对抗知识焦虑,从看懂这条开始
App 下载
不用重新训练,一个模型通杀全领域异常检测
表格数据|ICLR会议|跨领域数据|异常检测|UniOD模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载表格数据|ICLR会议|跨领域数据|异常检测|UniOD模型|大语言模型|人工智能
想象一下:银行的反欺诈系统、工厂的设备故障预警、医院的影像异常识别,居然能共用同一个AI模型——不用针对每个场景重新训练,不用反复调参,拿到新领域的数据直接就能输出结果。这不是科幻,是2026年ICLR会议上,两位中国学者拿出的UniOD模型做到的事。它在57个跨领域数据集上击败了17种主流方法,甚至只用表格数据训练,却能看懂图像和文本里的异常。最关键的是,它打破了一个行业默认的规则:AI模型必须「一个领域一个模型」。这背后到底藏着什么逻辑?
要让AI看懂不同领域的数据,第一步得解决「语言不通」的问题——银行的交易流水、工厂的传感器数据、医院的影像特征,本质上是完全不同的「数据语言」,就像中文、英文和阿拉伯语,AI根本没法直接对比。
UniOD的解法是做一个「通用翻译器」:不管拿到什么数据,先把它转换成一张「关系图」。你可以把这个过程理解成,把每个数据样本变成一个人,然后计算每两个人之间的「相似度」——比如银行里的两笔交易,金额、时间、账户重合度越高,相似度就越高;工厂里的两个传感器数据,波动规律越像,相似度就越高。用多个不同尺度的高斯核函数计算完所有样本的相似度后,就得到了一张全连接的关系图,每个样本是节点,连线的粗细代表相似度。
