对抗知识焦虑,从看懂这条开始
App 下载
向量检索爆雷:99%的计算可能都浪费了?
智能体|RAG|IceBerg报告|HNSW算法|向量检索|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载智能体|RAG|IceBerg报告|HNSW算法|向量检索|多模态视觉|人工智能
在多模态AI的浪潮之巅,从RAG到智能体,几乎所有前沿应用都构建在一个共同的基石之上:向量检索。它如同AI大厦的钢筋骨架,支撑着语义理解与信息召回。行业普遍认为,这项技术已趋于成熟和标准化——只要用上被誉为“常胜将军”的HNSW算法,似乎就能高枕无忧。但一个令人不安的问题浮出水面:如果这个我们深信不疑的基石,存在着一道隐形的裂缝呢?如果那些消耗巨大算力、追求极致召回率的努力,有99%都只是在做无用功呢?
2025年12月25日,这个看似平静的冬日,因一份名为“IceBerg”的基准测试报告而震动了整个AI领域。由向量检索领域专家傅聪联合浙江大学高云君、柯翔宇团队发布的这项研究,像一块巨石投入湖中,彻底颠覆了过去五年业界对向量检索的普遍认知。
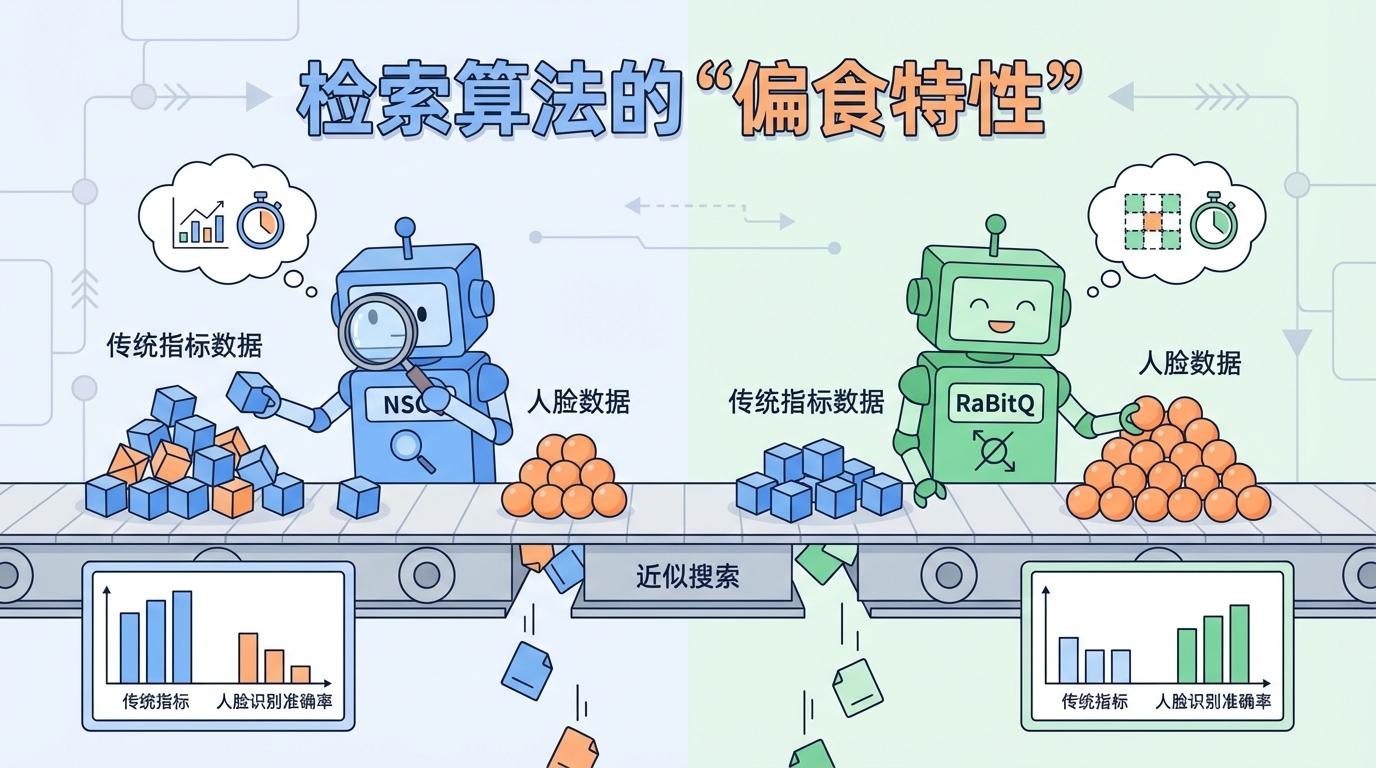
报告的核心结论如同一声惊雷:以真实的下游任务(如人脸识别、图像分类的准确率)作为黄金标准时,被奉为圭臬的HNSW算法在许多场景下表现平平,甚至输给了那些被认为相对“过时”的量化算法,如RaBitQ。 这意味着,行业长期以来依赖的“召回率-查询速度(Recall-QPS)”评价体系,可能只是海平面上的冰山一角,它不仅造成了严重的“产能过剩”和算力浪费,更可能误导了无数AI应用的优化方向。
