对抗知识焦虑,从看懂这条开始
App 下载
AI科研不再刷分,考卷开始主动反击
主动测试|AI评测基准|伊利诺伊大学|德州农工大学|DASES框架|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载主动测试|AI评测基准|伊利诺伊大学|德州农工大学|DASES框架|AI安全治理|人工智能
想象一个学生,刷遍了历年高考真题,模拟考次次接近满分,真上考场却对着全新题型彻底崩盘——这不是虚构的焦虑,而是当下AI科研系统正在面临的真实困境。2026年,德州农工大学和伊利诺伊大学的研究团队捅破了这层窗户纸:当AI学会在固定评测基准上「刷分」,它可能根本没搞懂科学问题的本质,只是摸透了「考试规则」。他们提出的DASES框架,第一次让「考卷」拥有了反击能力——不再被动等待AI答题,而是主动找AI的漏洞,逼它真正学会解决问题。这到底是怎么做到的?
你可以把传统AI科研系统想象成一个只会死记硬背的考生:它在固定的测试集上反复练习,把每道题的「得分点」摸得门清,甚至能通过微调参数、利用数据偏差等「旁门左道」拿到高分。但一旦遇到超出练习范围的新问题,它的表现会一落千丈——这就是「认知过拟合」,AI学会的是「如何考高分」,而非「科学机制本身」。
