资本把这个概念炒成下一个AI风口时,很少有人说破:这些会“做梦”的机器人,连炒一盘稳定的虾都做不到。
你可以把世界模型的诞生,看成两个科研团队各自憋大招,直到最近才撞出火花。 一边是强化学习领域的“做梦派”:从1990年代开始,他们就想让AI在虚拟环境里“预演”动作——就像人类下棋前在脑子里算几步。2018年的World Models架构第一次让AI“梦见”了赛车游戏的赛道,2025年的DreamerV3甚至能在《我的世界》里从零开始挖钻石。但这些模型像偏科的学霸:能把单个游戏玩到人类水平,换个游戏就得从头学起。 另一边是计算机视觉的“看片派”:他们从2016年开始,让AI啃下几百万小时人类视频,学习杯子掉地上会碎、门推一下会开的物理规律。直到OpenAI的Sora出现,AI能生成看起来完全符合物理的视频,但它只是个“放映机”——你没法让它暂停,输入一个动作,看接下来会发生什么。 2024到2025年,两项技术突破把两条路焊在了一起:AR-DiT让视频模型学会“按时间顺序”生成画面,而不是一次性全做完;Self Forcing把生成速度从35步压缩到4步。终于,AI既能“看片学物理”,又能“做梦预演动作”——这就是我们现在说的视频世界模型。
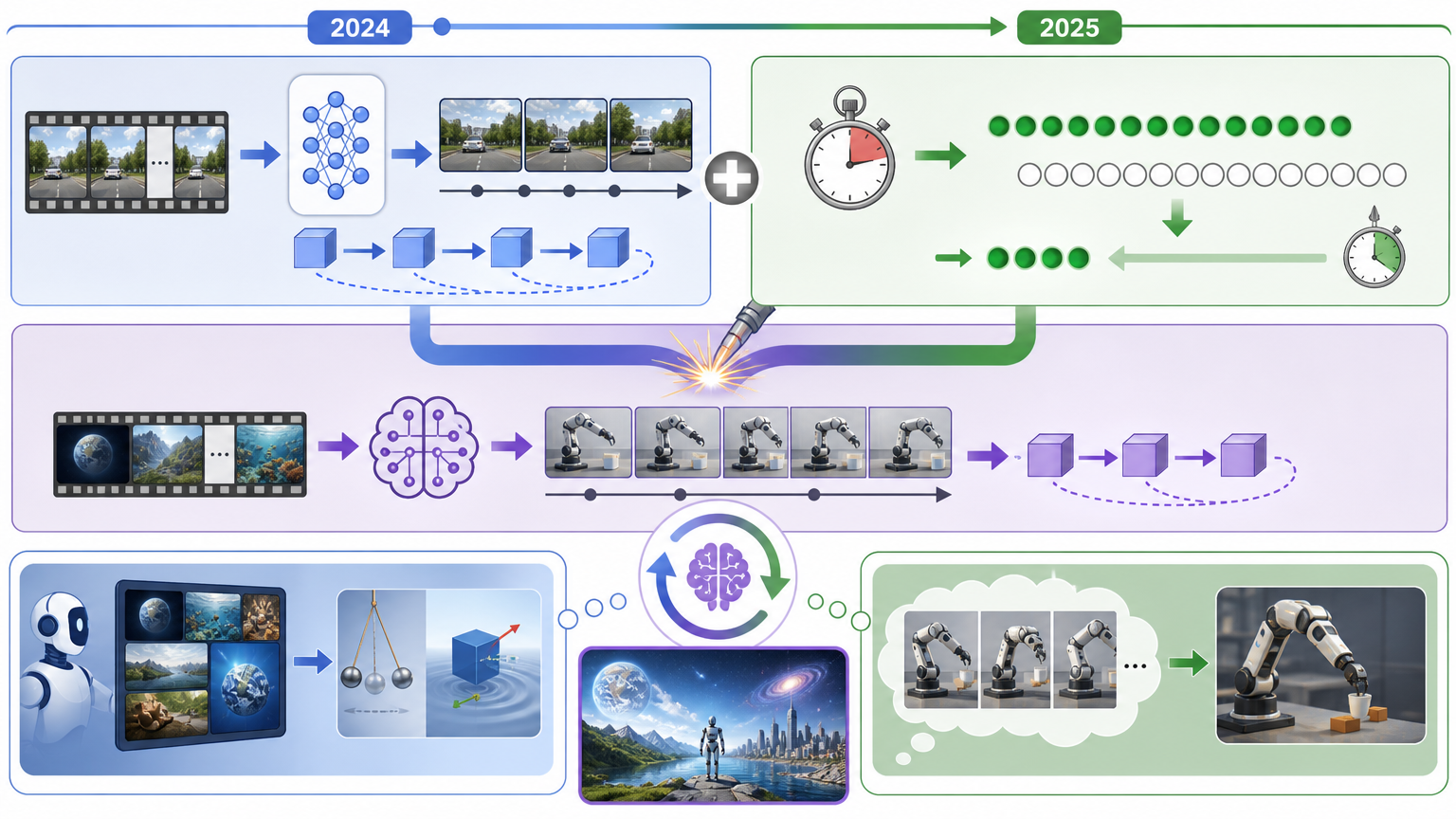
