对抗知识焦虑,从看懂这条开始
App 下载
1.3M参数的小模型,干翻了RAW图像处理的大模型
模型参数量|图像信号处理|残差仿射|RAW图像增强|RPBA-Net|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型参数量|图像信号处理|残差仿射|RAW图像增强|RPBA-Net|大语言模型|人工智能
你手机按下快门的瞬间,传感器捕捉到的RAW数据要经过十多道ISP工序才能变成你看到的照片——去马赛克、白平衡、降噪、锐化……每一步都可能把误差传到下一环。过去人们要么用繁琐的传统模块堆流程,要么用动辄几十M参数的大模型当黑盒,直到2026年的RPBA-Net出现:它只用1.3M参数,在RAW图像增强的所有指标上,全面超越了那些比它大几十倍的对手。更离谱的是,它每一步调整都能说清逻辑,再也不是让人摸不着头脑的黑盒。这到底是怎么做到的?
要理解RPBA-Net的巧思,得先明白传统深度学习ISP的死穴:它们直接让模型从RAW数据“猜”最终RGB图像,就像让一个人闭着眼拼图,拼得再准你也不知道他是怎么拼的。而RPBA-Net把这个过程拆成了两步——先画个草稿,再精细修改。
它先把RAW数据打包成4通道的紧凑格式,用一个轻量网络生成一张基础RGB图像,这就像画家先打了个线稿。接下来关键的一步来了:它不直接修改像素颜色,而是预测一组“调整参数”——每个像素对应一个3×4的仿射变换矩阵残差。你可以把这个矩阵想象成给每个像素定制的“调色旋钮”,不是直接涂颜色,而是告诉模型“把这个像素的红调亮一点,蓝压暗一点”,所有调整都有明确的数学对应,再也不是黑盒里的玄学操作。
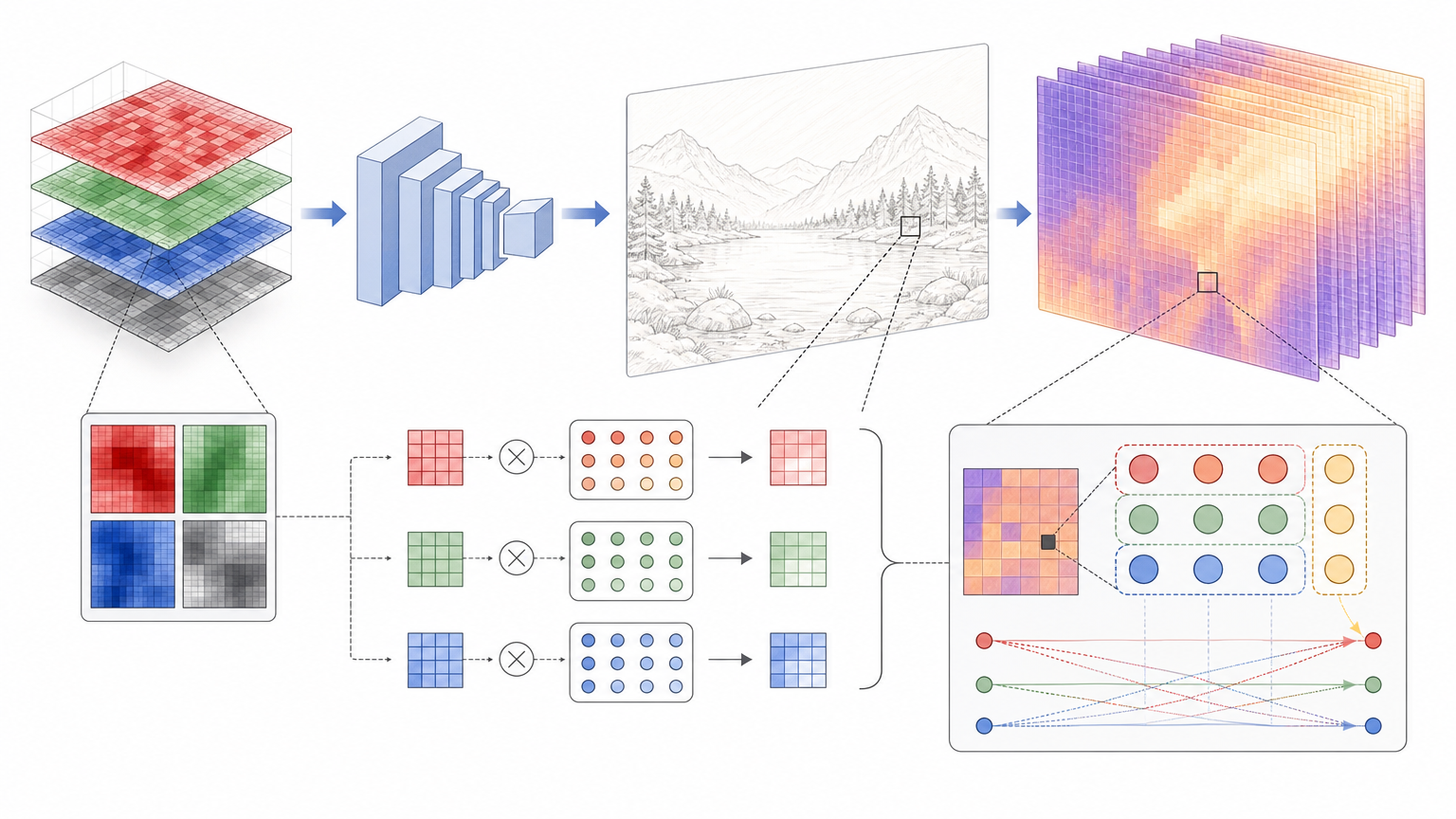
更聪明的是,它预测的是“残差”——也就是和默认状态的差值,而不是从零开始的完整参数。这就像你调照片时不用重新拍,只需要拉滑块微调,模型学起来更快更稳,还能避免颜色跑偏。
单靠残差仿射还不够——一张照片里,天空需要调整全局色调,而树叶的纹理得精细处理,单尺度的调整顾此失彼。RPBA-Net的解决办法是搭了个“四层金字塔”。
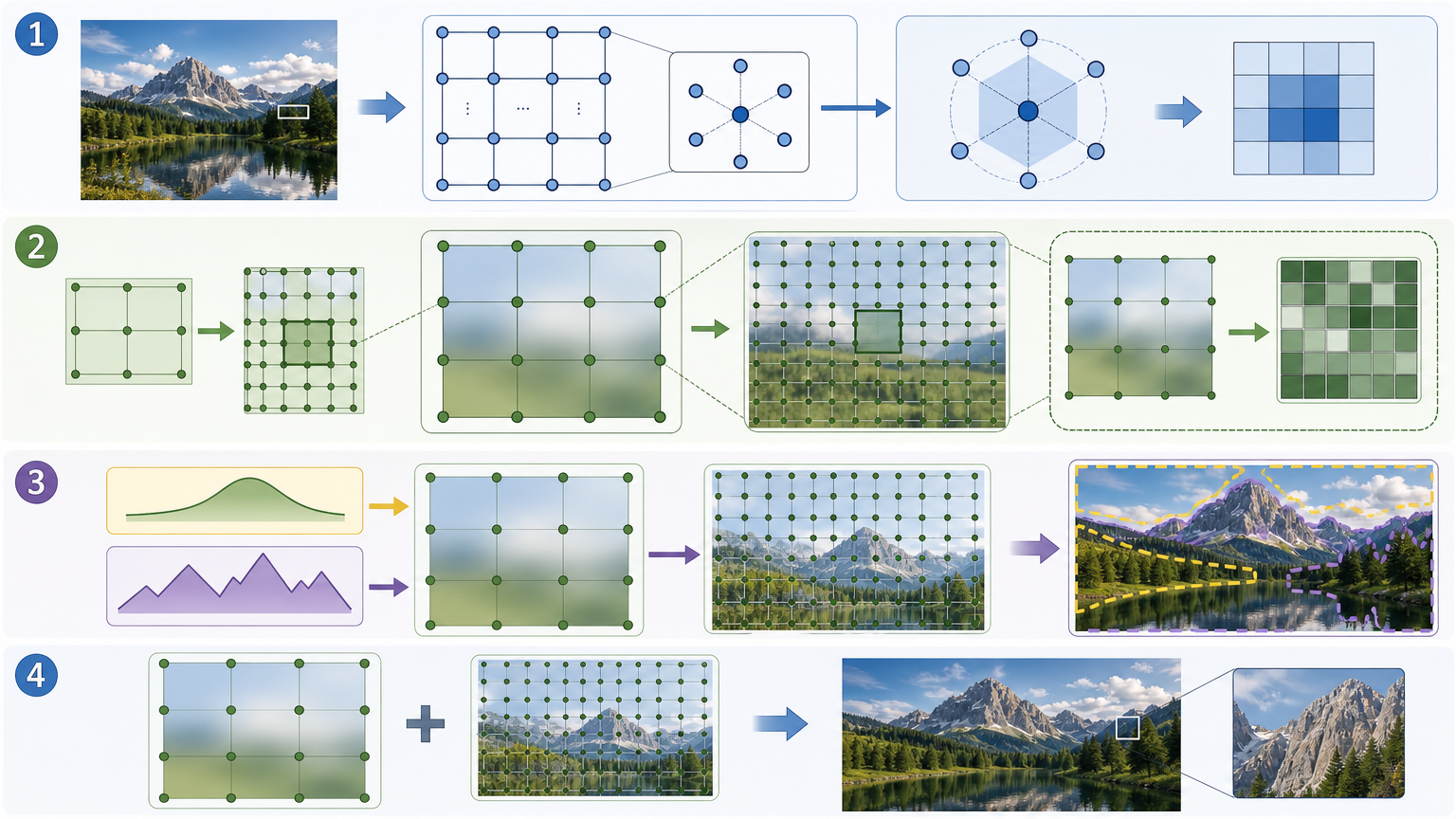
