
1 天前
1 天前
给AI一段文字:“找出视频里被推倒的熊”,它能一帧不差地把这只熊的像素级轮廓从动态画面里抠出来吗?这是全球顶级视频理解竞赛PVUW的“地狱级”考题——不仅要识别物体,还要读懂动作、理解交互,难度比普通视频分割高出一个量级。2026年4月,哈尔滨工业大学(深圳)团队用一套“零训练”方案拿下了该赛道的世界第一:他们没花一分钱训练专用模型,只是把几个现成的顶级大模型像乐高积木一样拼了起来。
先得搞明白这个竞赛到底难在哪。这个任务叫参照视频目标分割(RVOS)——普通视频分割是给第一帧的标注,让AI跟着“临摹”;但RVOS只给一句自然语言描述,比如“被小男孩追逐的猫”,AI得自己理解这句话,在动态视频里锁定目标,还得输出每一帧的像素级轮廓(也就是掩码)。这次的MeViS-Text赛道更苛刻,描述全是动作导向的,比如“被推倒的熊”,AI必须理解时间维度的动态变化,才能找对目标。
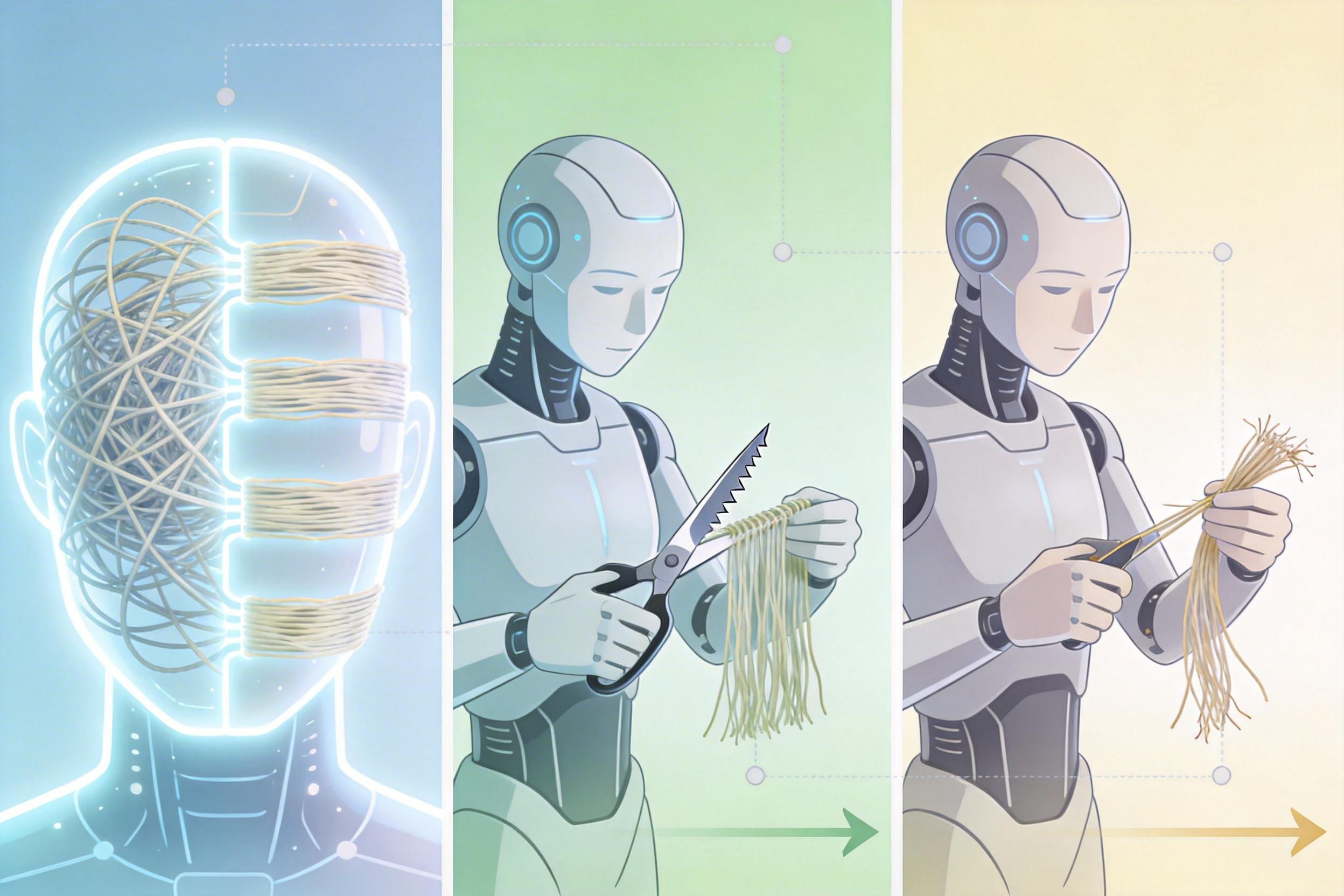
哈工大团队没有像传统思路那样,收集海量数据训练专用模型,而是换了个角度:既然有现成的顶级基础模型,为什么非要自己造轮子?他们的核心洞察很直接:现在的大模型各自擅长不同领域,问题的关键不是训练新模型,而是怎么把它们的能力串起来。
他们设计了一套三阶段流水线:先让Google的Gemini-3.1 Pro把复杂问题拆成简单任务,再让Meta的SAM3负责精准分割和跟踪,最后用阿里的Qwen3.5-Plus检查修正。整个过程没有针对竞赛任务进行任何训练,全靠对现有模型的巧妙调度。