资本的热情把世界模型吹成了机器人的“通用大脑”,但真实的能力边界,比融资额清醒得多。 最成熟的应用是自动驾驶仿真:Waymo用世界模型生成暴雨、逆行车辆等极端场景,测试自动驾驶算法,这已经在生产环境里跑起来了。机器人领域也有小范围突破:DreamDojo能以0.995的准确率预测机器人策略的成功率,相当于给机器人做“模拟考”;DreamGen让机器人看一次抓放演示,就能在陌生环境里完成22种新动作。
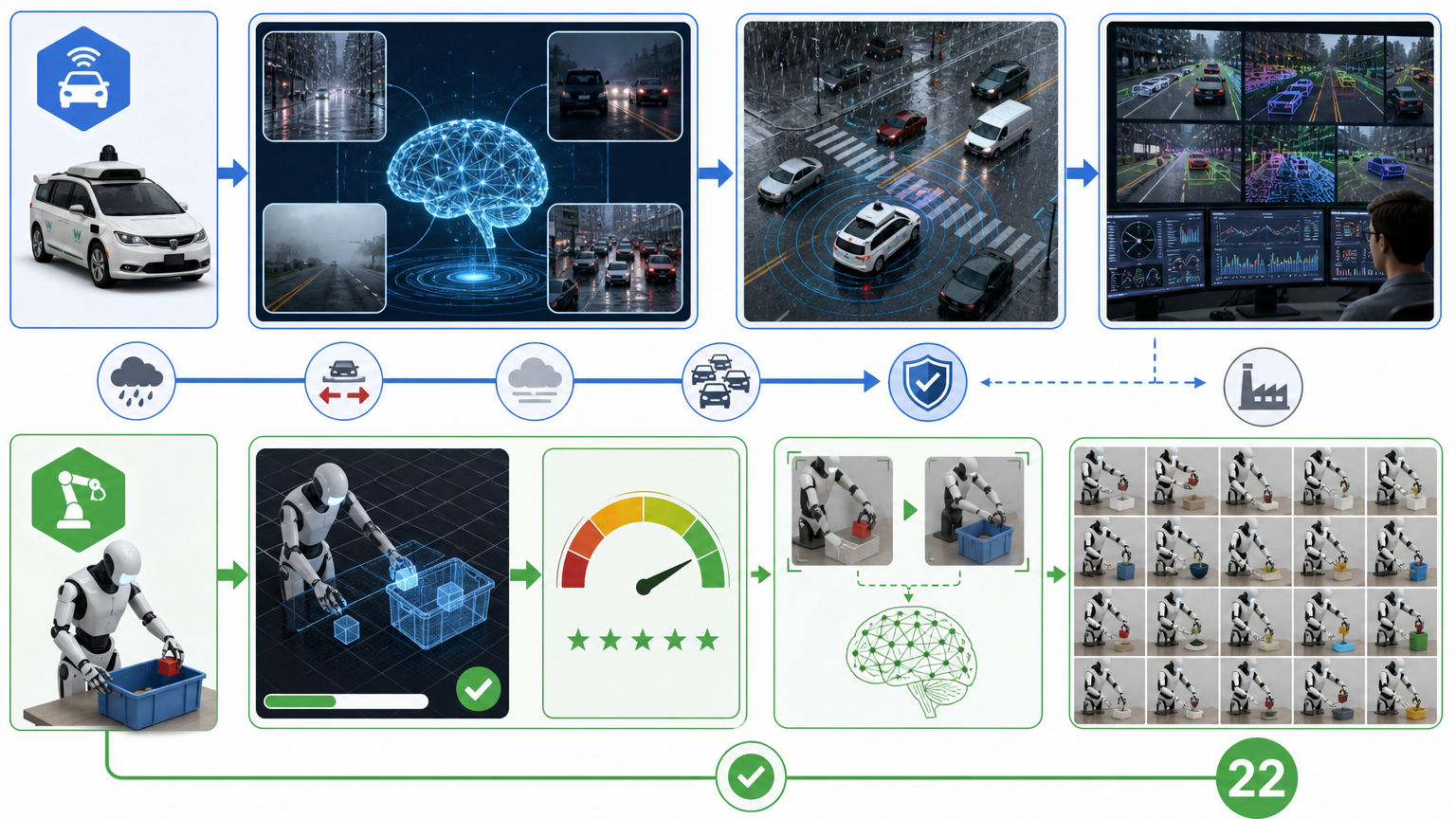
但这些都是“特定场景的胜利”。现在最先进的机器人,炒虾得学50次演示,换个菜又得重来;通用家庭操作、家具组装这类需要精细触感的任务,所有方法都还在卡壳。更关键的是,直接用世界模型控制机器人的尝试,还停留在实验室论文里,没有经过独立验证。 更值得关注的是,现在工业界用得最多的还是视觉-语言-动作模型(VLA)——它不用“做梦”,直接从人类演示里学动作。就连最领先的VLA模型Pi-0.7,也只是加了个小型世界模型做子目标规划,而不是完全替代。