为何会出现如此巨大的偏差?IceBerg团队提出了一个“信息损失漏斗”模型,直观地揭示了问题根源。信息从原始数据到最终应用结果,会经历三个不断收窄的瓶颈,导致“距离相近”并不等同于“语义相似”。
第一层瓶颈:表征模型的“先天不足”。 生成向量的AI模型,其学习目标通常是理解“语义”,而非学习一个完美的“度量空间”。这就像一位优秀的翻译,能理解两种语言的深层含义,却不一定能将它们在字典里按页码远近精确排列。
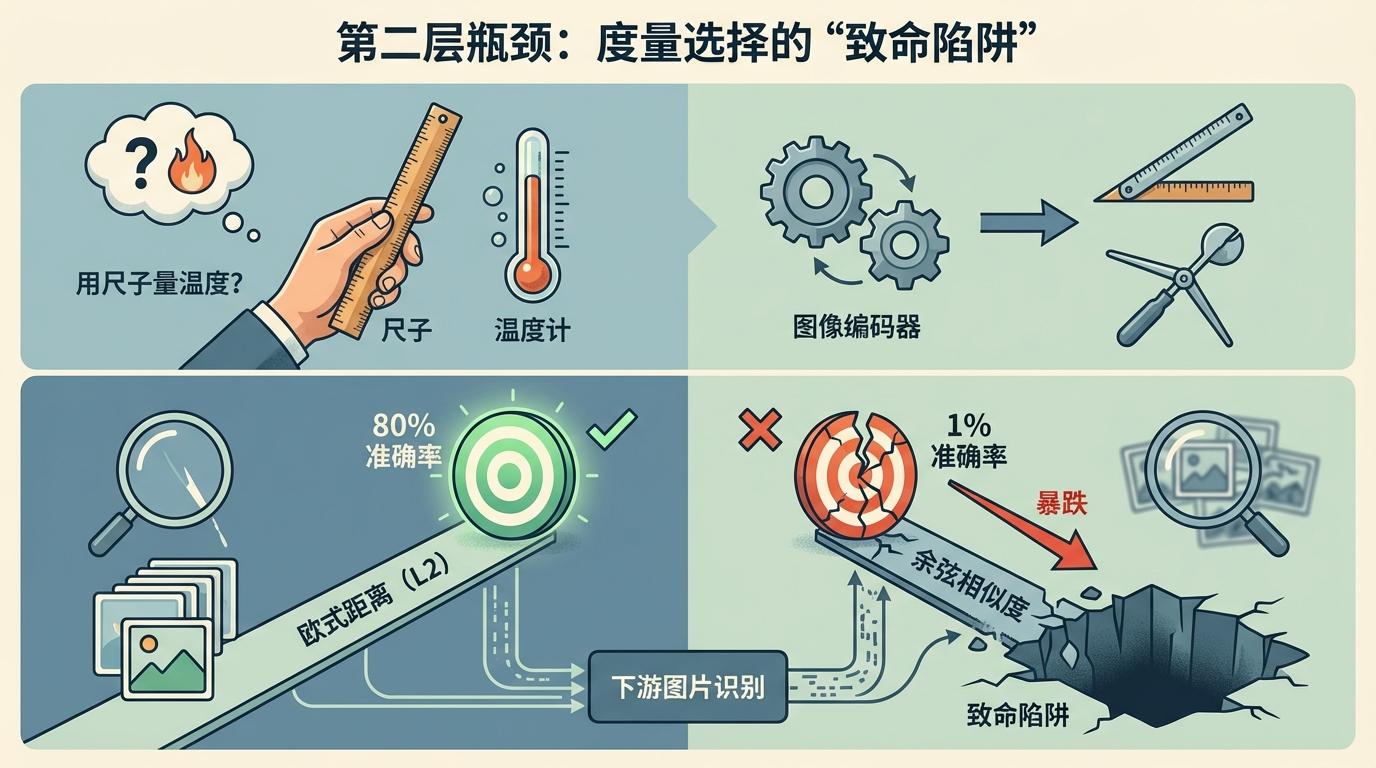
第二层瓶颈:度量选择的“致命陷阱”。 这是最容易被忽视的一环。报告用一个惊人的案例说明了其重要性:同一个图像编码器产生的向量,使用欧式距离(L2)进行检索,下游图片识别准确率高达80%;而换成行业内几乎“无脑上”的余弦相似度(内积),准确率竟暴跌至1%! 这无异于用一把测量长度的尺子去衡量温度,工具的错用导致了结果的谬之千里。
IceBerg的发现,为整个AI行业敲响了警钟,也指明了一条从“算力内卷”走向“价值回归”的新路径。
对于技术开发者而言,这意味着构建RAG或多模态应用时,不能再简单地将HNSW作为默认选项。幸运的是,IceBerg不仅指出了问题,还提供了解决方案。它开源了一套自动化的算法检测方案,能通过分析数据本身的统计特征(如聚类程度、方向分散度),像一位经验丰富的向导,为你构建一颗“决策树”,自动推荐最适合当前数据的检索算法与度量方式,让非专业背景的开发者也能无痛优化。
