对抗知识焦虑,从看懂这条开始
App 下载
给AI装个“错题本”,弱监督定位精度跳级
定位精度提升|跨模态匹配|弱监督视觉定位|彭宇新团队|CPL++框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载定位精度提升|跨模态匹配|弱监督视觉定位|彭宇新团队|CPL++框架|多模态视觉|人工智能
想象一下:你给AI发一句“请找到图片里戴红帽子的猫”,它却把镜头对准了旁边的红色沙发——这种“答非所问”,曾是弱监督视觉定位的死穴。不用精准标注的物体框,只靠图文对训练的AI,总在跨模态匹配中掉进错误关联的陷阱,还会把错的当成对的反复强化,陷入越学越错的死循环。直到北京大学彭宇新教授团队的CPL++框架出现:它给AI装了个能自己翻的“错题本”,让模型在训练中动态揪出错误、修正偏差,直接把五大主流数据集的定位精度拉涨了2%到5.8%。这到底是怎么做到的?
先搞懂什么是弱监督视觉定位——就是让AI只靠“图片+文字描述”,精准圈出图里对应文字的目标,不用人工标注每个物体的边框。这省了海量标注成本,但也给AI挖了个大坑:语言是抽象的“戴红帽子的猫”,图像是像素级的色块线条,两者之间隔着一道“异构鸿沟”。
传统弱监督方法硬着头皮做跨模态匹配,就像让一个只懂中文的人对着英文说明书找零件,全靠蒙。一旦AI把“红色沙发”和“红帽子的猫”错误绑定,这个错误会在训练里不断强化,最后彻底跑偏。之前的方法要么用生硬的模板生成伪查询,要么靠静态模型提前过滤错误,都没跳出“被动防错”的思路——就像老师提前把错题划出来,但学生还是不会自己找错。