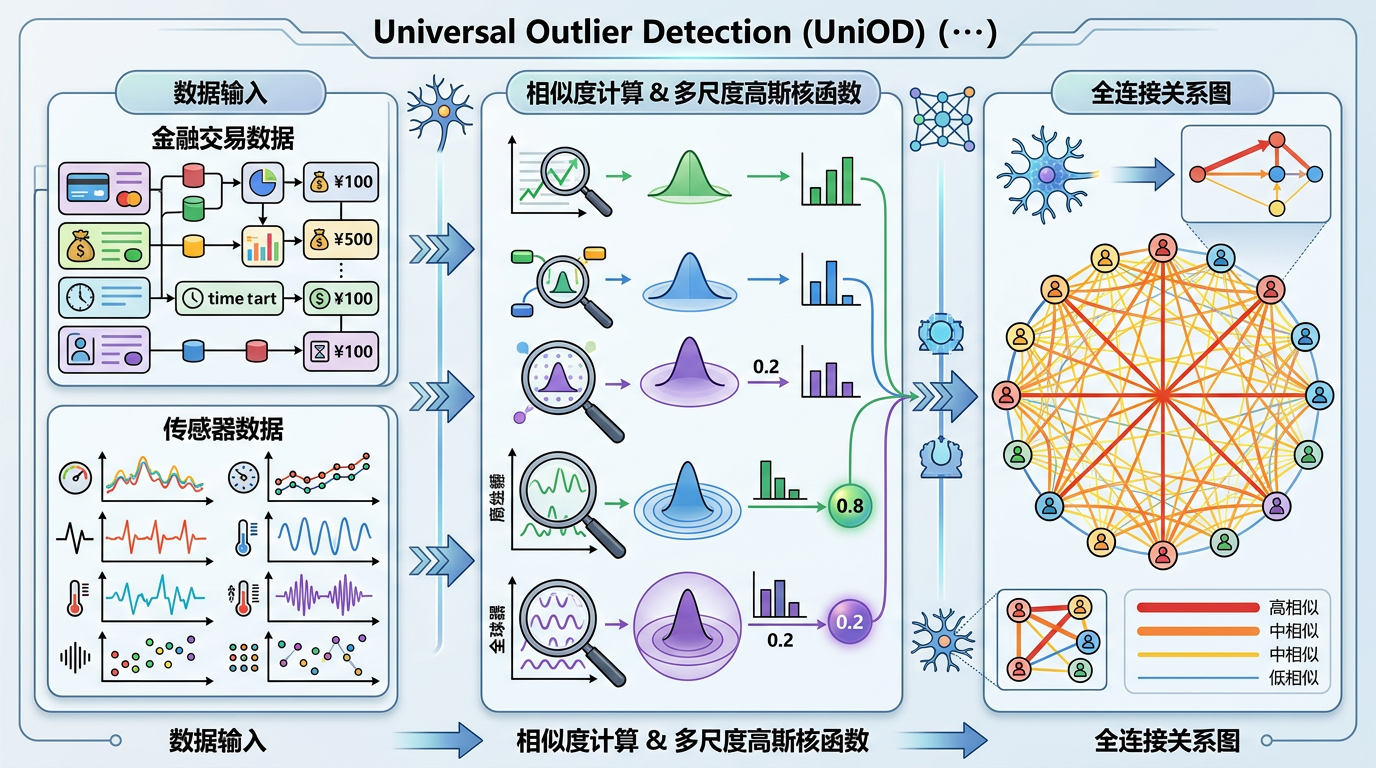
接下来用奇异值分解(SVD)给这张图「拍X光片」,提取出最核心的结构特征。不管原始数据是10维还是1000维,经过这一步都会变成维度统一的特征向量。就像不管是中文的「苹果」还是英文的「apple」,翻译成通用语后都是同一个符号,AI终于能跨领域对比数据了。
解决了语言问题,接下来要让AI学会怎么从关系图里找异常。传统异常检测是盯着单个样本看——比如某笔交易金额远高于平均值,就标记为异常,但这种方法很容易被伪装的欺诈绕过。UniOD的思路是,把异常检测变成「找不合群的人」:在关系图里,正常样本会和其他相似样本聚成一团,异常样本则会孤零零地飘在外面,或者连到奇怪的群体里。
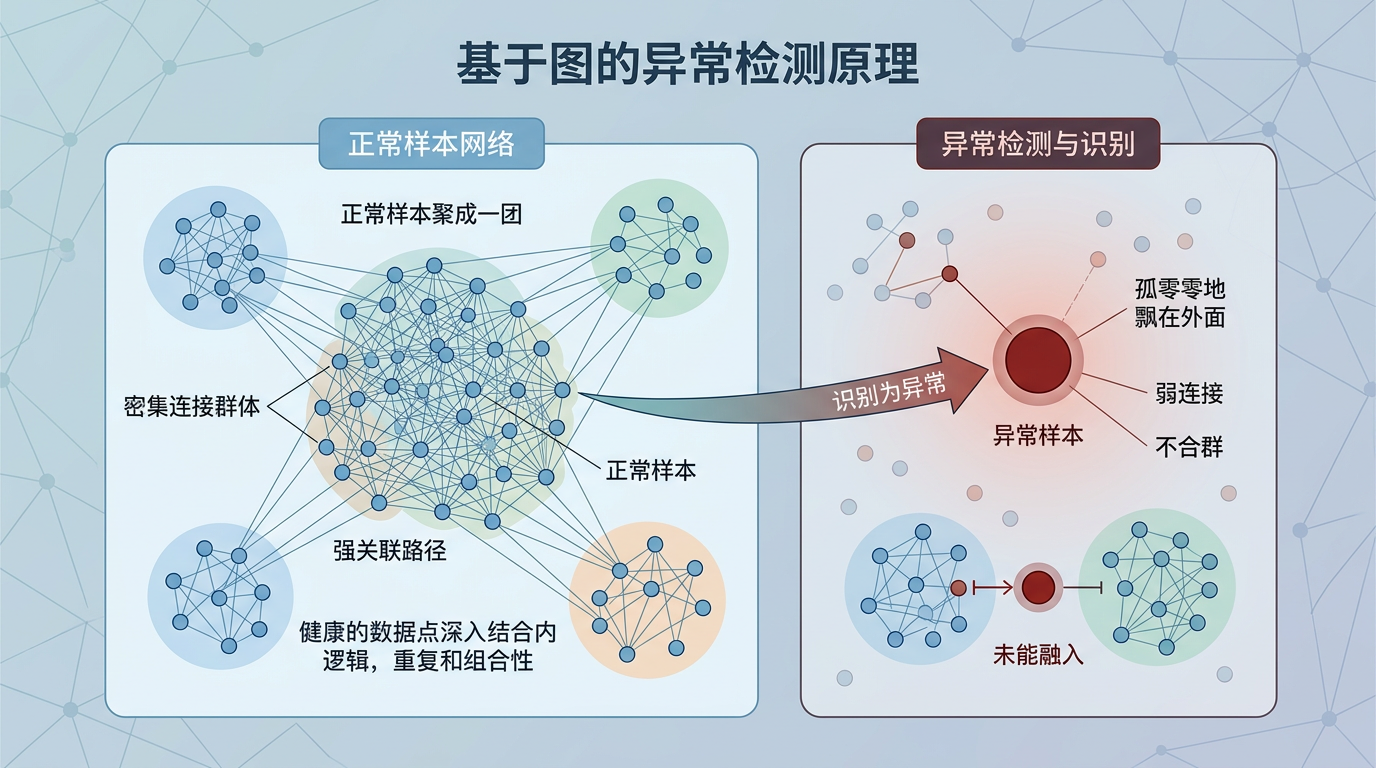
它用了图同构网络(GIN)和Transformer并行的结构——GIN负责盯着局部关系,看每个样本和它的「邻居」们合不合群;Transformer则负责全局扫描,看整个网络里有没有奇怪的连接模式。打个比方,就像查假币时,GIN负责摸钞票的纹理、水印这些细节,Transformer则负责看这张钞票的编号有没有出现在假币黑名单里。
训练的时候,UniOD会把多个领域的关系图混在一起学,就像让AI同时看银行、工厂、医院的「社交网络」,慢慢总结出「正常关系」的共性——比如正常的交易总是和同类型账户关联,正常的传感器数据总是和相邻传感器同步波动。等它学完这些共性,再拿到新领域的关系图,不用重新训练,直接就能找出那些不符合「正常关系」的异常节点。