百亿美元的融资里,藏着巨头们的战略棋盘。 NVIDIA是最激进的玩家:它开源了从视频预训练到机器人控制的全栈工具,就像当年用CUDA垄断AI算力一样,想把世界模型变成物理AI时代的“操作系统”——它的DreamDojo模型在4.4万小时人类视频上预训练,能实时生成符合物理规律的场景,但只有用它的Blackwell芯片才能跑起来。

Yann LeCun的团队反其道而行之:他们觉得“预测像素”是浪费算力,直接让AI学抽象的物理规律,不用生成视频。这种JEPA架构在抓放任务上实现了80%的零样本成功率,但它的“预测”是人类看不懂的抽象向量,就像让你闭着眼猜下一步棋,你永远不知道它想的对不对。 而那些拿到大融资的机器人公司,大多选择“两条腿走路”:用VLA模型解决当下的落地问题,用世界模型探索未来的泛化能力——毕竟,资本要的是现在能落地的产品,而不是十年后的科幻。
当我们谈论机器人的“世界模型”时,其实是在问一个最朴素的问题:机器能不能像人一样,“理解”这个世界? 现在的答案是:它能模仿人类的动作,能在特定场景里预测简单的物理变化,但离“理解”还差得远——它不知道鞋带的“软”、杯子的“脆”,只是从像素里学到了一组概率。就像一个背熟了题库的学生,能答对所有见过的题,但换个题型就懵了。 智能的本质,从来不是会做梦,而是会理解。 百亿美元砸出的,不是机器人的“通用大脑”,只是一个更聪明的“模仿者”。它离能帮你做家务的那天,还有无数个实验室的夜晚,和无数次失败的预演。