对抗知识焦虑,从看懂这条开始
App 下载
用游戏数据训AI,效果碾压10倍量真实文本
像素轨迹|预训练数据|MIT团队|细胞自动机|生命游戏|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载像素轨迹|预训练数据|MIT团队|细胞自动机|生命游戏|大语言模型|人工智能
1970年,数学家约翰·康威在棋盘上写下四条简单规则:活细胞邻居太少会孤独死去,太多会拥挤致死;死细胞凑齐三个活邻居就会复活。没有玩家,没有操控,屏幕上却自动涌现出滑翔机、脉冲枪,甚至能模拟计算机的复杂结构——这就是大名鼎鼎的“生命游戏”,半个世纪里一直是复杂性科学的经典。但没人能想到,这些只会在网格上蹦跶的像素点,有一天能教会AI说话。MIT团队最近做了件离谱的事:用类似“生命游戏”的细胞自动机生成的数据,去预训练大型语言模型。这些数据里没有一个字,只是12×12网格上像素演化的轨迹,但仅用1.64亿个这种“图案token”,效果竟然超过了16亿个真实英语文本。这到底是怎么回事?
你可以把“生命游戏”想象成一个没有裁判的棋盘:每个格子是一个细胞,只遵守四条死规则,却能演化出无穷无尽的动态图案——就像几百个人在广场上,只靠“跟紧身边三个人”“离太近就躲开”这两条简单指令,最后走出了复杂的集体舞。而MIT团队用的神经细胞自动机(NCA),就是给这个棋盘换了个“活规则”。
传统细胞自动机的规则是固定死的,就像永远按同一套舞步跳舞;NCA则把规则换成了一个小型神经网络——具体来说是3×3卷积加一层MLP。每次生成训练数据时,研究者就随机给这个神经网络换一套权重,相当于给棋盘随机换一套全新的演化规则,然后让格子们按新规则跑一遍,把整个过程的像素轨迹记录下来。
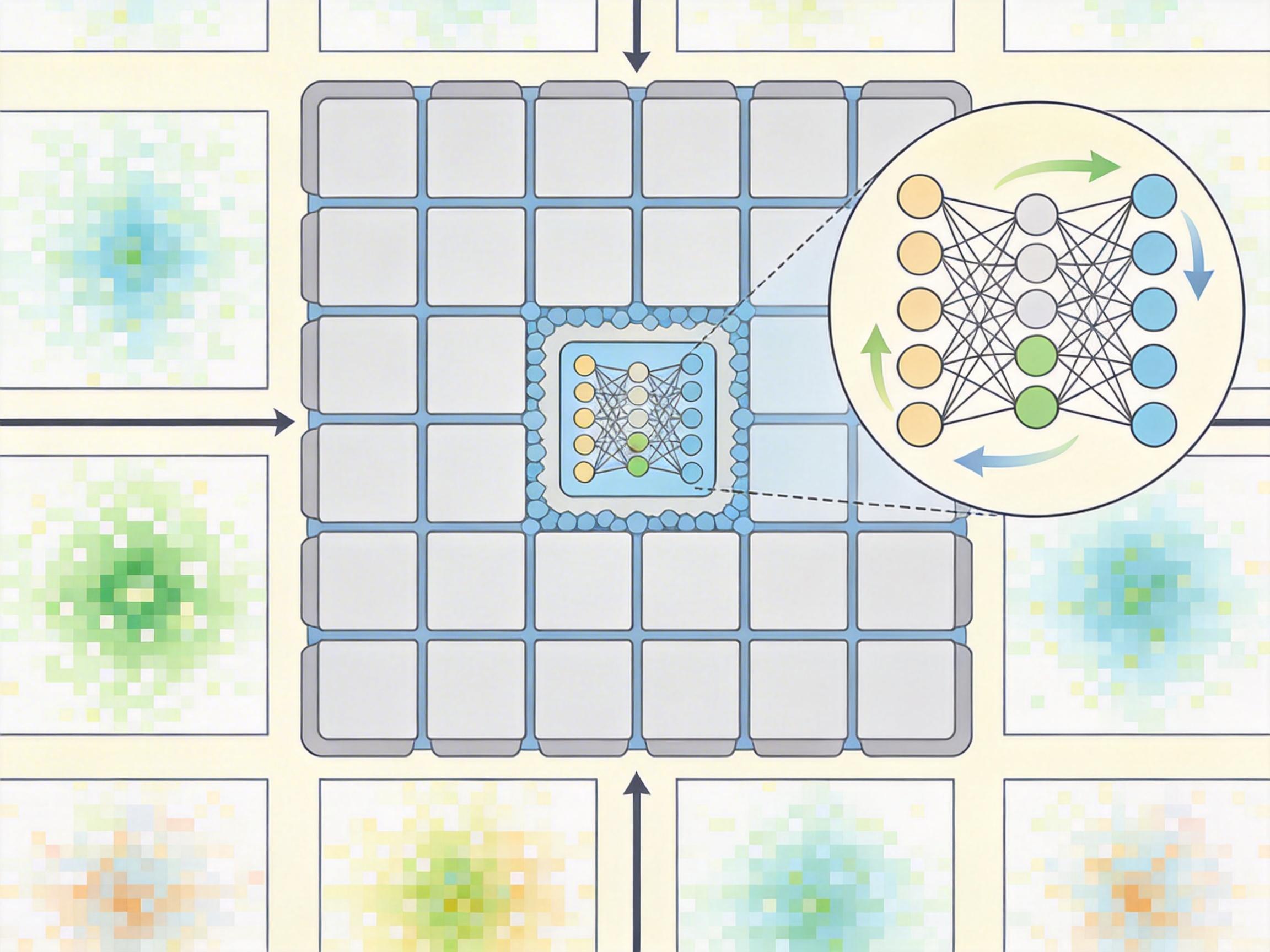
这些轨迹被切成2×2的小图像块,再转换成模型能读懂的token序列。模型要做的,就是根据前面的像素轨迹,预测下一个出现的图像块。关键在于,每一条训练序列都对应一套它从没见过的新规则,它没法靠记忆偷懒,只能逼着自己从像素变化里推断出背后的规则——就像你看一群人跳陌生的舞蹈,要猜出他们遵守的舞步逻辑。
实验结果让所有人意外:在这些纯图案数据上预训练过的模型,学起自然语言来更快更好——困惑度最多降了6%,收敛速度最多快1.6倍。更有意思的是,合成数据不是越多越好、越复杂越好,得和目标领域的“脾气”对上。
