对抗知识焦虑,从看懂这条开始
App 下载
AI推理卡壳?HBF给存储体系搭了个新书架
内存墙|存储厂商|AI推理|HBM内存|HBF解决方案|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载内存墙|存储厂商|AI推理|HBM内存|HBF解决方案|AI算力|人工智能
当你用AI生成万字调研报告时,有没有想过它背后的“数据仓库”正面临崩溃?现在的大语言模型动辄千亿参数,推理时要调用的缓存数据能装满几十台家用电脑,但负责高速运算的GPU,却只能靠巴掌大的HBM内存临时存放数据——就像给图书馆配了个只能放两本书的前台。2026年4月,一家存储厂商的股价在一年里涨了29倍,还挤掉了SaaS巨头加入纳斯达克100,只因为它拿出了一个叫HBF的解决方案。为什么一块闪存能搅动AI产业的神经?这得从AI最痛的“内存墙”说起。
你可以把HBM和HBF的关系,理解成家里的书房和城市图书馆。HBM是书房,书架不大但伸手就能拿到书,适合放常用的工具书——对应AI推理中需要高速调用的实时数据,延迟只有纳秒级,但单块最大容量也就64GB,不够放一本大部头的百科全书。 而HBF就是图书馆,用3D NAND闪存堆叠出512GB甚至4TB的容量,相当于把几十层书架叠起来,能装下上百本百科全书。它借鉴了HBM的TSV硅通孔技术,把十几层NAND芯片垂直焊在一起,再用CMOS直接键合技术缩短信号路径,让数据能像电梯一样在各层间高速传输,读带宽最高能到3.2TB/s,接近HBM的水平。