第一阶段是“拆题”:Gemini-3.1 Pro会先把复杂的动作描述拆解成具体目标,比如“两只顶角的牛”会被拆成两个独立个体;然后它会浏览整个视频,为每个目标选出最清晰、最具代表性的关键帧;最后生成一句极具区分度的细节描述,比如“画面右侧、面朝左、侧身有白色标记的棕色公牛”——确保在这一帧里,这个描述只对应一个目标。
第二阶段是“执行”:Meta的SAM3上场。这里用的是SAM3-agent,它不是简单的输入文字出结果,而是像个有规划能力的工人:由Gemini指导它调用工具箱里的工具,比如“点这里”“画个框”,经过多轮交互生成精准的种子掩码。拿到关键帧的种子掩码后,SAM3自带的跟踪器会把这个掩码逐帧传播到整个视频,完成动态跟踪。
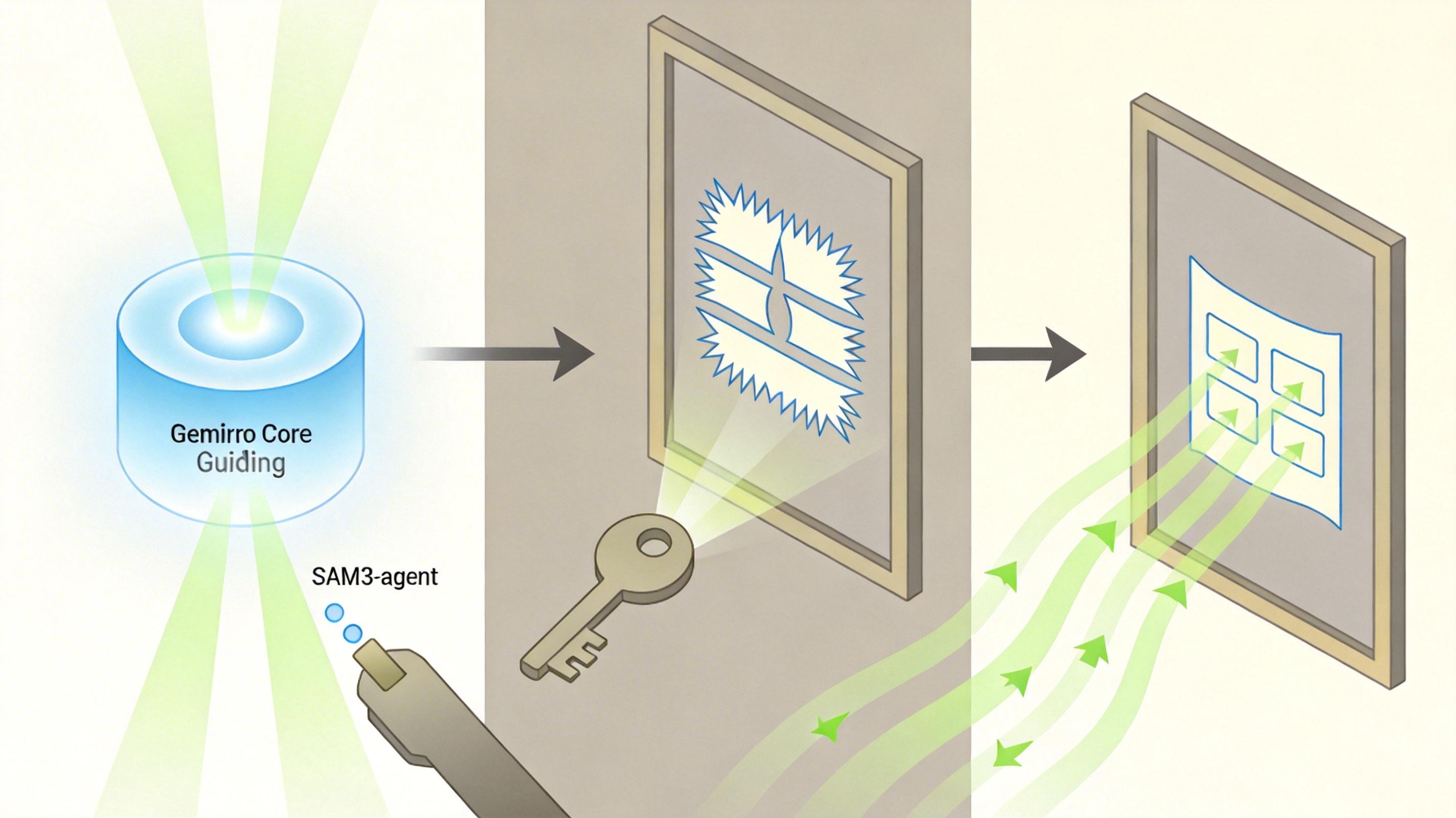
第三阶段是“质检”:Qwen3.5-Plus会检查分割结果,如果发现掩码模糊或者和描述的动作不符(比如描述是“向左走”,结果跟踪了向右走的目标),就会重新生成更精准的描述,触发第二轮分割和跟踪,形成闭环修正。
这套流水线的关键突破,是跳过了传统方法里的“边界框”中间步骤——之前的方法会先让AI输出目标的边界框,再用分割模型抠图,这会丢失大量语言细节。而哈工大的方案直接用语言驱动生成像素级掩码,最大程度保留了语义信息。