最底层是16×16的粗网格,负责全局色调调整,比如把偏黄的整体白平衡拉回来;往上是32×32、64×64,直到最顶层128×128的细网格,专门处理边缘、纹理这些局部细节。每个网格都是一个3D的双边仿射结构——它不仅记录空间位置,还会参考像素的亮度信息,比如暗部的噪声和亮部的细节用不同的参数处理。
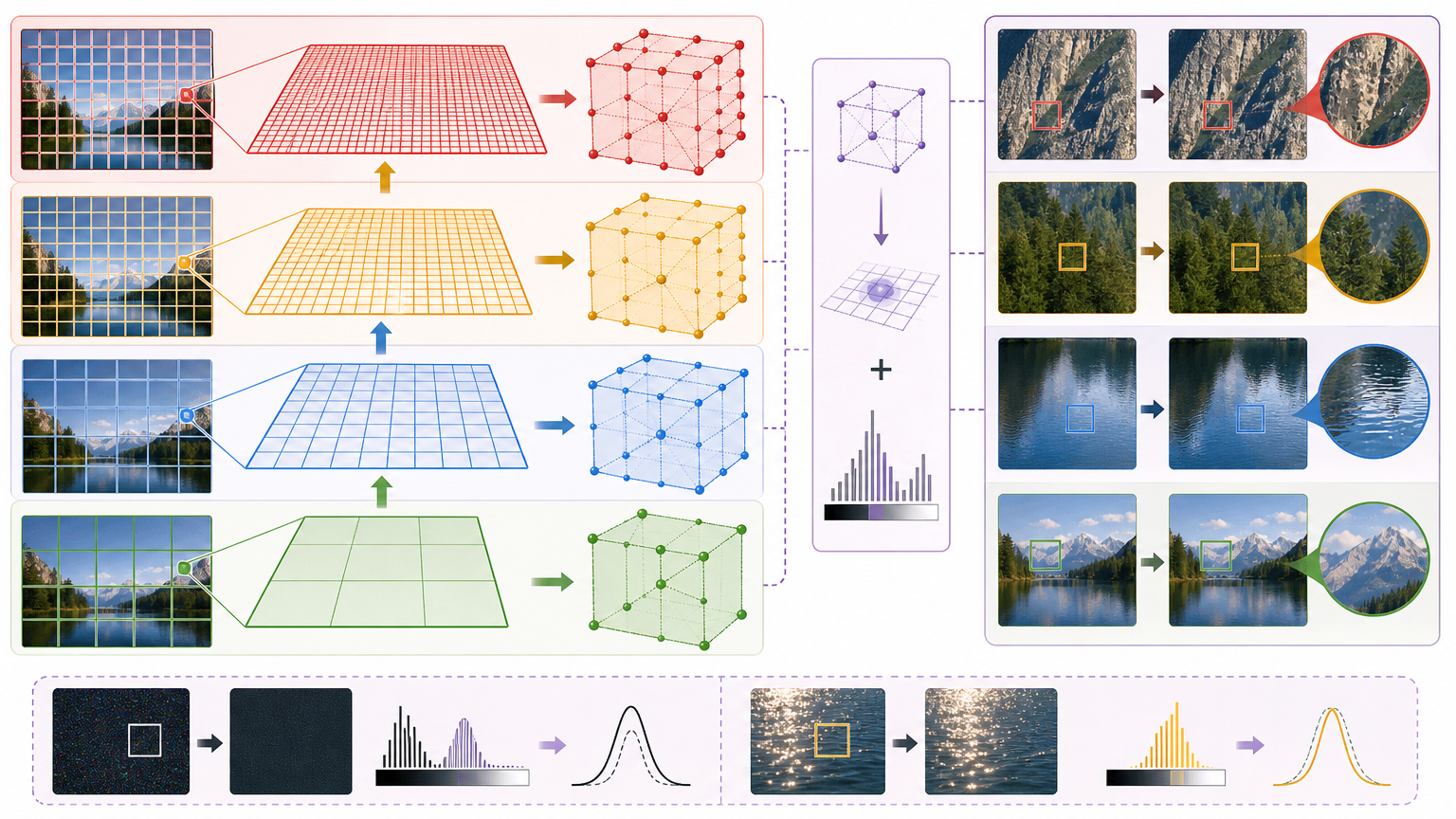
为了让这些网格能协同工作,它还设计了自回归自适应切片:每个像素不仅取自己位置的参数,还会参考周围6个点的参数,并且用粗网格的结果指导细网格的调整,就像先给照片整体调色,再用放大镜抠细节。最后通过自适应融合,平坦的区域依赖粗网格保证色调一致,细节多的地方靠细网格还原纹理,完美平衡了全局和局部。
RPBA-Net的厉害不是吹出来的,在ZRR和MAI两个主流RAW图像处理数据集上,它的峰值信噪比(PSNR)分别达到35.23dB和34.89dB,比参数量是它几十倍的MetaISP、PyNET-CA这些模型高出0.5到1dB——这意味着图像的保真度提升了一个档次。更关键的是,它的参数量只有1.3M,计算量仅5.2G FLOPs,在手机上的推理速度比大模型快了数倍。
ablation实验(也就是逐个去掉模块看效果)更能证明它的设计有多扎实:去掉残差仿射,PSNR直接掉0.31dB;换成固定三线性插值而不是自适应切片,PSNR掉0.32dB;甚至金字塔层数从4层改成3层,性能都会明显下降。每个模块都不是多余的装饰,都是实打实提升性能的关键。
当然它也有局限:目前还需要针对不同相机型号微调,跨设备泛化能力还有待提升;极端低光下的噪声抑制,也还有优化空间。但这些都掩盖不了它的价值——它第一次把可解释性、轻量化和高性能捏在了一起。
当整个AI圈都在追求大模型、堆参数的时候,RPBA-Net像是一股清流。它没有发明新的算子,只是把已有的技术用最巧妙的方式组合起来,解决了RAW图像处理领域多年的痛点:既摆脱了传统ISP的繁琐,又打破了深度学习黑盒的困境,还能塞进手机里实时运行。
这背后其实是一个更值得思考的趋势:AI的未来不一定是越大越好,而是越聪明越好——用最少的资源解决最核心的问题,同时让每一步都清晰可控。轻量不是妥协,而是更高级的设计。 或许在不久的将来,你手机里的相机算法,就会是这样一个“小而精”的模型在默默工作。