对抗知识焦虑,从看懂这条开始
App 下载
AI终于能画出同一个世界的不同视角了
视角一致性|视频生成模型|叶德珩团队|林国省|IC-World|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载视角一致性|视频生成模型|叶德珩团队|林国省|IC-World|多模态视觉|人工智能
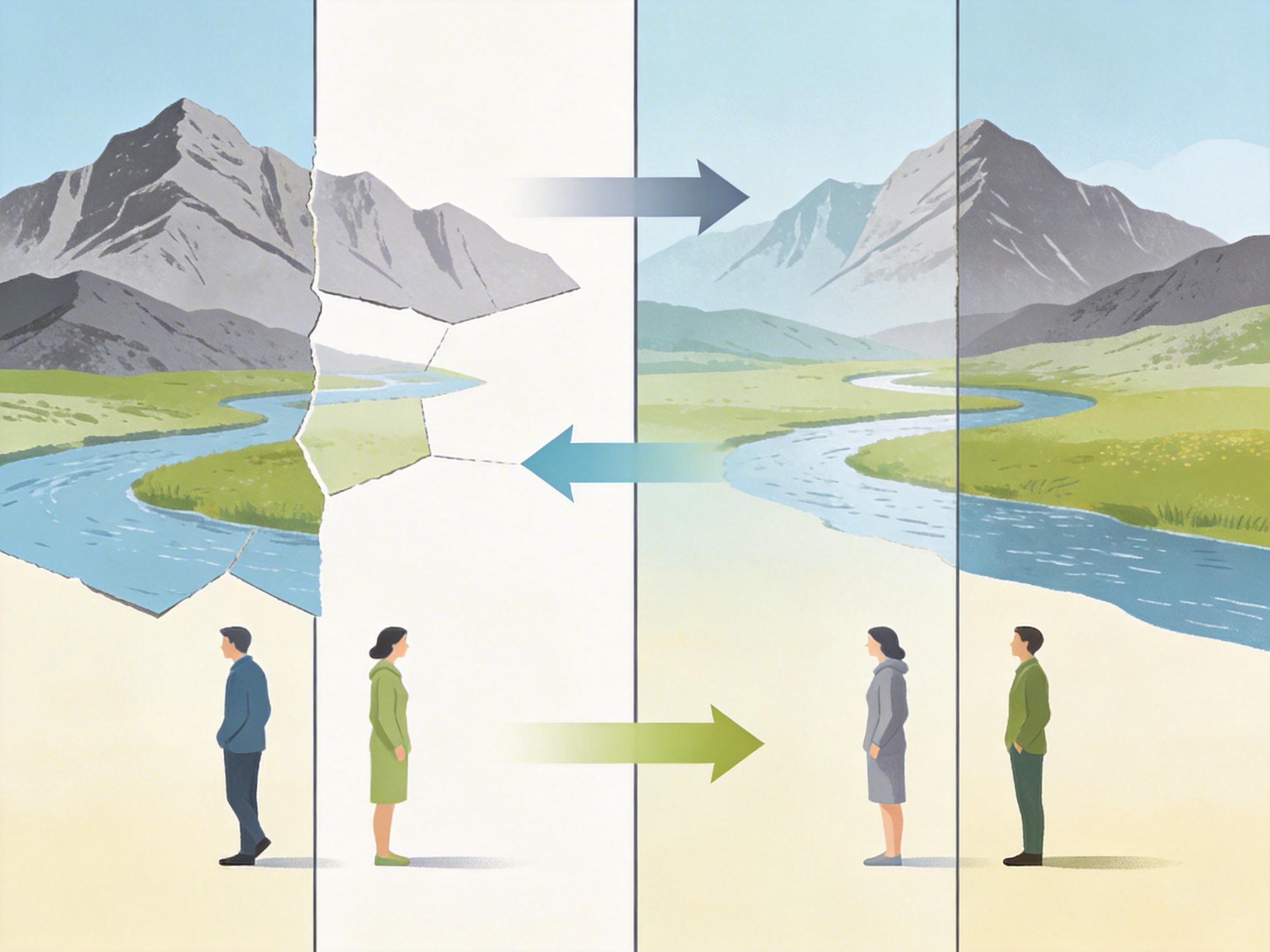
想象一下:两个机器人在同个房间搬苹果,一个看见苹果在左桌,另一个却看见它在右桌——这场协作注定是灾难。或是你和朋友联机玩游戏,你视角里门口的招牌是“便利店”,他屏幕上却变成了“咖啡店”,沉浸式体验瞬间碎成渣。
过去,AI生成视频时就犯着这种“精神分裂”的毛病:给它同个世界的不同视角图,它生成的视频永远是各说各话——场景对不上、人物飘来飘去、前一秒出现的东西下一秒凭空消失。直到林国省与叶德珩团队的IC-World出现,AI第一次学会了“画同一个世界”。