CPL++的第一个破局点,是干脆绕开跨模态匹配的坑:用大模型给每个图像区域生成三条不同角度的伪查询——比如针对猫的区域,生成“黄白相间的猫”“戴着红帽子的猫”“趴在地毯上的猫”,然后在文本内部做单模态匹配,找和真实查询最像的区域当初始标签。相当于先让AI把说明书翻译成中文,再找零件,靠谱多了。
真正让CPL++跳出死循环的,是它的核心——自监督关联校正模块,说白了就是让AI学会自己改错题。这不是简单的“错了就改”,而是一套动态闭环的纠错流程:
第一步,它会给每个候选区域做“全面体检”:不只看检测器的置信度,还要对照查询里的类别、属性、空间关系打分——比如查询是“桌子上的杯子”,就会检查区域是不是杯子、有没有在桌子上,综合算出一个置信度,筛掉明显不靠谱的关联。
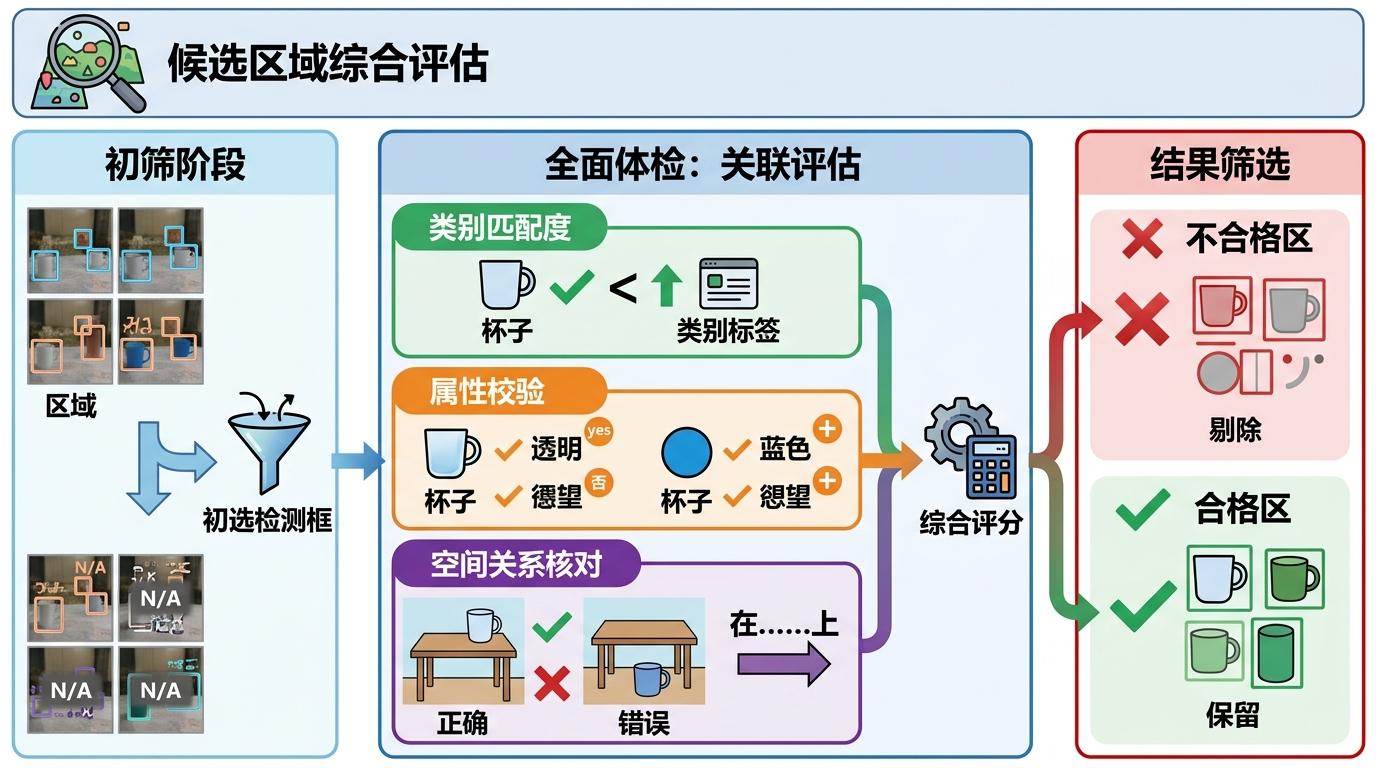
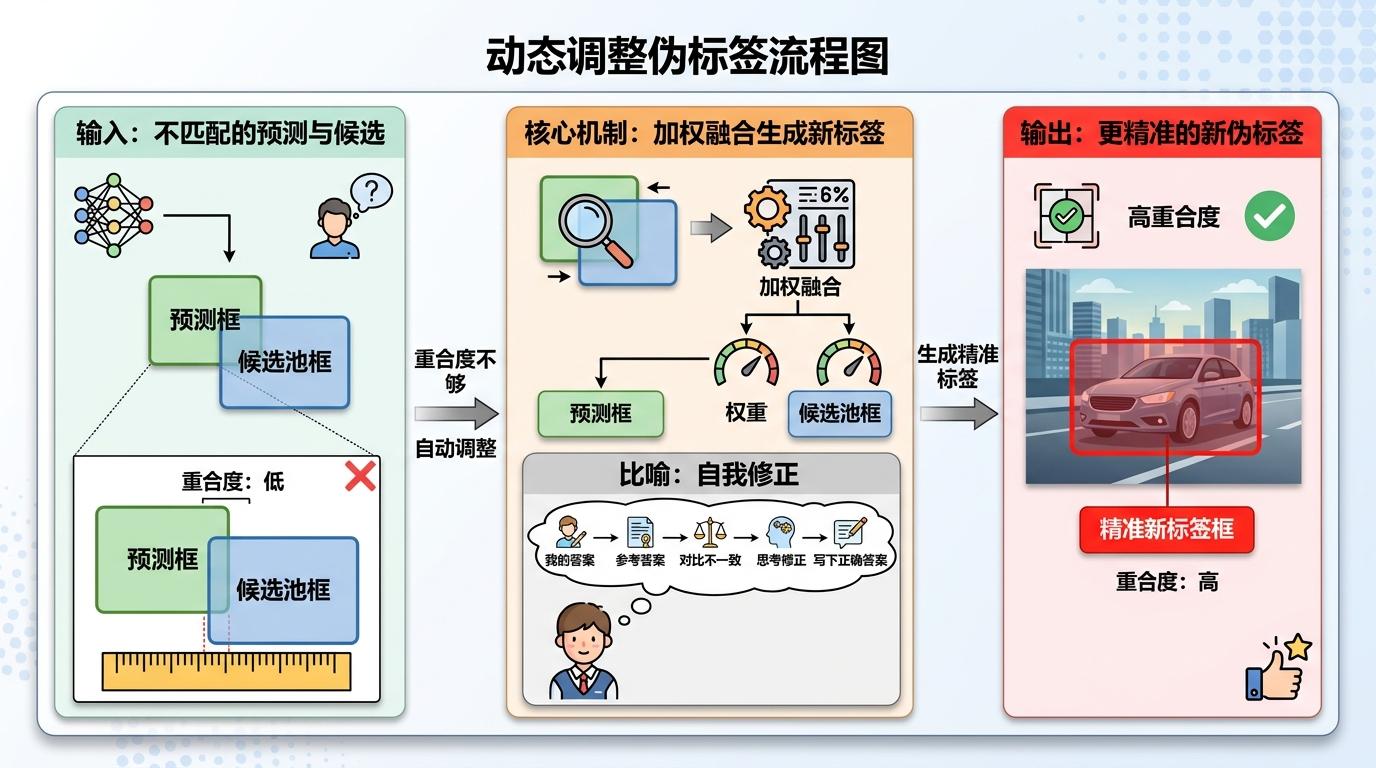
第二步,动态调整伪标签:如果AI自己预测的框和候选池里最匹配的区域重合度不够,它会自动把两个框加权融合,生成更精准的新标签。就像学生做完题,发现和参考答案对不上,会自己琢磨哪里错了,重新写一个更准确的答案。
第三步,用训练损失当“错题预警”:训练中如果某个样本的损失突然升高,AI会自动降低这个样本的权重,避免错误被反复强化。相当于做一套题,错的题下次少练,对的题多巩固。
