对抗知识焦虑,从看懂这条开始
App 下载
一张老照片,吹出可逛的3D世界
虚拟现实体验|开源生成技术|空间遗忘|2D照片转3D|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载虚拟现实体验|开源生成技术|空间遗忘|2D照片转3D|AIGC|人工智能
你有没有盯着童年老屋的照片发呆——想推开门摸一摸掉漆的门框,回头看看堂屋八仙桌上的瓷碗?以前这是《盗梦空间》里的幻想,2026年的今天,它成了普通人能碰的技术。只需上传一张2D照片,AI能瞬间把它“吹胀”成可走动、可回头看的3D世界。更关键的是,这项能当“造物主画笔”的技术,被完全开源了。它解决了AI造3D世界的两大噩梦:不会“转身就忘”,也不会“越走越歪”。
你可以把AI生成3D场景想象成盲人摸象——每走一步摸一块地方,走得远了,就忘了之前摸过的大象耳朵长什么样。这就是“空间遗忘”:当你从客厅走到卧室再回头,沙发可能换了位置,墙上的画凭空消失了。
还有更隐蔽的“时间漂移”:AI每生成一帧画面,都会带点微小误差——沙发颜色偏深一点,门框歪了1度。走十步看不出来,走一百步,整个场景就像被放进了哈哈镜,面目全非。
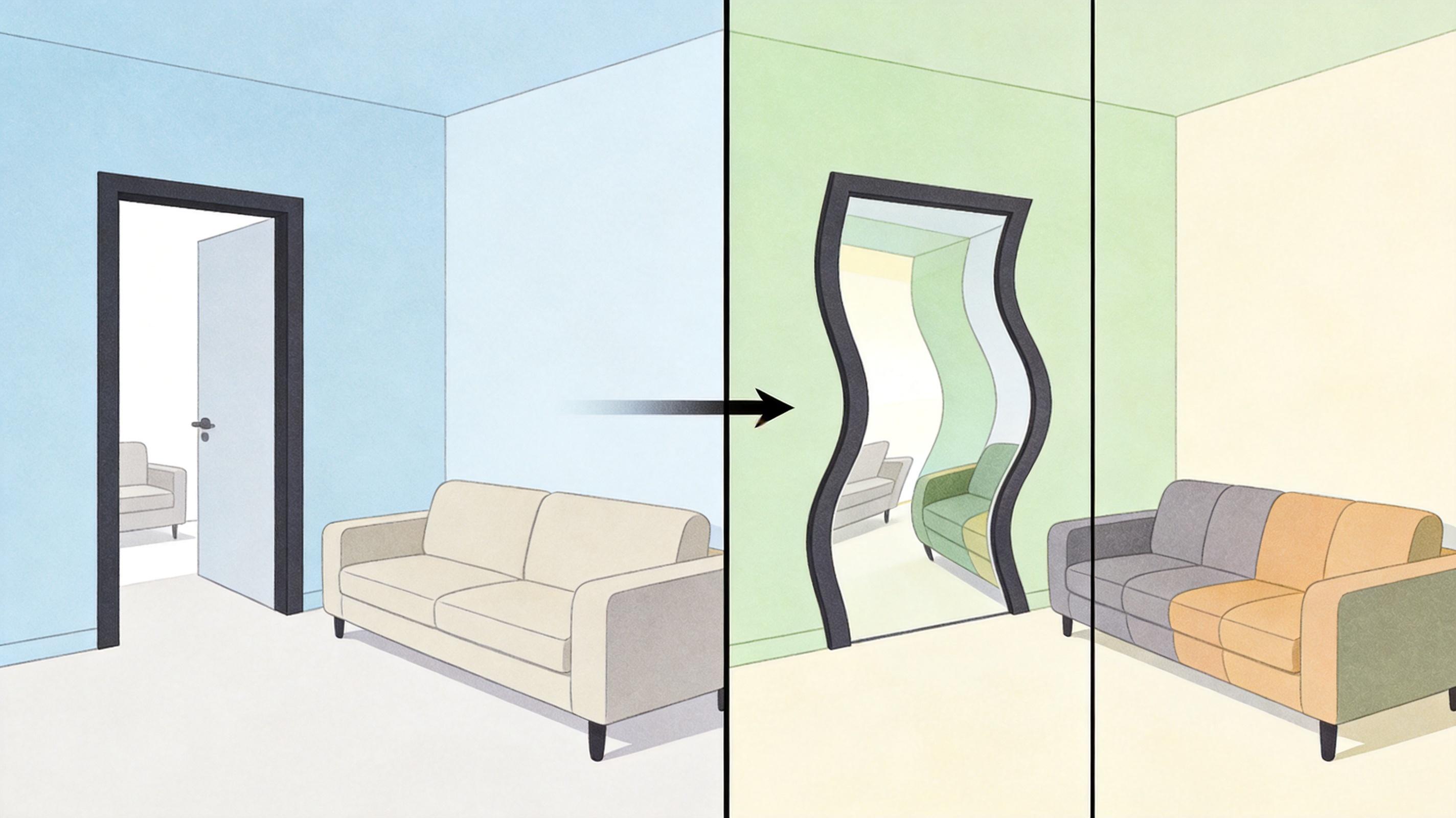
这两个问题卡住了AI造3D世界的脖子十年:要么只能做小房间,要么走着走着就崩了。直到这次的技术出现,才用两招把这两个噩梦摁住了。
第一招是给AI装了个“空间记忆GPS”。
以前AI生成新画面时,只会盯着眼前的信息瞎猜,现在它会给每一步看到的场景存一份“3D骨架”——不是直接用来画画,而是当导航:走到新位置时,先查GPS,找到和当前视角重叠的“记忆片段”,再根据这些片段补全新画面。就像你逛商场时,靠之前记住的扶梯位置,能准确找到回去的路,而不是重新瞎逛。