竞赛结果证明了这套方案的实力:哈工大团队的Final综合分数达到0.909,其中衡量分割质量的J&F分数为0.7897,比第二名高出近8个百分点。更难得的是,他们在无目标判断(N-acc)和目标识别(T-acc)上也保持了0.96和0.97的高分,没有明显短板。
这不是一次侥幸的胜利,而是AI开发范式转变的信号。过去,AI研发的重心是“训练更好的模型”,要收集数据、标注、调参,耗时耗力;但现在,随着基础模型的能力越来越强,“设计更高效的协作流程”变得更重要——怎么让不同的大模型各司其职,怎么拆解复杂任务,怎么设计闭环修正机制,这些工程问题成了核心。
当然,这套方案也有局限:它依赖Gemini、SAM3这些闭源模型,成本高,可复现性差;调用多个大模型的计算开销也很大,论文里提到实验用了2张RTX 4090显卡,离实时处理还有距离。但它的价值在于提供了一种新思路:在基础模型时代,我们不需要从零开始,而是可以站在巨人的肩膀上,用工程设计释放大模型的潜力。
哈工大团队的这次夺冠,更像是一次“工程实验”——它证明了,当我们不再执着于训练专属模型,而是专注于调度现有大模型的能力时,能以更低的成本、更快的速度解决复杂问题。
这背后是AI研发逻辑的悄然转变:从“训练驱动”转向“设计驱动”。未来的AI系统,可能不再是一个单一的超级模型,而是一群各有所长的智能体,通过高效的流水线协作完成任务。
大模型的未来,不在训练,而在协作。
点击催更,成为大圆镜下一个视频选题!