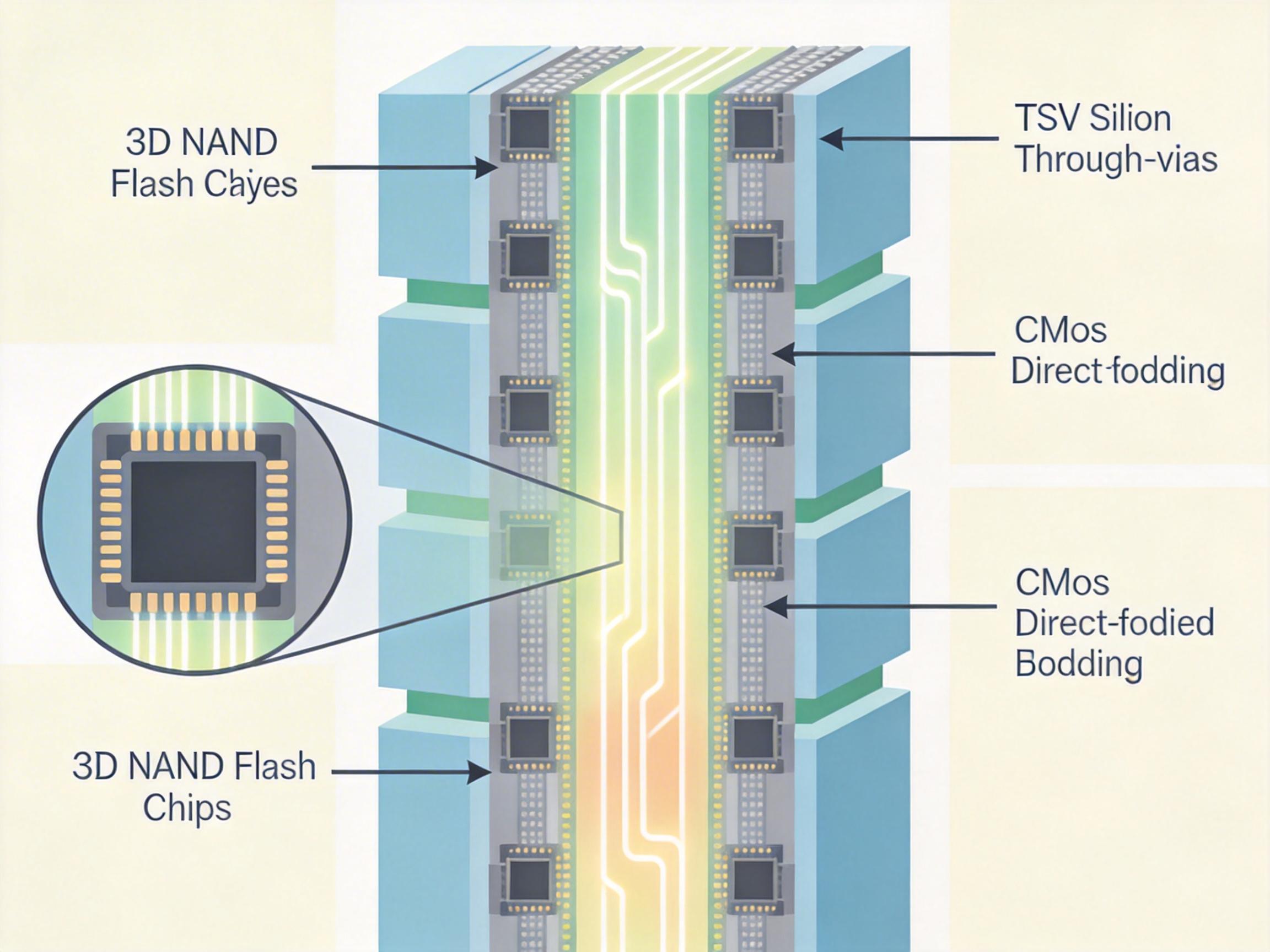
但真实的机制比这个类比更精确:HBF把传统NAND闪存拆成了上千个独立的子阵列,每个子阵列都能同时读写——就像图书馆里所有阅览室同时开门,读者不用排队就能取书。这种并行架构直接突破了传统NAND单通道的带宽瓶颈,让它既能装下海量的AI模型权重,又能快速调出数据给GPU运算。
过去AI产业的注意力全在GPU的算力上,直到人们发现,就算GPU能每秒算1000亿次,要是数据从硬盘传到内存要等上几毫秒,算力再强也得闲置——这就是“内存墙”。HBM虽然快,但太贵了,一块64GB的HBM成本能买10块同容量的NAND闪存,根本没法大规模部署。 HBF的出现,给AI存储搭了个“三层书架”:最上层是HBM,放常用的实时KV缓存;中间层是HBF,放需要经常调用但不用秒级响应的模型权重和历史缓存;最下层是传统SSD,放很少用到的冷数据。SK海力士的测试显示,这种混合架构能让AI推理的性能功耗比提升2.69倍,还能处理18.8倍的并发请求——相当于原来需要32台GPU完成的任务,现在2台就能搞定。
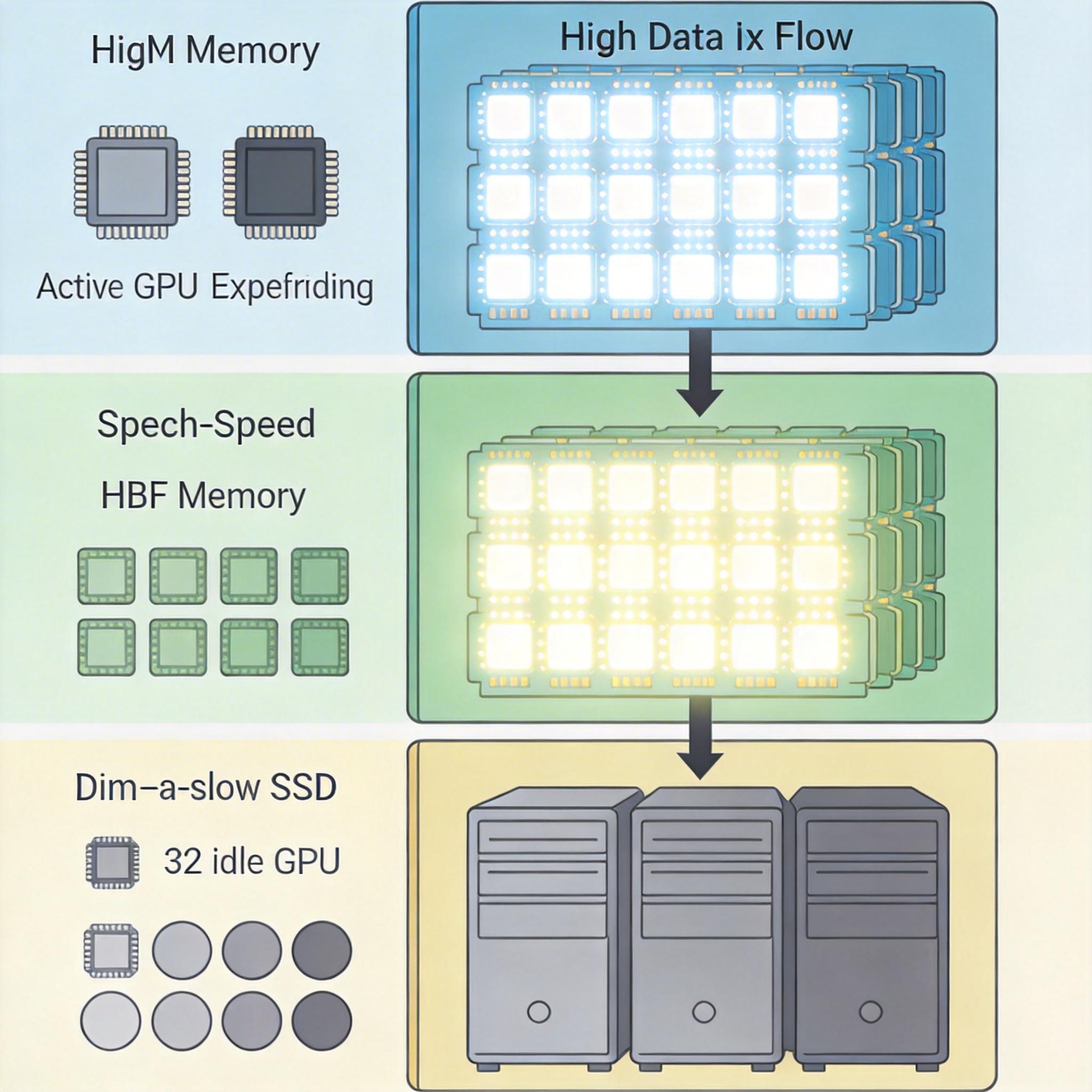
不过HBF也有短板:它的写入寿命只有10万次,延迟是微秒级,比HBM慢了一个数量级。就像图书馆不能随时改书里的内容,它更适合读密集型的AI推理场景,而不是需要频繁写入的训练场景。这也决定了它不会取代HBM,而是成为HBM的“容量扩展器”。