最关键的是,这套流程是完全自监督的——不需要额外标注,全靠AI自己在训练中迭代优化。实验里,它硬生生从初始的错误关联里,纠正了超过5000条标签,剔除了17000多条虚假标签,直接把模型的mAP拉涨了3到4个百分点。
当然,CPL++也不是完美的。目前它的纠错机制还主要针对2D图像,面对3D场景里的空间关系、动态视频里的时序变化,这套“错题本”还得升级——比如怎么在3D点云里判断“杯子在桌子上”的空间逻辑,怎么在视频里跟踪“跑向门口的狗”的动态关联。

而且它的计算成本也不算低:生成多样化伪查询、动态校正标签都需要额外算力,要落地到手机、机器人这类边缘设备,还得做轻量化优化。另外,面对极端模糊的图像、歧义性极强的描述,比如“图片里的小的那个”,AI还是可能掉进新的错误陷阱——毕竟连人类都可能理解错,更别说只靠数据学习的AI了。
但不可否认,CPL++给弱监督学习指了一条新路子:与其花大量人力标注数据,不如让AI学会自己找错、自己纠错。这不仅能降低落地成本,更重要的是,它让AI离真正的“自主学习”更近了一步。
当我们还在纠结怎么给AI喂更多数据、做更复杂的模型时,彭宇新团队的研究给了一个新的思路:让AI学会“自知之明”。从只会被动接受数据的“刷题机器”,变成能主动找错、自我修正的“学习者”,这可能才是AI突破性能瓶颈的关键。
毕竟人类的学习,从来不是靠做无限多的题,而是靠不断复盘错题、修正认知。AI的进化,或许也会沿着同样的路径——给AI一个错题本,它能自己跑向更远的地方。未来的智能系统,可能不再是越复杂越好,而是越会“反思”越好。