对抗知识焦虑,从看懂这条开始
App 下载
Claude跑分暴跌40分,编程AI评测换了新标尺
Sonnet 4.5|编程能力评测|SWE-Bench|CursorBench|Claude 4.5|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载Sonnet 4.5|编程能力评测|SWE-Bench|CursorBench|Claude 4.5|大语言模型|人工智能
在编程AI圈叱咤风云的Claude 4.5系列,最近遭遇了一场滑铁卢:在老牌评测基准SWE-Bench上还能拿到77分的Sonnet 4.5,换了新基准CursorBench后,分数直接跌到37.9,近乎腰斩。Haiku 4.5更惨,从73.3分暴跌到29.4分。
这不是模型突然退化,而是一场针对「AI编程能力」的重新定义。过去我们只问「AI能不能写出对的代码」,现在要问的是「AI能不能像真实开发者那样,高效写出能用的代码」。CursorBench的出现,正是把这个行业默认的潜规则,变成了明明白白的评测标尺。
要理解Claude的分数暴跌,得先搞懂旧评测基准的bug。以SWE-Bench为例,它的核心是让AI修复GitHub上的现成bug——给一段有问题的代码,让AI输出补丁,能通过项目测试就算满分。
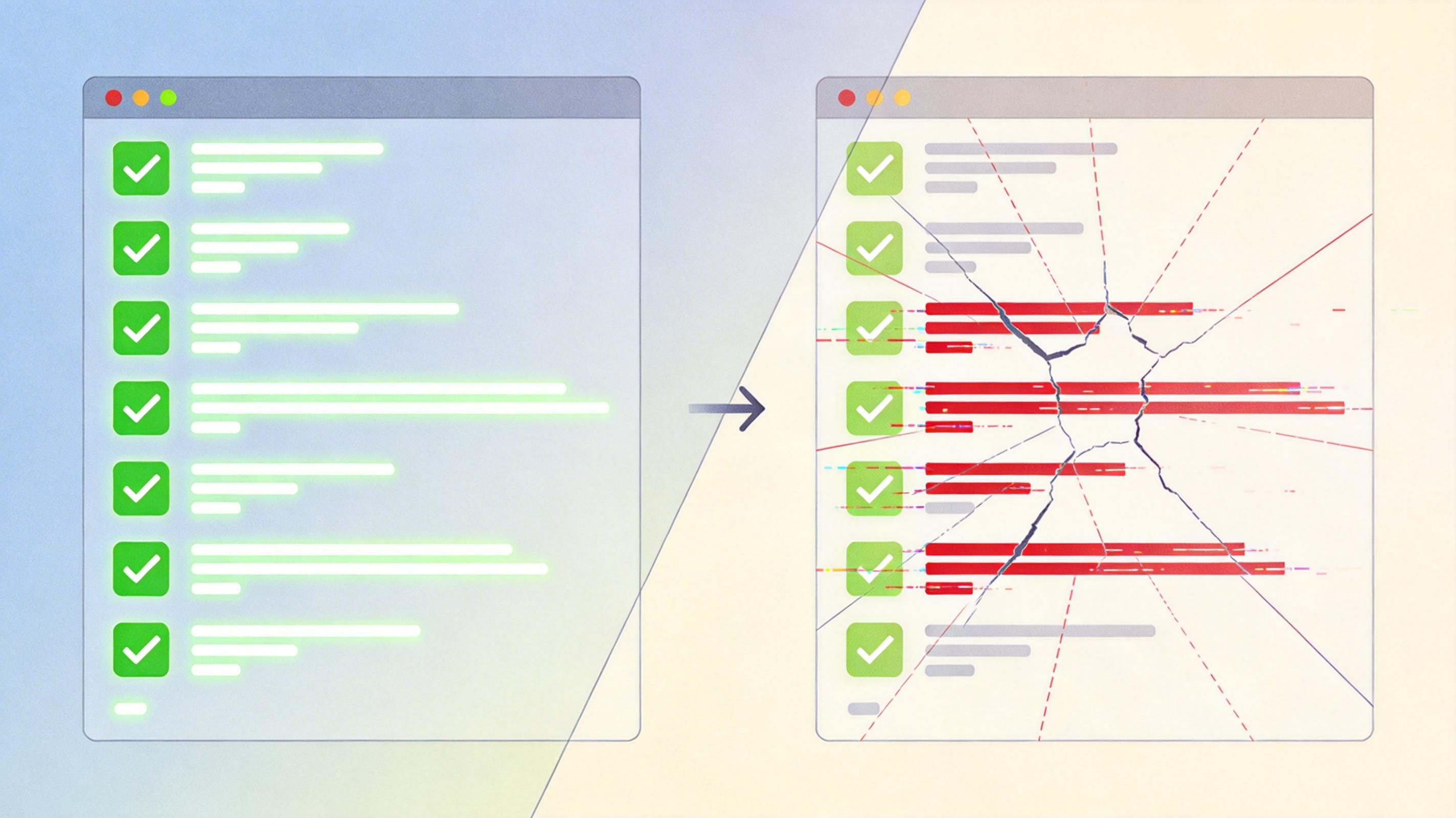
但真实的开发场景根本不是这样:没有现成的bug描述,只有模糊的需求;不是改几行代码,而是要跨文件调整架构;不仅要代码能跑,还要符合团队的编码规范,能被后续维护。更关键的是,开发者要的是「高效」——没人愿意等AI生成一堆冗余代码,再花时间手动精简。
旧基准的另一个死穴是数据污染。SWE-Bench的所有任务都来自公开GitHub仓库,前沿模型在训练时早就「见过」这些题目和标准答案,高分更像是「默写」而非「解决问题」。OpenAI曾发现,SWE-Bench里27.6%的测试用例有缺陷,59.4%的正确修复会被误判,这样的评测结果,早已和真实开发能力脱钩。
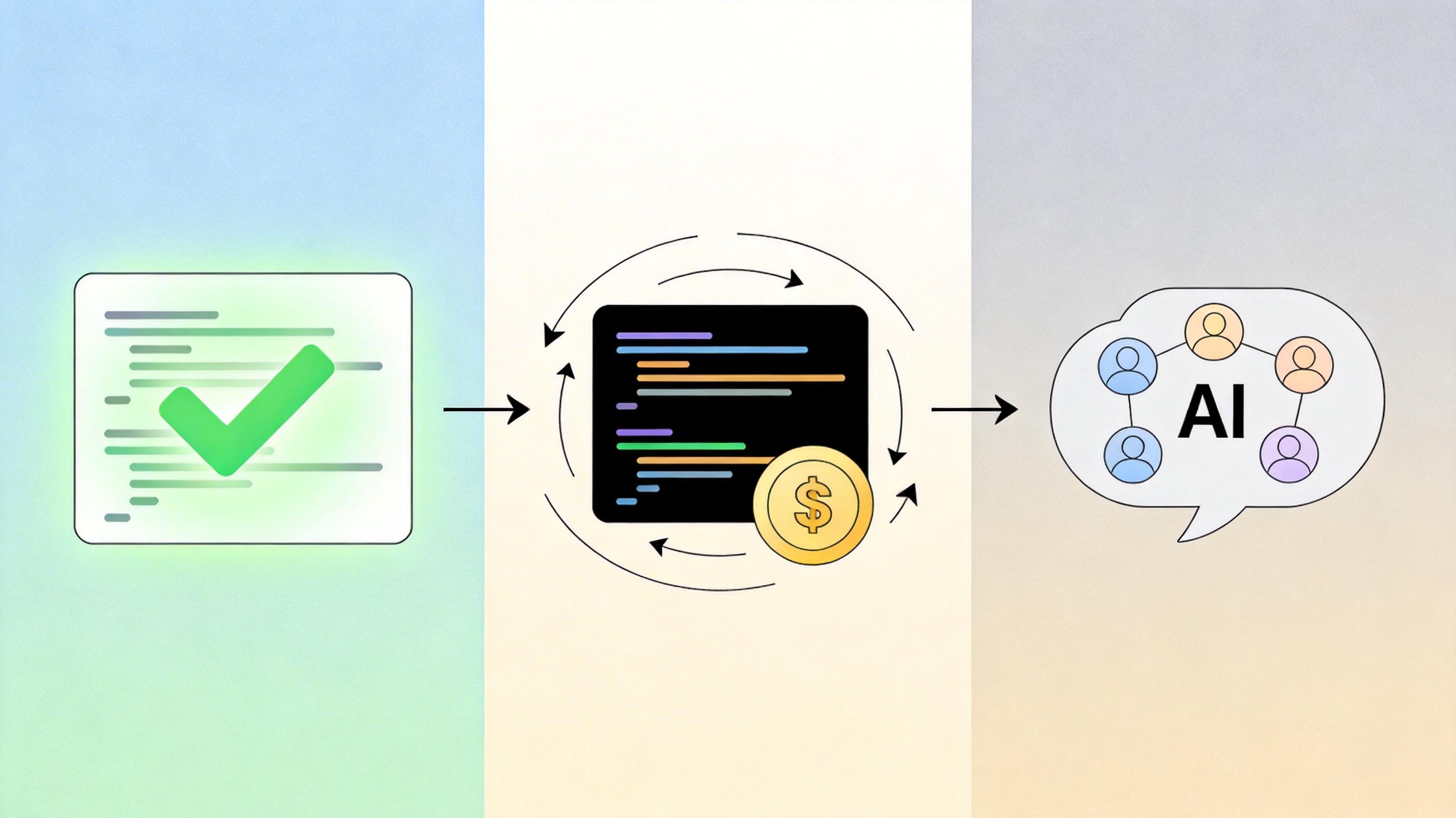
