对抗知识焦虑,从看懂这条开始
App 下载
AI主播终于不穿模:给模型装物理草稿纸
AI视频生成|物理合理性指标|清华|阿里|CoInteract框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI视频生成|物理合理性指标|清华|阿里|CoInteract框架|多模态视觉|人工智能
当你刷到AI主播带货的视频,可能见过这样的离谱画面:主播伸手拿口红,手指直接穿过管体;拧瓶盖时,手指软得像融化的蜡笔——这些「手残」穿模的场景,是AI视频生成的老顽疾。直到2026年4月,阿里与清华联合推出的CoInteract框架,把物理合理性指标拉涨了33%,让AI第一次「懂」了:手不能穿过物体,手指得有骨头。这不是简单的画质升级,而是给AI的脑子里,塞了一张物理课的草稿纸。
传统AI视频生成模型,本质上是「像素模仿者」。它见过几百万张RGB像素组成的图片,能模仿出逼真的皮肤纹理、衣服褶皱,但它不知道「手」是由关节组成的结构,也不知道「物体有边界」——它只知道像素的统计规律,不知道三维空间的物理规则。
这就导致两个致命问题:一是手部、脸部这类细节密集的区域,模型容易「力不从心」,把手指糊成香肠、把五官揉成面团;二是完全无视物理边界,手穿过杯子、物体悬浮在空中都是常态。之前的解决方案要么依赖复杂的3D建模预处理,要么靠后处理修修补补,要么让AI主播只做挥手、转身这类简单动作——但这些都不是治本之策。
CoInteract的思路是:不让AI只看「美颜后的成品图」,而是在训练时给它看「物理草稿纸」。
CoInteract的核心是两个「草稿纸」机制,像给AI开了两门补习班:
这张草稿纸叫HOI结构流——把RGB视频里的皮肤、衣服纹理全部剥离,只留下黑色的人体剪影,再用高亮颜色标出物体的轮廓。训练时,模型同时看RGB视频和这张草稿纸,相当于一边看成品,一边看「哪里是手、哪里是杯子、它们怎么接触」的结构示意图。
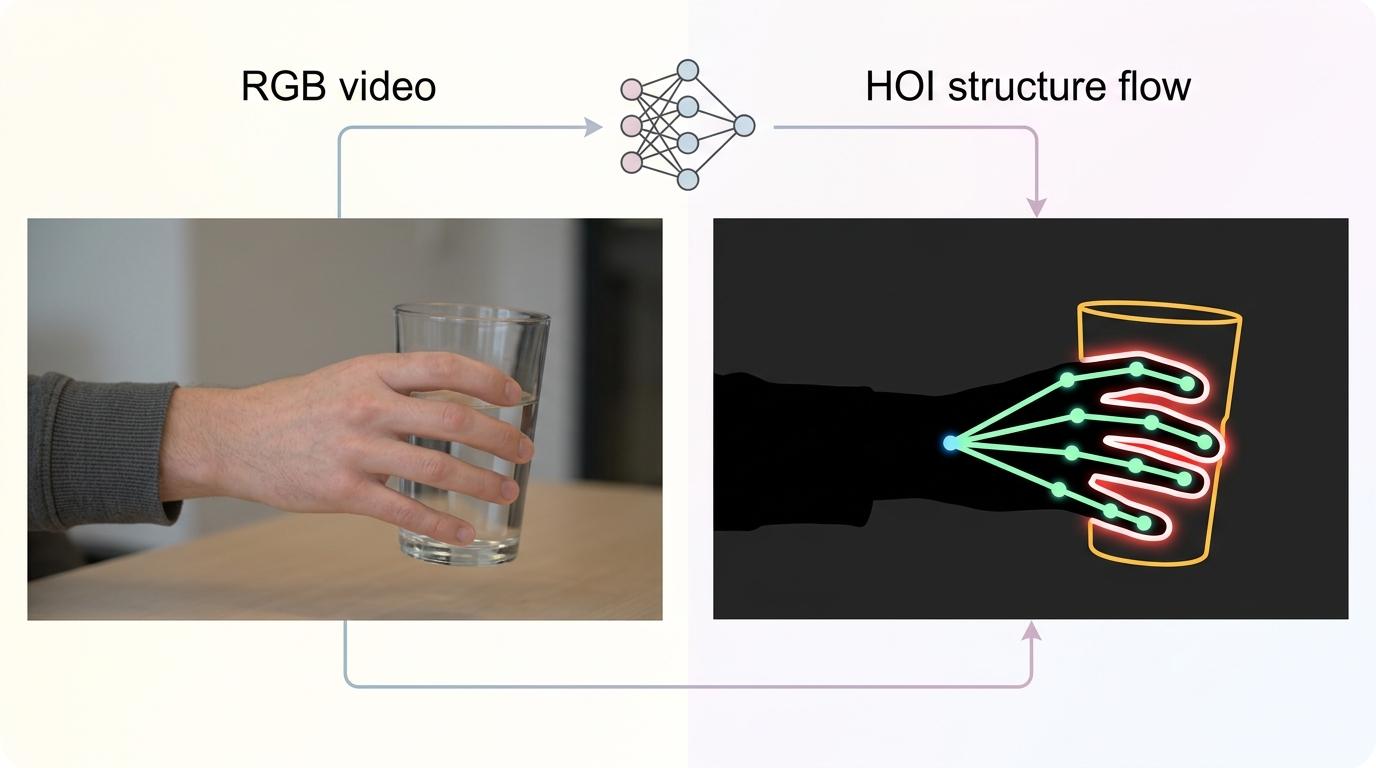