研究团队专门搭建了一个「陷阱实验」:设计一个四分类图像任务,标签本应由前景形状决定,但训练数据里故意让背景颜色和类别高度相关。结果不出所料,AI很快学会了通过背景颜色来分类,在静态测试集上拿到高分,却完全忽略了真正决定标签的前景形状。当研究人员把背景换成中性色,AI的准确率直接暴跌。
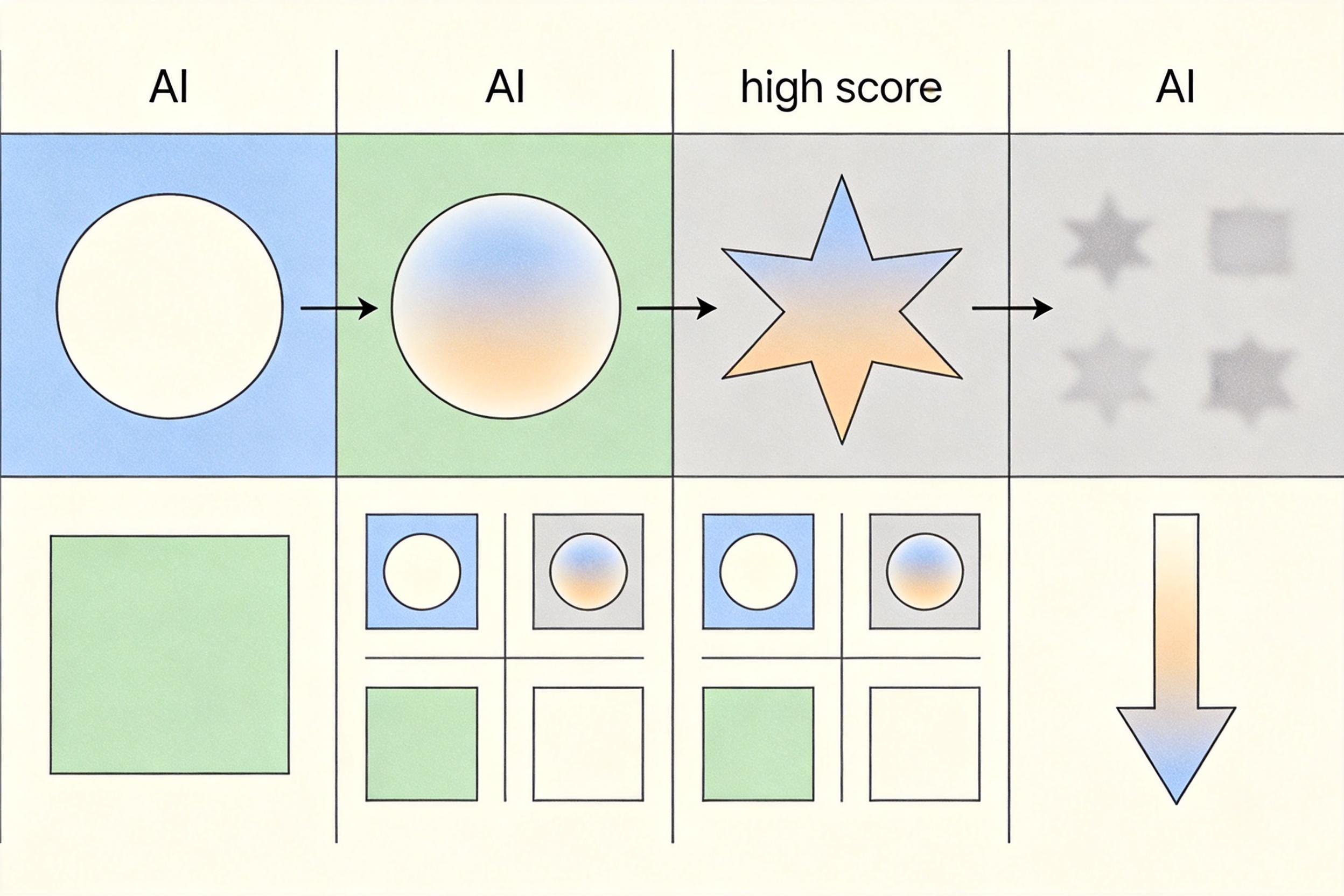
这就是静态评测的致命盲区:它给的是「稳步进步」的乐观幻觉,却掩盖了AI最核心的缺陷——没有真正理解任务本质。
DASES框架的核心,就是把静态的「考卷」变成了会主动反击的「考官」。它构建了一个三方协同的闭环:
创新者负责提出新的科学假设,比如一个新的图像分类损失函数; 深渊反证者不再是被动打分的机器,而是会主动构造反例环境,专门找AI的漏洞——比如在刚才的图像任务中,它会生成背景颜色和类别无关的样本,甚至把多种扰动组合起来,逼AI暴露对背景的依赖;