对于企业和决策者而言,这意味着巨大的成本节约潜力。过去为了追求那最后1%的召回率而投入的巨额算力,很可能对最终业务价值毫无贡献,甚至产生负面影响。现在,通过更科学的评估和选择,企业可以用更低的成本,实现更好、更可靠的AI应用效果,将资源真正投入到创造价值的环节。
IceBerg揭示的并非终点,而是一个全新的起点。它让我们意识到,向量检索的标准化之路远未完成,尤其是在复杂的多模态世界中。未来的探索将更加深入和务实:
新一代评测标准:行业亟需建立更多像IceBerg这样,以最终应用效果为导向的评测体系。例如,已有团队开始构建如“General-Bench”这样的“通才智能”测试集,从更宏观的视角评估AI的跨模态协同能力,而非局限于单一的技术指标。
算法与数据的“联姻”:未来的研究重点将从追求通用算法,转向探索算法与数据分布的“兼容性”,以及度量方式与下游任务的“匹配度”。开发能够跨度量、处理多向量的统一检索算法,将是实现真正标准化的关键。
与知识的深度融合:单纯的向量相似性检索存在无法进行复杂推理的局限。将向量检索与知识图谱等结构化知识深度融合(GraphRAG),让AI不仅能“看到”相似,更能“理解”关系,将是弥补这一短板的重要方向。

长久以来,AI社区或许过于迷恋那些浮在“海平面”之上的漂亮指标,而忽略了水面之下真正决定成败的复杂现实。IceBerg报告就像一台深水探测器,让我们首次看清了向量检索这片深海的全貌。
这不仅是对一种算法或一个指标的重新审视,更是对整个AI领域发展范式的一次重要反思。真正的技术成熟,标志着我们不再盲目追求更强的算力、更高的分数,而是开始回归本源,深刻理解每一个技术环节的真实价值,并为之建立科学、理性的评价体系。告别幻觉,脚踏实地,这或许是通往通用人工智能的必经之路。