你可能会问:这种跨领域的通用模型,真的靠谱吗?UniOD的研究者给出了数学上的保证——泛化误差界定理。简单说就是:用来训练的领域数据越多,模型在新领域的表现就越好;GIN和Transformer的层数要恰到好处,太少学不到足够的关系,太多则会「钻牛角尖」,只记住训练数据的细节,反而看不懂新数据。
这个定理不是拍脑袋来的,实验数据完全能对应上:当训练用的数据集从1个增加到15个时,UniOD的检测准确率稳步提升;当GIN层数超过5层后,模型在新领域的表现反而开始下降。而且就算故意拿掉和测试领域相同的训练数据,UniOD的性能也不会暴跌——因为它学的是「关系的共性」,不是某个领域的特定规则。
有意思的是,UniOD甚至能「举一反三」:只用表格数据训练的模型,居然能识别图像和文本里的异常。原因很简单,不管是图像的像素还是文本的单词,转换成关系图后,核心的异常模式是相通的——都是「不合群的节点」。
UniOD最让人兴奋的地方,不是它击败了多少基线方法,而是它打破了AI领域的一个惯性思维:我们总在为特定场景定制模型,却忘了从数据里找共性。就像人类学会了看「关系」,就能看懂不同领域的问题——医生能从症状的关联里找病因,侦探能从线索的关联里找凶手,现在AI也学会了这一点。
「通用AI的核心,是学会数据的共性」。这句话听起来简单,但UniOD把它变成了现实。未来我们可能不再需要为每个场景单独训练AI模型,而是用一个通用模型,就能看懂从金融到医疗的所有异常。这不仅能省下大量的计算资源,更重要的是,它让AI真正变成了一个能跨领域思考的「通用工具」。