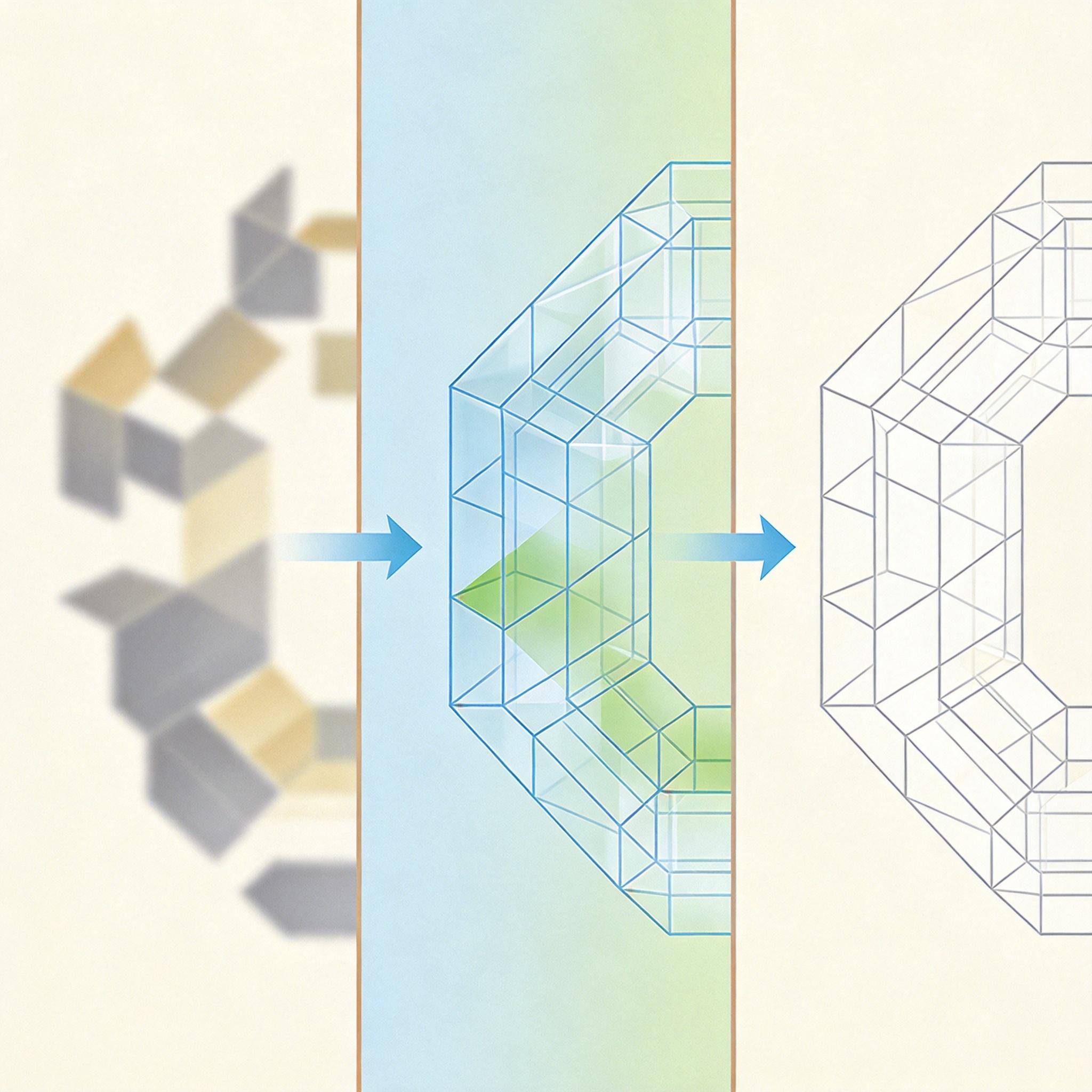
第二招是“自增强训练”——让AI自己吃自己的“错”。
训练时,故意把AI生成的带误差的画面喂回去,逼它学会“看见歪的门框就修正,看见偏色的沙发就调回来”,而不是把错误越传越远。就像让学生改自己的作业,改多了,下次就不会再犯同样的错。
直给数据:在标准测试中,去掉GPS导航,回访区域的错误率飙升40%;去掉自增强训练,长距离行走后的场景失真度翻了3倍。只有两招一起用,才能让你在3D世界里逛几十米,回头还能认出刚进门时的玄关。
现在你能拿着老照片逛回童年,但别指望这个3D世界能像真的一样运转——你推不开那扇门,桌上的瓷碗也拿不起来。

这项技术本质上还是“高级画匠”:它能把2D画面的细节以3D方式补全,却不懂“门是用来推的”“碗放在桌上不会飘起来”这些物理规则。它生成的是“看起来真实”的场景,不是“能真实运转”的世界。
更现实的门槛是算力:生成一个中等大小的场景,需要顶级GPU跑几十分钟,普通人的电脑还扛不住。而且它目前只能处理静态场景,要是你想让照片里的猫跑起来,它还做不到。
当这项技术被完全开源,意味着不是只有大公司能造3D世界了——学生可以用它把插画作业变成可逛的游戏关卡,设计师能快速把草图变成客户能走进去看的样板间,甚至有人能把去世亲人的照片,变成一个能“回去看看”的小空间。
它不是完美的造物主,但它把“造世界”的门槛,从专业工作室拉到了普通人的电脑前。AI造的不是世界,是让回忆可触摸的入口。