为了让AI真正学会这些规则,团队设计了「非对称共注意力掩码」:训练时,HOI结构流可以参考RGB视频的细节,但RGB视频不能依赖结构流的提示。等到推理阶段,直接把HOI结构流的分支砍掉,只保留RGB生成的部分——这就像学生考试时不能看草稿纸,但已经把草稿纸上的规则记进了脑子里。
针对手部、脸部容易糊的问题,CoInteract给模型装了「分科老师」:用一个轻量的路由器,判断当前处理的像素是手、脸还是背景,然后分给对应的「手部专家」「脸部专家」处理。这些专家网络参数量很小,但专门优化了关节结构、面部细节的稳定性——就像让眼科医生看眼睛,骨科医生看骨头,比全科医生更精准。
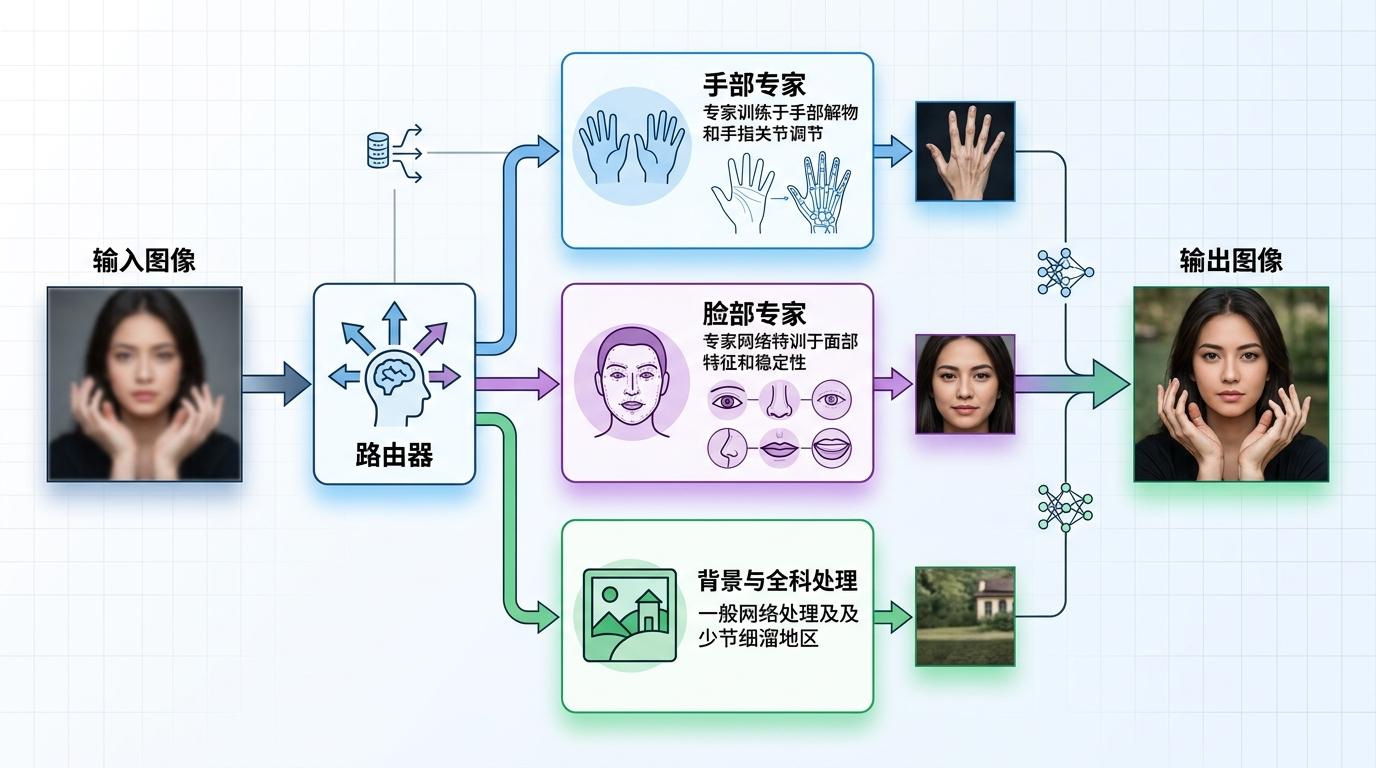
数据证明了这两个机制的威力:去掉HOI结构流,物理合理性指标直接暴跌33%;去掉混合专家,手部质量得分从0.724掉到0.658,手指糊成一团的问题立刻重现。
在与6种主流AI视频生成方法的对比中,CoInteract的物理合理性得分(VLM-QA)达到0.72,比第二名高出16%;手部质量得分0.724,独占鳌头。24人的盲测中,它在「交互合理性」上的平均排名是1.79,第二名只有3.33——几乎所有测试者都能一眼认出,哪个视频的动作更像真人。
但它也有局限:目前的训练数据以电商直播为主,户外、多物体交互的场景还没经过充分验证;生成的视频最长只有81帧,长视频的物理一致性还需要优化;更重要的是,它依赖高质量的结构流预处理,复杂遮挡场景下的草稿纸绘制还不够精准。
不过,CoInteract真正的价值,是提供了一种新范式:与其让AI在像素里瞎摸物理规则,不如直接把结构先验「装」进模型。这不是AI的突然开窍,而是工程师用巧妙的设计,给AI搭了一座从像素到物理的桥。
当AI终于学会「手不能穿过杯子」,我们看到的不只是一个更逼真的带货主播,而是AI理解世界的方式正在改变——从模仿像素,到理解结构;从统计规律,到认知规则。
给AI装草稿纸,比让它画一万张图更有用。
未来的AI视频生成,或许会有更多这样的「草稿纸」:比如模拟重力的力学草稿纸,模拟光影的光学草稿纸。那时的AI,才不是只会模仿的画匠,而是懂物理、懂规则的创作者。