对抗知识焦虑,从看懂这条开始
App 下载
不用相机参数,秒把旅游照变可控3D场景
相机参数无约束|光照可控|旅游照片|3D重建|WildSplatter模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载相机参数无约束|光照可控|旅游照片|3D重建|WildSplatter模型|多模态视觉|人工智能
你手机里存着几十张埃菲尔铁塔的照片:清晨的冷灰调、黄昏的金橙色、阴天的暗哑质感,还有游客乱入的糊片。你曾想过把这些乱糟糟的照片拼成一个能随意切换光照的3D模型吗?以前这是天方夜谭——传统3D重建要么要精确的相机参数,要么要求所有照片光照一致,还得花几小时迭代计算。但现在,日本三所大学的团队做到了:用WildSplatter模型,仅需0.375秒,就能从两张无约束的旅游照里重建出可调控光照的3D场景。它到底是怎么突破这些限制的?
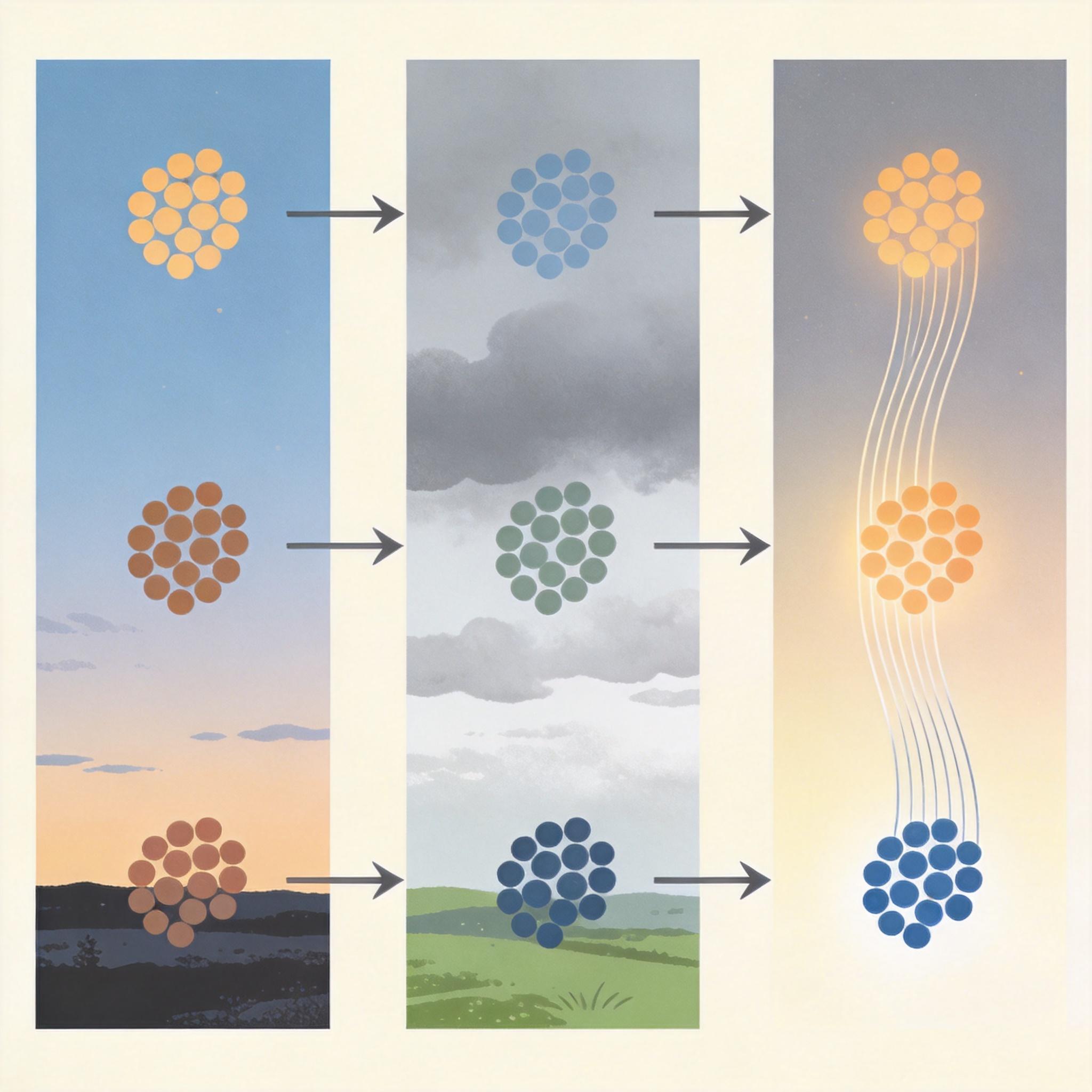
你可以把3D重建想象成搭积木加涂颜料:传统方法是一边搭积木一边上色,光照一变就得全部推倒重来。WildSplatter的核心思路,是先搭好无色的“骨架”——也就是场景的几何结构,再单独给这个骨架“涂颜料”——用外观信息控制光照和色调。
这个“拆家”操作在AI里叫“解耦”。具体来说,它用预训练好的Depth Anything 3视觉模型当“骨架师”,从多张照片里提取出3D高斯点的位置、大小、旋转和不透明度,这些参数只和场景的物理结构有关,和光照完全无关。然后再用一个轻量模块生成64维的“外观嵌入”——你可以把它理解成一个浓缩了光照风格的“调色盘密码”,用这个密码就能给固定的骨架调出任意光照下的颜色。
整个过程是纯前馈的:把照片喂进去,模型一次计算就输出所有结果,不用像传统方法那样反复迭代优化。这就是它能做到秒级重建的关键。