你可以把传统AI视频生成模型想象成一群各画各的画家——每个画家只拿到一张局部风景照,各自埋头创作,最后拼起来的画要么山在这边河在那边,要么人物动作完全对不上。这不是画家不用心,是从一开始就没给它看完整的世界。
IC-World的核心破局点,是**上下文生成(In-Context Generation)**——把同个世界的不同视角图像拼拼图一样合成一张大图,再配上一句明确的指令,比如“这是同一个客厅的三个视角,生成10秒视频”,让AI一次性生成一整版“全景视频”,最后再拆成各个视角的单独视频。
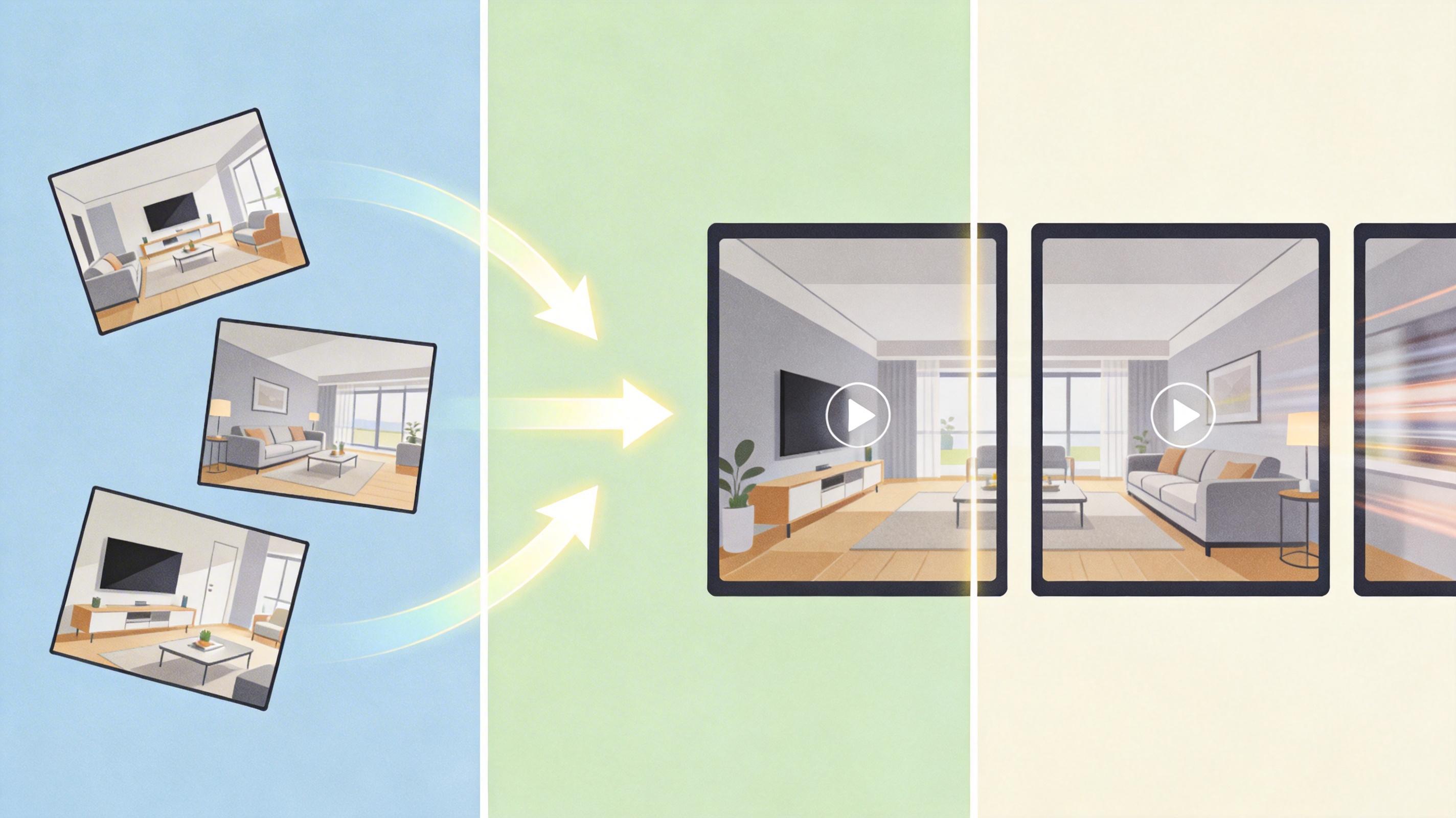
这相当于给了AI一张完整的世界地图,而不是零散的碎片。它不用再靠猜测补全信息,从生成的第一步起,所有视角就被绑定在同一个时空里。更妙的是,这种并行生成方式让速度比传统方法快了好几倍——不用等一个视角生成完再做下一个,一次就能搞定所有。
光靠拼图输入还不够,AI偶尔还是会犯点小错:比如某个视角里的沙发腿少了一根,或者人物抬手的动作慢了半拍。这时候就需要强化学习出场,给AI当“老师改作业”。
