内容由AI生成,思考得你完成
App 下载
内容由AI生成,思考得你完成
App 下载上课铃响的瞬间,教室角落的摄像头和麦克风阵列自动启动,没有刺眼的指示灯,也没有突兀的提示音——这不是在拍公开课,而是AI在默默记录课堂的每一个细节。45分钟后下课铃落,一份标注着「提问时长占比12%」「学生互动峰值在第27分钟」的报告已经躺在教师的工作台上,甚至连「某知识点重复讲解3次仍有学生困惑」的细节都被精准标出。这不是科幻片里的未来教室,而是如今国内近一半中小学正在发生的日常。支撑这一切的,是藏在教室大屏背后的「通专融合」AI架构——一种让通用AI能力落地教育场景的技术方案。
你可以把这套架构想象成「AI翻译官+教育专家」的组合:通用大模型负责听懂教师的提问、识别学生的发言,就像一个能精准处理各种语言的翻译;而教育垂域模型则像深耕课堂十年的老教师,能立刻判断「这个知识点学生是否真的掌握」「刚才的互动是否有效」。
但真实的机制比这更精确:通用大模型提供基础的语言理解和推理能力,处理语音转文字、语义分析等通用任务;教育垂域模型则是用2200亿token的教材、教案、课件数据训练出来的「课堂专家」,专门识别教学场景里的特殊行为——比如区分教师的「提问」和「讲解」,判断学生的「讨论」和「闲聊」。两者在教室本地的边缘计算单元里协同工作,数据不用上传云端,延迟能控制在50毫秒以内,既保证了实时性,也守住了学生的隐私。
