对抗知识焦虑,从看懂这条开始
App 下载
不用练大模型,杜克团队靠两步做同步音视频
三维视频帧|AI生成内容|联合训练|音视频同步|杜克大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载三维视频帧|AI生成内容|联合训练|音视频同步|杜克大学|多模态视觉|人工智能
当你让AI生成一段“霓虹街舞对决”的音视频,大概率会得到画面炫酷但音乐踩不准鼓点、人群欢呼和动作完全脱节的成品——这是多模态AI至今没解决的核心难题:让画面和声音精准“合拍”。过去研究者们死磕“联合训练”,用一个超大模型同时学画面和声音,结果要么烧光算力,要么生成内容四不像。2026年3月,杜克大学的团队跳出了这个死胡同,用一套看起来“偷懒”的方法,做到了现有技术下最务实的音视频同步。
多模态音视频生成的本质,是要让AI同时看懂三维的视频帧(宽×高×时间)和一维的音频波形——这两种数据的时空尺度、语义密度完全不同,就像让一个画家同时当音乐家,还要保证每一笔都踩在节拍上。
主流的“联合训练”思路,是用双U-Net结构的MM-Diffusion模型,一边处理视频一边处理音频,中间靠交叉注意力让两者互相“参照”。但杜克团队亲自试过后发现,这条路几乎是死路:训练需要海量精准配对的音视频数据,他们爬了64小时音乐会和13小时《使命召唤》视频才凑够数据集;烧了大量算力训练2万步,模型只能生成模糊的人影和杂乱的噪音,损失曲线波动得像过山车。
另一种“共享潜空间”思路更惨:把视频和音频都压缩到同一个“潜空间”里生成,结果因为两种数据的编码解码架构完全不兼容,生成的内容要么画面崩坏要么音频失真,彻底失败。
既然从头造“全能模型”行不通,杜克团队换了个思路:站在巨人的肩膀上,把任务拆成两步。
第一步,用现成的顶级文本到视频模型生成画面——他们选了CogVideoX,这个模型靠3D VAE把视频压缩到潜空间处理,再用专家变换器根据文本风格动态调整参数,能生成10秒长、768×1360分辨率的流畅视频。这一步只需要解决“文本到画面”的单模态问题,技术已经非常成熟。