CursorBench的破局之道,是把评测的根基从「模拟任务」换成了「真实开发」。它的所有任务都来自Cursor平台的真实用户请求——比如「给这个电商系统加一个优惠券叠加逻辑」「优化这个数据接口的响应速度」,甚至是「帮我排查生产环境的日志报错」。这些任务没有标准答案,只有「能不能解决问题,以及解决得够不够好」。
它的评分体系直接对应开发者的核心需求:正确性只是基础,还要看代码质量(可读性、规范性)、效率(运行速度、token消耗),甚至是交互行为——比如AI会不会主动追问模糊的需求,能不能在多轮对话中保持上下文一致。
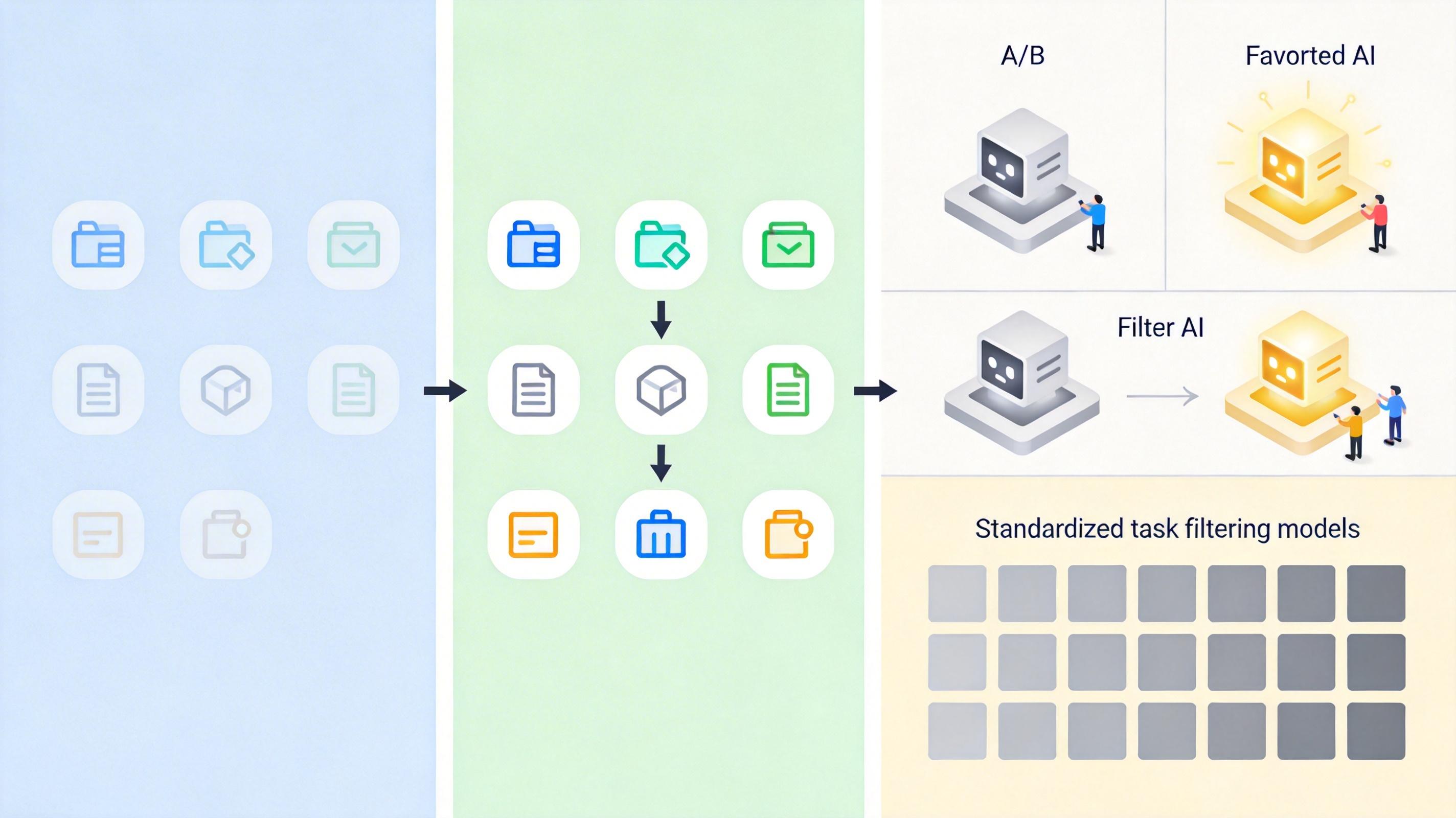
为了避免数据污染,CursorBench还加入了「动态更新」机制:每隔几个月就替换一批任务,同时从内部代码库和受控来源补充新任务,确保模型没法靠「背题」拿高分。更狠的是,它采用线上线下混合评测:线下用标准化任务筛选模型,线上再通过A/B测试看真实用户的接受度——只有开发者真的用起来顺手的AI,才算真的高分。
从CursorBench的结果看,Claude的暴跌其实是暴露了它的「应试属性」——擅长解决明确的、有标准答案的问题,但面对模糊的、需要权衡的真实开发场景,效率就会大打折扣。而Cursor自研的Composer模型能脱颖而出,恰恰是因为它从训练开始就瞄准了「高效协作」:基于混合专家架构,生成速度是主流模型的2倍以上,还能同时调用多个智能体并行处理任务。
这也折射出AI编程的行业趋势:单一的代码生成能力已经不够,未来的AI编程助手要像「同事」而非「工具」——能理解模糊需求,能主动规划方案,能高效完成多步骤任务,甚至能和人类开发者配合优化代码。
当然,CursorBench也不是完美的。目前它的任务还局限在Cursor平台的使用场景,开放度不足,也没有第三方独立验证。但它至少捅破了一层窗户纸:AI编程的评测,终于要从「实验室得分」回到「真实生产力」了。
Claude的分数暴跌不是终点,而是AI编程评测的新起点。过去我们用「能不能写出正确代码」定义AI的能力,现在我们终于开始用「能不能帮开发者高效完成工作」来衡量价值。
好用,比正确更重要。这句话不仅是CursorBench的核心逻辑,也是AI编程工具从「实验室」走向「生产线」的必经之路。未来的AI编程助手,不再是比谁的跑分更高,而是比谁能让开发者少加班、多产出——毕竟,开发者要的从来不是完美的代码,而是能解决问题的高效协作。