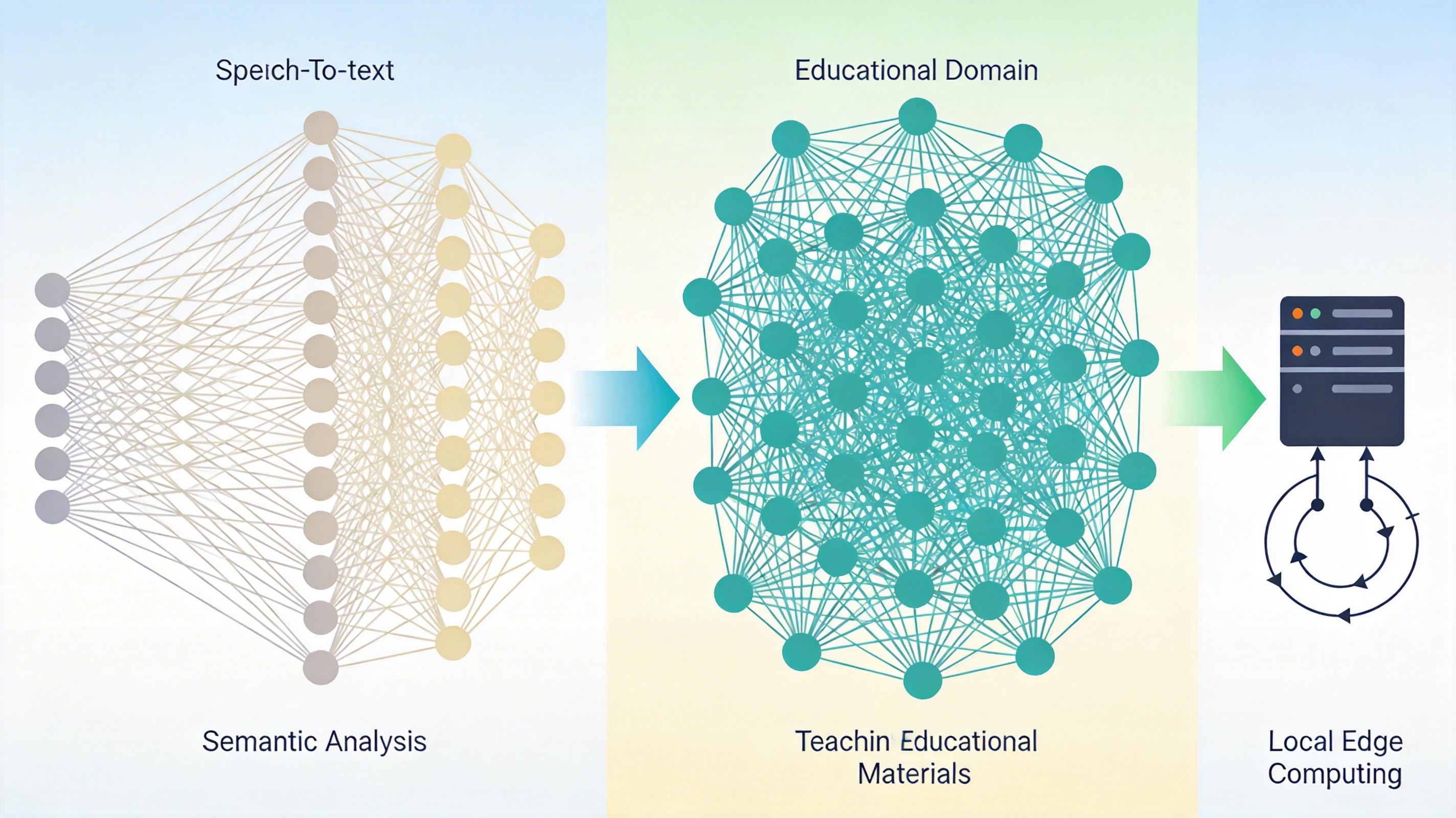
这种架构解决了一个核心难题:通用AI懂语言但不懂教育,而纯教育AI又缺乏灵活的交互能力。通专融合之后,AI终于能像真正的教学助手一样,既听得懂人话,又看得懂课堂。
把这套AI系统从实验室搬进教室,远不止装个摄像头那么简单。第一道坎是「边缘计算的资源瓶颈」——教室大屏的硬件资源远不如云端服务器,要在有限的算力里同时跑通两个模型,就得把AI模型「瘦身后」再部署,比如把通用大模型的参数从几百亿压缩到几亿,同时保留核心的语言理解能力。
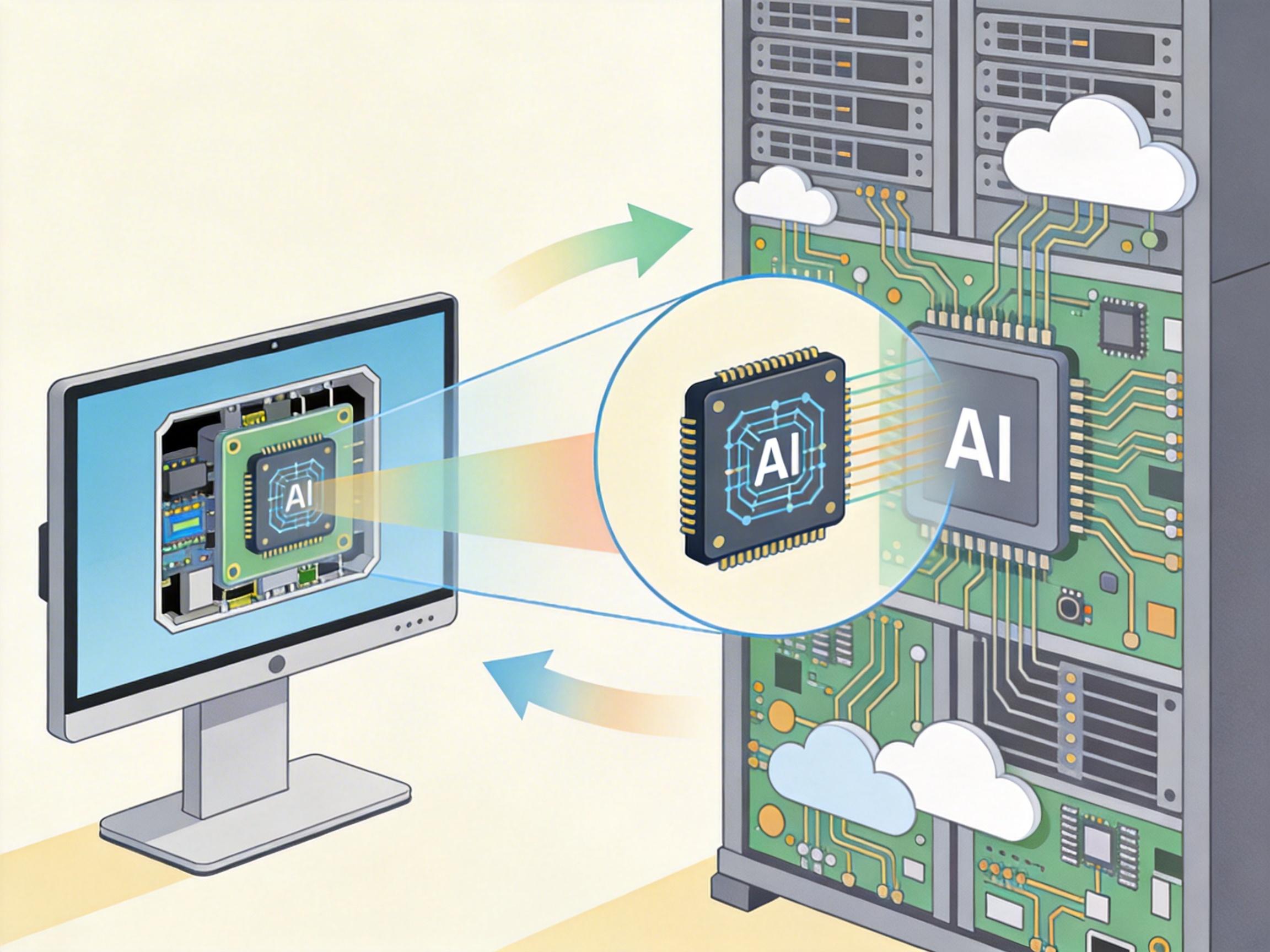
第二道坎是「数据隐私的红线」。教育数据涉及未成年人的行为、发言甚至情绪,绝对不能上传云端处理。技术团队只能把所有分析都放在本地设备完成,相当于给每个教室都配了一个迷你数据中心,数据从产生到销毁都不出校门。这也意味着,AI模型的训练和优化都得在本地完成,不能像云端AI那样随时更新,得用「联邦学习」的方式——多个教室的模型各自学习,只上传优化参数而不分享原始数据。
第三道坎是「教师的接受度」。不少老师一开始把AI系统当成「监控工具」,担心自己的教学行为被打分。技术团队不得不调整系统的反馈逻辑:报告里只说「某环节学生互动率较低」,而不是「教师此处教学方法有误」;只给改进建议,而不是直接打分。直到有老师发现,系统指出的「板书停留时间过长」确实是自己没注意到的问题,才慢慢放下戒心。