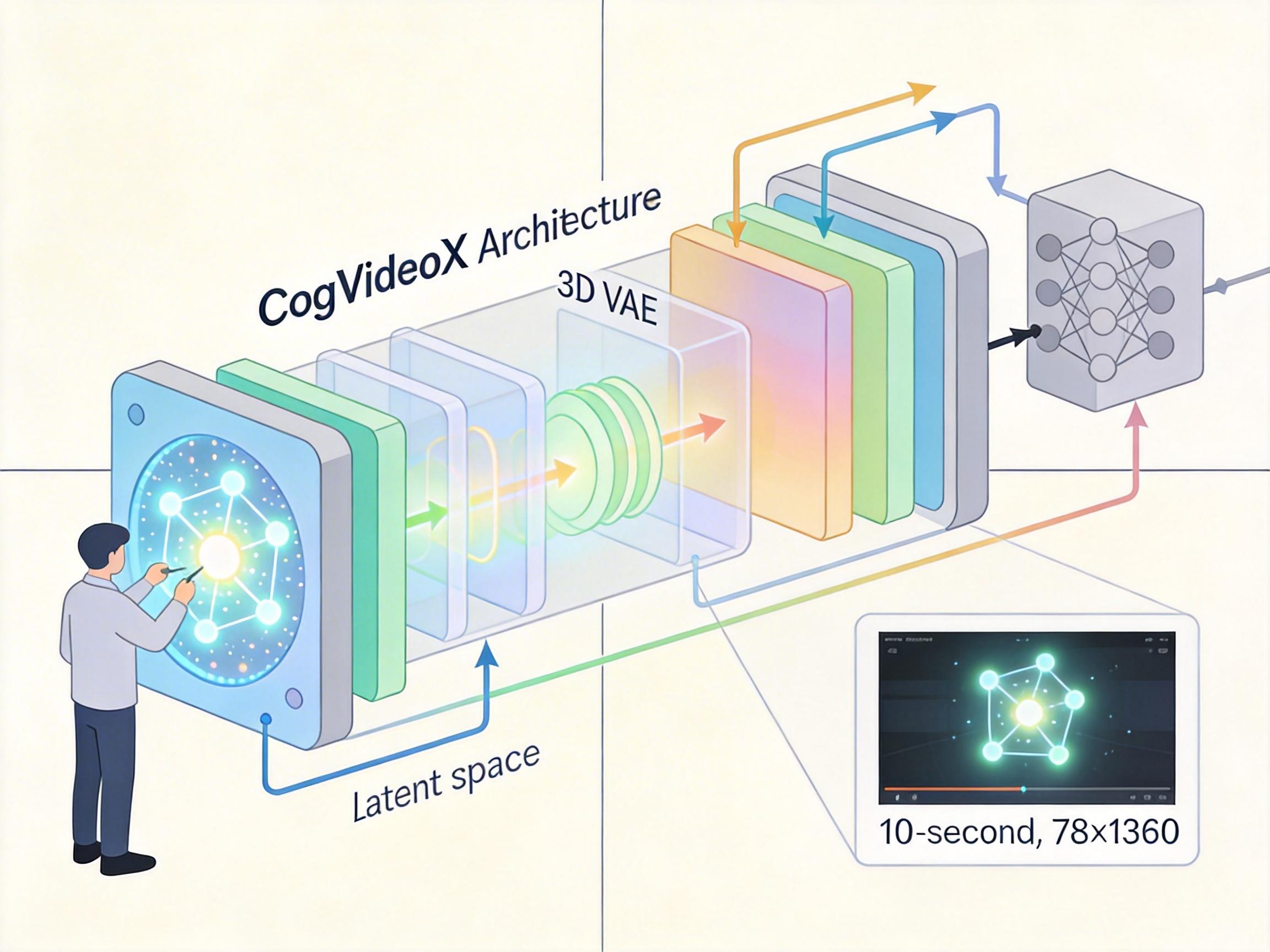
第二步,把生成好的视频和原始文本提示一起喂给视频到音频模型MMAudio。这个模型用条件流匹配技术,像在一条河里划船一样,从随机噪声“流”出匹配的音频——它不仅看视频里的动作细节(比如鼓槌落下的瞬间),还对照文本提示的语义(比如“嘻哈节拍”“人群欢呼”),避免只看画面产生的歧义。

这种模块化设计的好处显而易见:不用从头训练大模型,算力成本直接砍半;每个模块都是各自领域的专家,生成质量有保障;更重要的是,两个模块可以独立升级,比如以后有了更好的视频模型,直接替换就行。
实验数据显示,这套两步走方案的表现远超从头训练的联合模型:FAD(音频距离)从9260降到5020,FVD(视频距离)从251降到206,生成的街舞视频里,舞者的动作和音乐节拍能精准对应,人群欢呼也能和画面里的观众动作同步。

但它也有无法回避的局限:和在单一舞蹈数据集上充分训练的联合模型比,FAD和FVD指标还有不小差距,跨模型的信息传递难免有损耗,比如视频里的细微动作可能无法被音频模型精准捕捉。而且串行运行两个大模型,生成时间比联合模型长了近一倍,对硬件的要求也不低。
更关键的是,这套方案的稳定性依赖于两个外部模型的表现,如果其中一个模型更新出了问题,整个系统的输出都会受影响。但对于资源有限的团队来说,这已经是当前最务实的选择——不用烧几千万的算力,就能搭建出效果不错的音视频生成系统。
杜克团队的这套方案,本质上是用工程智慧替代了纯粹的模型创新。在大模型竞赛的时代,人们总想着造更大、更全能的模型,却忘了有时候把复杂问题拆成简单任务,用现成的技术组合出解决方案,反而能更快落地。
更值得关注的是,这套模块化思路为多模态AI的发展提供了另一种可能:不一定非要追求“大一统”的全能模型,用“小模型+智能路由”的方式,让不同的模块各司其职,反而能兼顾效率和可控性。未来的AI系统,或许会像一个精密的钟表,每个齿轮都在自己的位置上精准运转,而不是一个臃肿的巨人。
好的AI,不是全能的巨人,是高效的协作网络。