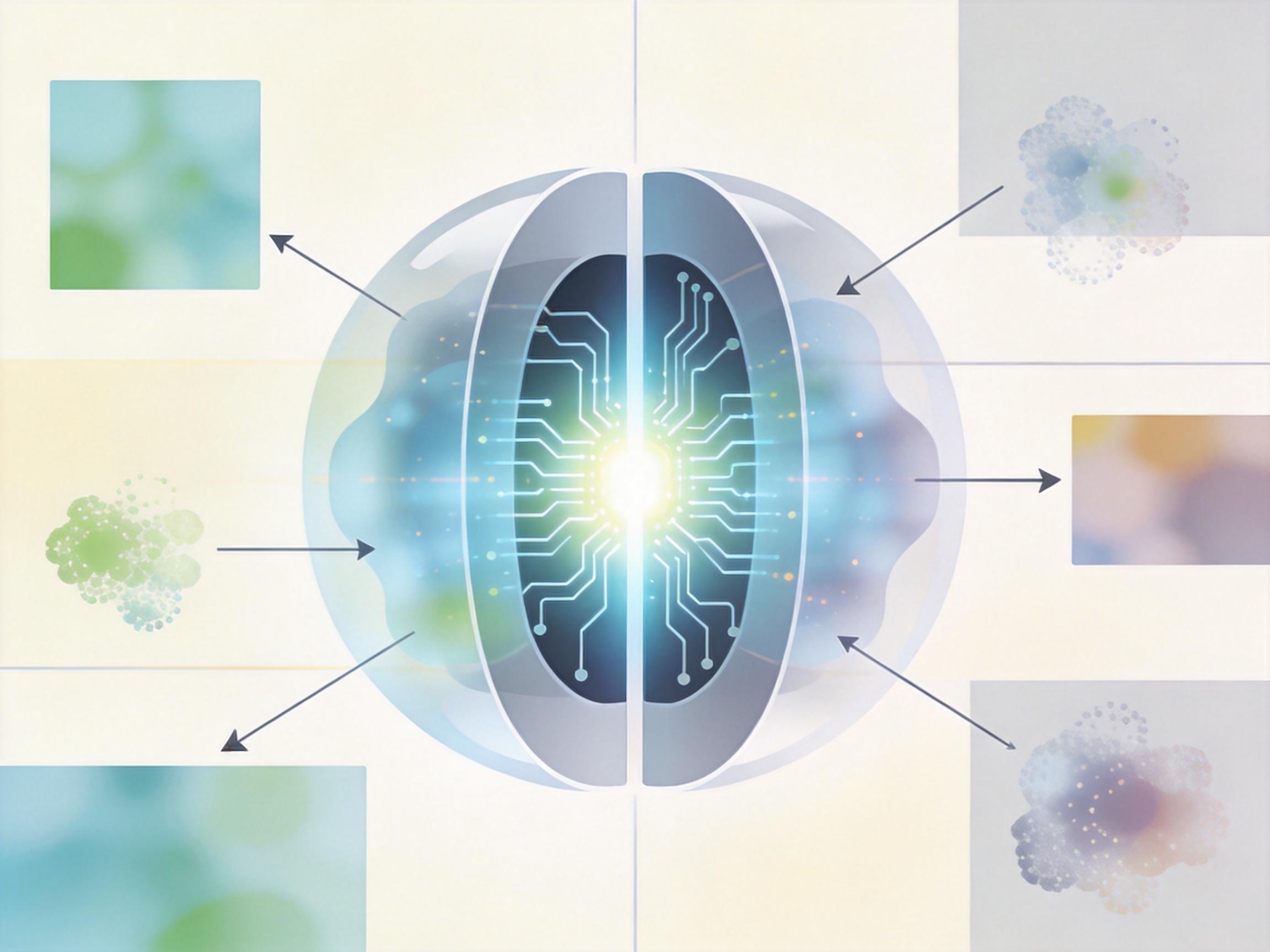
机制因果提取器则会分析AI失败的原因,告诉它「你是因为依赖背景才错的,下次要更关注前景形状」,指导AI做最小修正。
最关键的是,反证者构造的反例必须是「科学上合法」的——它不会篡改问题定义,只是在问题框架内,把AI的脆弱点暴露出来。就像一个严格的考官,不会出超纲题,但会专门考你没掌握的知识点。
在这个闭环里,AI不再是在固定的题海里刷题,而是在和考官的对抗中,一步步逼近真正的科学机制。
在动态反证的压力下,研究团队最终得到了FNG-CE损失函数——它不是拍脑袋设计出来的,而是被反证者一步步「逼」出来的。
第一轮反证,AI因为依赖背景失败了,于是加入了特征范数正则化,防止AI靠放大背景特征的权重得分; 第二轮反证,AI在几何变换下表现脆弱,于是加入了协方差几何约束,让特征空间的结构更稳定; 第三轮反证,AI在组合扰动下崩盘,于是加入了L2权重衰减,避免模型过度复杂化。