团队用了基于GRPO的强化学习策略,专门设计了两个“评分标准”:几何一致性奖励模型和动态一致性奖励模型。前者负责检查空间结构对不对——比如用3D重建模型把生成的视频转成点云,再对比不同视角的点云是否对齐,对齐得越准,奖励越高;后者盯着动态动作——比如跟踪人物的抬手轨迹,不同视角里的动作路径必须完全同步,差一点就扣分。
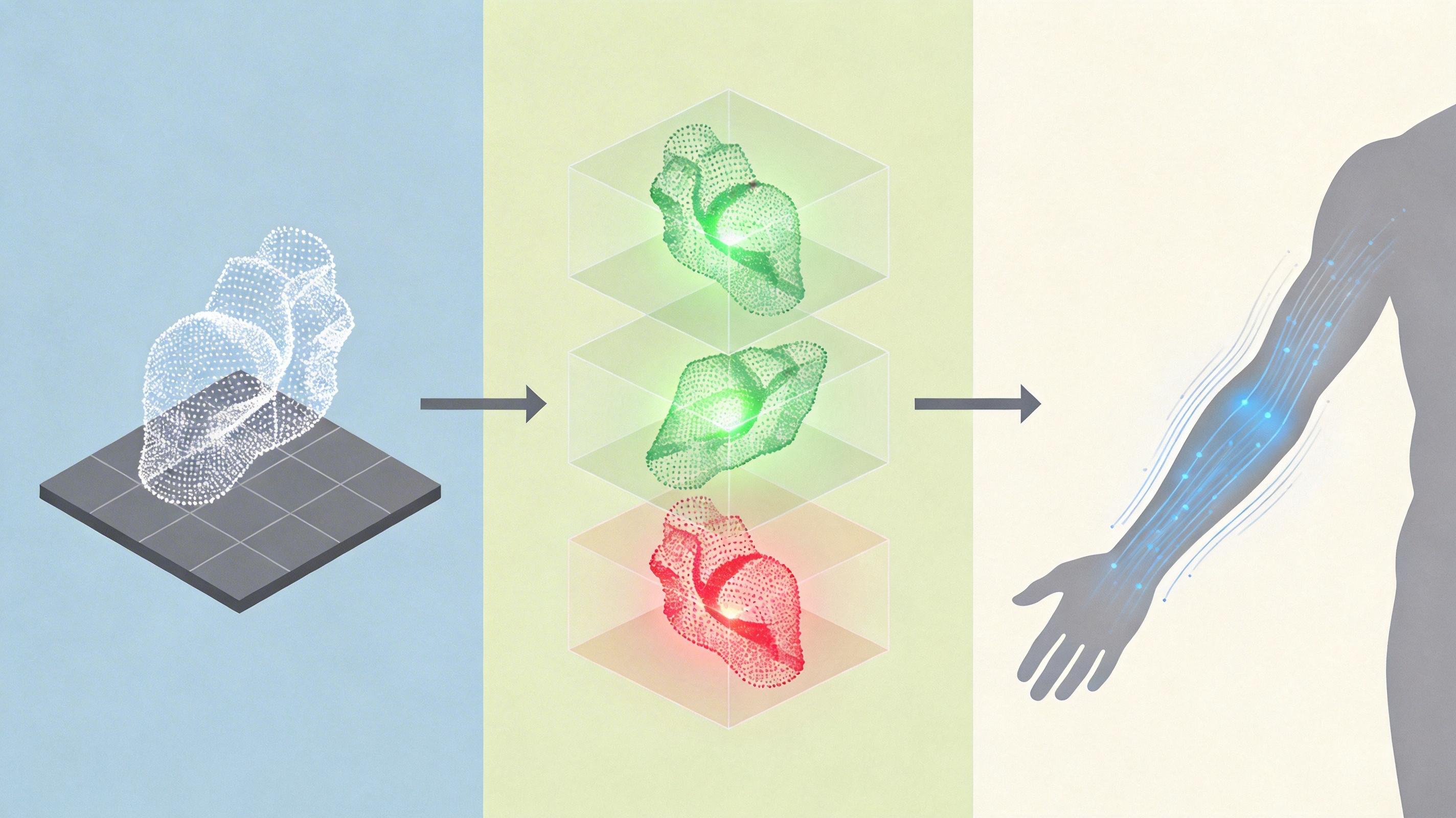
AI每生成一批视频,就会拿到这两个评分,得分高的生成方式会被强化,得分低的就被淘汰。就像反复刷题改错题,AI慢慢学会了把每个细节都对齐:沙发在所有视角里都是四条腿,人物抬手的瞬间在每个画面里都分毫不差。实验数据显示,这套机制让IC-World在一致性指标上全面超过了现有方法,而且视频的视觉质量没打折扣。
IC-World的出现,不只是解决了一个技术难题,更标志着AI视频生成正在从“画孤立碎片”进入“建共享世界”的新阶段——几乎在同一时间,Saining Xie团队也发布了思路相似的Solaris,这不是巧合,是行业走到拐点的信号。
现在,这套技术已经能在两个关键场景里发挥作用:一是多机器人协作,机械臂终于能对“苹果在左桌”这件事达成共识;二是多人游戏,所有玩家看到的终于同一张地图。但它的潜力远不止于此:未来的VR聚会里,你和异地的朋友能在同一个虚拟客厅碰杯,每个视角里的杯子位置都分毫不差;影视制作能一次性生成同一场景的所有机位画面,不用再反复调整补拍。
当然,它也有局限:目前还只能处理较短的视频,长时序的动态一致性还有待提升,而且训练和推理需要的计算资源依然不菲。但不可否认的是,AI第一次摸到了“理解真实世界”的门槛——它不再是画几张漂亮的图,而是在构建一个能自洽运转的虚拟空间。
当AI能画出同一个世界的不同视角时,它其实完成了一次认知升级:从“看见局部”到“理解全局”。这就像人类婴儿第一次意识到,躲在沙发后面的玩具并没有消失——AI终于拥有了“世界持续性”的认知。
看见同一世界,才是AI理解真实的开始。
未来的AI不会再是各说各话的“分裂者”,它会成为能和人类、和同类共享同一认知的“合作者”。而IC-World,就是这场认知革命的第一块拼图。