传统3D重建的另一个死穴,是必须知道每张照片的拍摄角度和位置——也就是相机参数。但网上随便下的旅游照,谁会给你附这些数据?
WildSplatter的解决办法是,让模型自己从照片里“猜”视角关系。它用Transformer的跨帧全局注意力机制,把多张照片的信息拼在一起,隐式地学习不同视角之间的几何约束。打个比方,就像你看了两张从不同角度拍的杯子照片,不用别人说,也能脑补出杯子的3D形状——模型做的就是类似的事,只不过是用数学方法实现。
这种设计不仅跳过了相机参数的麻烦,还让模型更鲁棒:就算照片里有行人、车辆这些瞬态物体,模型也能通过预测不透明度,自动把这些“干扰项”屏蔽掉,只保留稳定的场景结构。
WildSplatter最有意思的能力,是它的“外观嵌入”能跨场景迁移。你可以把埃菲尔铁塔黄昏照的“调色盘密码”提取出来,直接套用到波士顿街景的3D骨架上,就能得到黄昏时分的波士顿街景。

论文里用t-SNE可视化了这个“调色盘密码”的空间:所有黄昏风格的照片会聚集在一个区域,所有阴天风格的照片会聚集在另一个区域,说明这个64维的向量真的精准捕捉了光照的本质,而不是某个场景的特有颜色。你甚至可以在两个“调色盘密码”之间插值,生成从白天到黄昏的渐变光照效果。
当然它也有局限:目前的外观嵌入是全局的,还没法处理局部阴影、镜面反射这些复杂的光照细节;而且只能处理静态场景,要是照片里的物体在动,重建效果就会打折扣。
WildSplatter的意义,不止是秒级3D重建本身,更在于它证明了:只要找对了“拆”的方法,混乱的真实世界数据也能被AI驯服。以前3D重建是实验室里的精密游戏,现在它终于能走进普通人的手机相册、走进互联网上的野生照片库。
把复杂拆成简单,让混乱归于秩序。这不仅是WildSplatter的核心,也是AI技术从实验室走向真实世界的通用逻辑。或许用不了多久,你随手拍的街景照,就能一键变成可随意调整光照的3D数字资产——而这一切,只需要不到一秒。