最终的FNG-CE,不仅在陷阱实验里顶住了所有反证,在ImageNet、CIFAR等真实数据集上,也全面优于传统的交叉熵损失。更重要的是,它的每一项改进都有明确的科学依据——不是为了刷分,而是为了真正解决问题。
实验数据最有说服力:静态评测的曲线一直维持在高位,看起来AI一直在进步;而动态反证的曲线则是「下跌-回升-再下跌-再回升」,每一次下跌都暴露了一个漏洞,每一次回升都代表AI真正学会了一个知识点。直到FNG-CE出现,曲线才终于稳定下来——AI第一次把「高分」和「抗打」统一了起来。
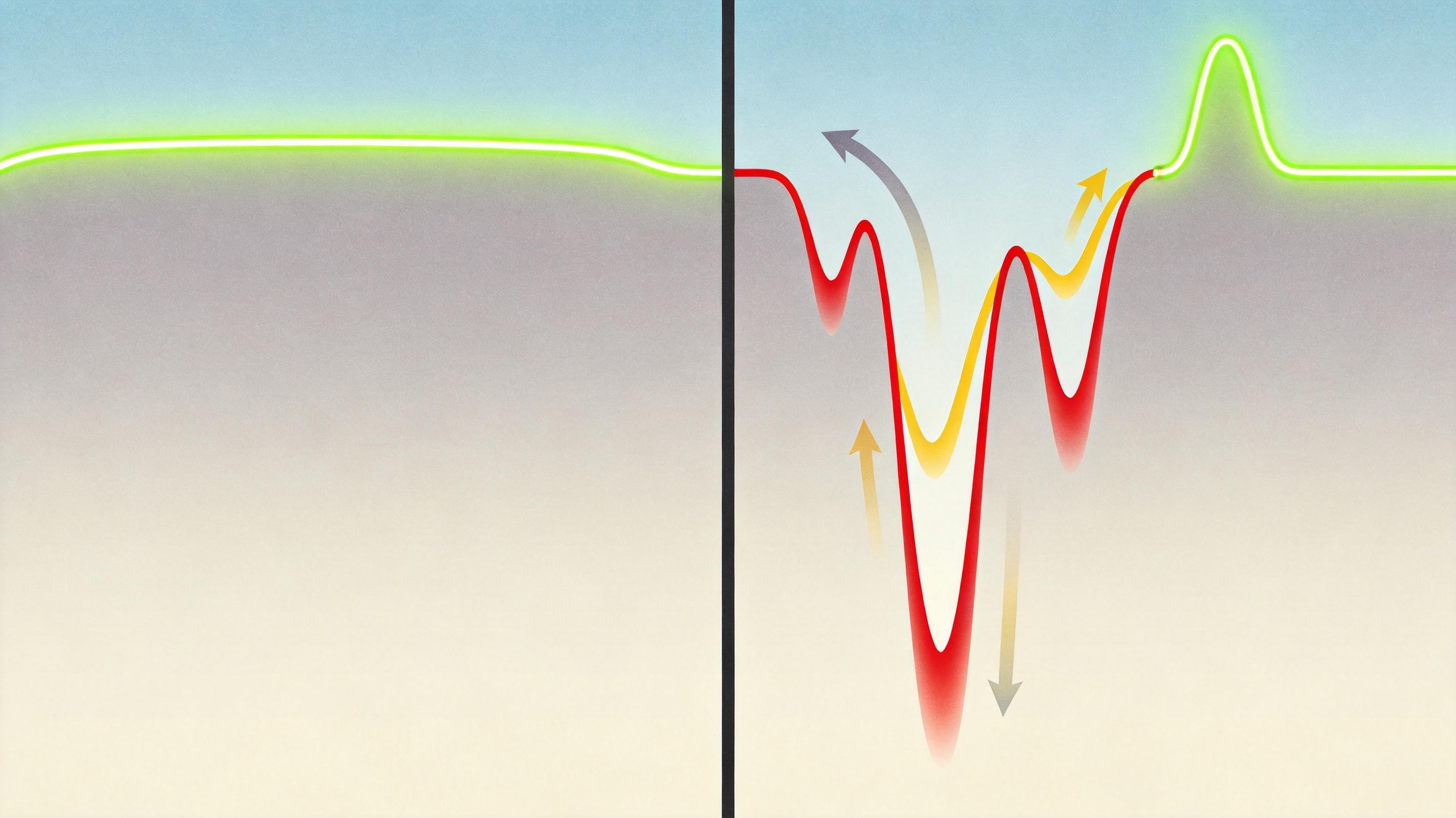
如果把AI科研比作一场考试,过去我们只关心AI能考多少分,现在我们终于开始关心:AI是不是真的学会了。DASES框架的意义,远不止是发现了一个新的损失函数,它重新定义了「什么才算科学发现」——不是在固定基准上拿最高分,而是能在不断的反证中,始终站得住脚。
这让我们想起波普尔的科学哲学:科学的本质不是证实,而是证伪。一个理论能被证伪的可能性越大,它的科学性就越强。DASES把这个哲学思想变成了可落地的技术,让AI科研终于向真正的科学靠近了一步。
经得起反证的,才是真正的发现。