现在的AI课堂系统,已经能做到的远不止生成反馈报告。课前,它能根据教师的教学目标自动生成教案和课件,甚至推荐适合的互动小游戏;课中,它能实时识别学生的举手动作,自动切换到对应的学生机位;课后,它能根据课堂数据给学生推送个性化的练习题。
但它也有自己的边界:AI能识别学生的面部表情,但判断不了学生是「认真思考」还是「走神发呆」;能统计提问的次数,但判断不了问题的质量。有老师做过测试,AI把一个学生「托着下巴看窗外」的动作识别为「注意力不集中」,但实际上那个学生是在思考老师刚才提出的问题——这种微妙的情绪和语境,只有人类教师能读懂。
教育心理学家做过一个调查:75%的教师认为AI能提升教学效率,但87%的教师强调,AI永远不能替代师生之间的情感互动。比如当学生回答错误时,AI只能给出标准答案,而教师能拍拍学生的肩膀说「没关系,再想想」——这才是教育最核心的温度。
当我们谈论AI与教育的融合时,很容易陷入「技术万能」的误区,觉得只要装了AI大屏,就能立刻提升教学质量。但真实的课堂从来不是冰冷的数据集合,而是充满温度的互动场——是教师的一个眼神,是学生的一次举手,是那些AI永远无法精准量化的瞬间。
技术是助手,人才是教育的核心。未来的智能教室,不会是AI主导的「无人课堂」,而是人机协同的「高效课堂」:AI负责处理数据、提供建议,教师负责把握节奏、传递温度。就像现在的课堂一样,AI在后台默默工作,而真正的主角,永远是站在讲台上的教师,和坐在课桌前的学生。