研究者用gzip压缩率衡量数据复杂度:压缩率越低,说明数据里的重复模式越少,结构越复杂。他们把NCA数据按压缩率分成不同区间,结果发现网页文本和数学文本,用最高复杂度(压缩率50%以上)的合成数据效果最好;而代码领域,中等复杂度(30-40%)的数据才是最优解。巧的是,这刚好和目标语料本身的复杂度对上:网页和数学文本的gzip压缩率在60-70%,代码只有32%。
这就是研究者说的“领域定向数据设计”——就像给不同胃口的人做饭,网页文本爱吃“硬菜”,代码爱吃“家常菜”,不能一概而论。自然语言训练里你没法随便改英语的特性,但合成数据可以:调整NCA的规则空间、网格大小、复杂度分布,就能精准匹配你想训练的能力。这是自然语言数据没有的“调控杠杆”。
那么,从像素图案里学来的能力,到底是怎么帮AI学语言的?研究者做了个拆解实验:把预训练后的模型不同组件重新初始化,看哪个组件影响最大。结果很明确:重新初始化注意力层,模型性能掉得最厉害;而MLP层的影响,得看领域——在网页文本任务里,保留NCA阶段的MLP权重反而会干扰学习,但在代码任务里就没什么影响。
这背后是模型内部的功能分工:注意力层负责学习通用的“依赖追踪”和“规则推断”——就像你读句子时,要搞清楚每个代词指的是谁、每个因果关系怎么连;而MLP层更像个“记忆库”,存的是特定领域的模式和统计规律,比如英语里的常用搭配、代码里的语法模板。
从NCA数据里训练出的注意力层,练的是“从序列里找规律”的通用本事,不管这个序列是像素还是文字,底层逻辑是通的。这也呼应了MIT团队提出的“柏拉图表征假说”:不同模态的AI模型,规模大到一定程度,内部都会趋向于同一种对世界的通用表征——就像不管用画笔还是相机,画出来的拍出来的,都是对同一个世界的捕捉。
当然,这项研究还只是个开始。目前的实验只到16亿参数的模型,增益会随着模型规模增大而递减,千亿参数级的大模型能不能吃这一套,还没人知道。而且当NCA的“字母表”太大时,训练收益到一定程度就会饱和甚至下降,说明光堆数据量没用,得更精细地设计合成数据的规则。
但它撕开了一道口子:我们一直以为AI学语言得从语言里学,现在发现,学透语言背后的“规则逻辑”,可能比学语言本身更重要。就像学写作的人,先读懂逻辑和结构,比背好词好句有用得多。
数据的本质,是规则的载体。 当我们不再把数据当成“知识的容器”,而是“训练逻辑的工具”,或许就能跳出自然语言的局限,找到更高效、更可控的AI训练之路。毕竟,生命游戏里的像素能演化出计算机,谁知道下一个从网格里跑出来的,会是什么?