要让HBF真正走进数据中心,光有技术还不够——得让所有GPU、服务器都能用上这个“图书馆”。2026年2月,闪迪和SK海力士联合发起了HBF标准化联盟,在开放计算项目的框架下制定统一规格。这就像给图书馆制定了统一的图书编码和借阅系统,不管是哪家出版社的书,都能放进这个书架,不管是哪家的GPU,都能快速取书。 这种标准化的好处很直接:HBF可以复用HBM的生产线和供应链,量产速度比HBM快得多,成本也能降下来。按照计划,2026年下半年就能拿出样品,2027年就能用到AI推理设备上——比原计划提前了6个月。但它也面临挑战:如果GPU厂商不支持HBF的接口标准,这个“图书馆”就只能空着;如果写入寿命的问题得不到解决,它也只能存放只读数据,没法承担更复杂的任务。
当我们谈论AI的未来时,总是在说更大的模型、更快的算力,却很少注意到那些默默支撑数据流动的存储技术。HBF的出现,本质上是给AI的“大脑”扩容了“记忆仓库”——它不用取代谁,只需要填补那个被忽略的空白。 容量决定边界,带宽决定速度。这句话不仅适用于HBF,也适用于整个AI产业:当我们能装下更大的模型,能更快地调用数据,AI才能真正从实验室走进更多的应用场景。也许再过几年,当你用AI实时翻译一场直播、用AI设计一座大楼时,不会想到背后有一个堆叠了十几层的闪存阵列在高速运转,但它确实在那里,悄悄拓宽着AI的边界。