对抗知识焦虑,从看懂这条开始
App 下载
AI视频终于从“能看”变“能用”,这两步是关键
生成式模型|像素漂移|视频一致性|AI视频生成|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载生成式模型|像素漂移|视频一致性|AI视频生成|AIGC|人工智能
你有没有过这种体验:刷到一段AI生成的短视频,画面精致得像电影截图,忍不住点进去看完整内容——结果才过10秒,就看见视频里的人眼睛突然移到了脸颊,杯子掉在地上居然往天上弹,前一秒阳光明媚的房间,下一秒阴影就歪到了墙外面。过去两年,AI视频一直困在这个怪圈里:单帧惊艳,成片拉胯,只能当实验室里的“花瓶”,根本进不了真实的创作流程。直到最近,有团队终于啃下了两块硬骨头——让AI生成的视频,终于能像真实拍摄的那样,“不穿帮”“讲逻辑”。
你可以把AI生成视频的过程想象成一群画家接力画画——每个人只看前一张画的局部,接着往下画。画到第十张,人物的鼻子可能已经从脸中间跑到了额头上,窗外的树也可能长成了电线杆。这就是AI视频的老毛病:时间一致性缺失。
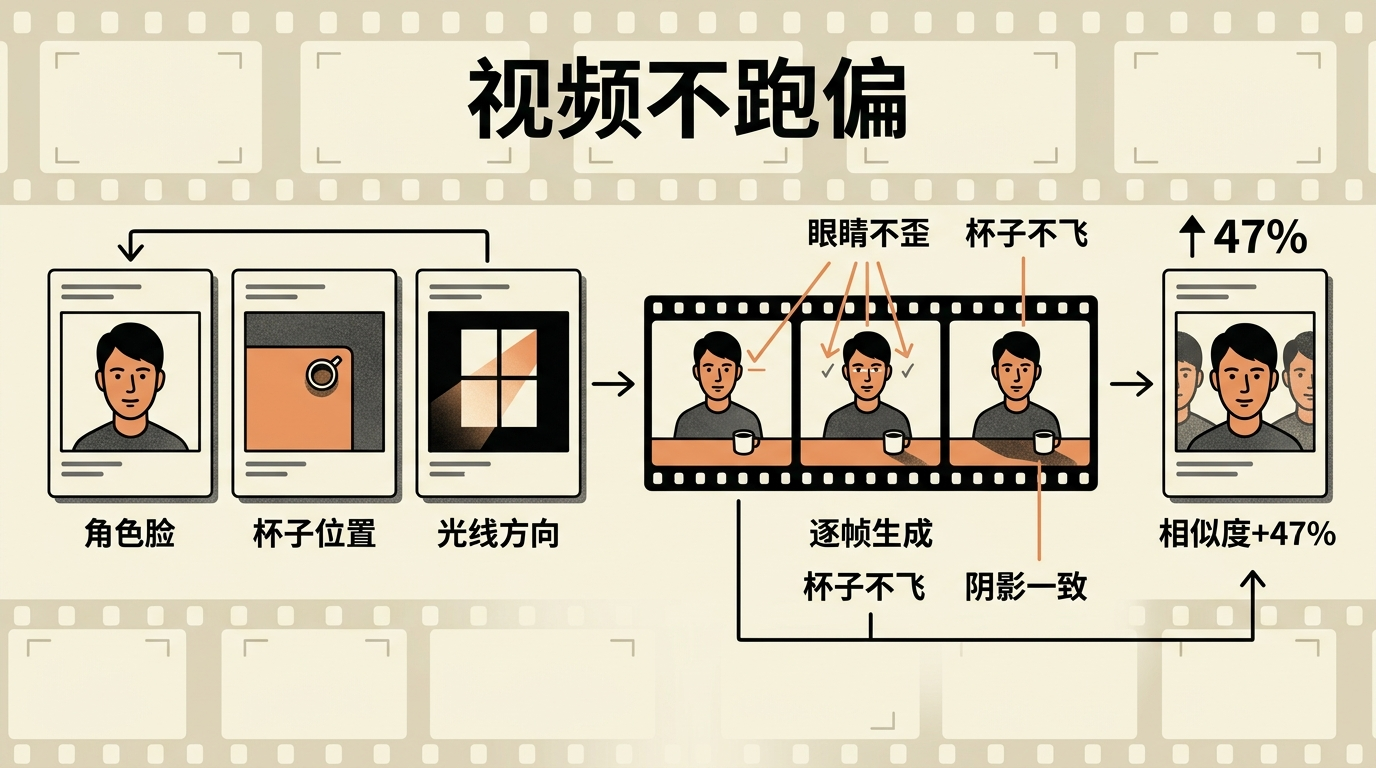
过去的模型只盯着相邻两帧的相似度,就像画家只模仿前一张画的笔触,完全不管整幅画的布局。新的解法是给模型装一个“全局记忆本”:用时空注意力机制让它记住第一帧里人物的五官位置、场景的光影方向,再用全局残差误差机制,逐帧检查画面里的每个像素是不是“跑错了位置”。
简单说,就是先给整个视频定好“剧本”:人物的脸长什么样,杯子放在桌子的哪个角,阳光从哪边照过来。每生成一帧,都要对照这个剧本查一遍——眼睛不能歪,杯子不能飞,阴影不能乱。有团队用这种方法,让视频里人物的面部相似度提升了47%,终于解决了“画着画着人变样”的尴尬。
如果说时间一致性是“不穿帮”,那物理模拟就是“不违和”——这些细节观众未必能立刻说出来,但一旦错了,就会觉得“哪里怪怪的”。比如人走路时头发应该向后飘,而不是像被风吹着往前跑;杯子掉在地上应该弹两下停住,而不是像皮球一样弹到天花板。
过去的AI根本不懂这些,它只是在“模仿”视频里的画面,不知道“为什么”会这样。新的模型开始把物理规律当“规矩”来学:比如给人物的衣服和头发加“虚拟骨骼”,根据走路的速度计算摆动的幅度;给掉落的物体设定重力参数,让它的运动轨迹符合牛顿定律。
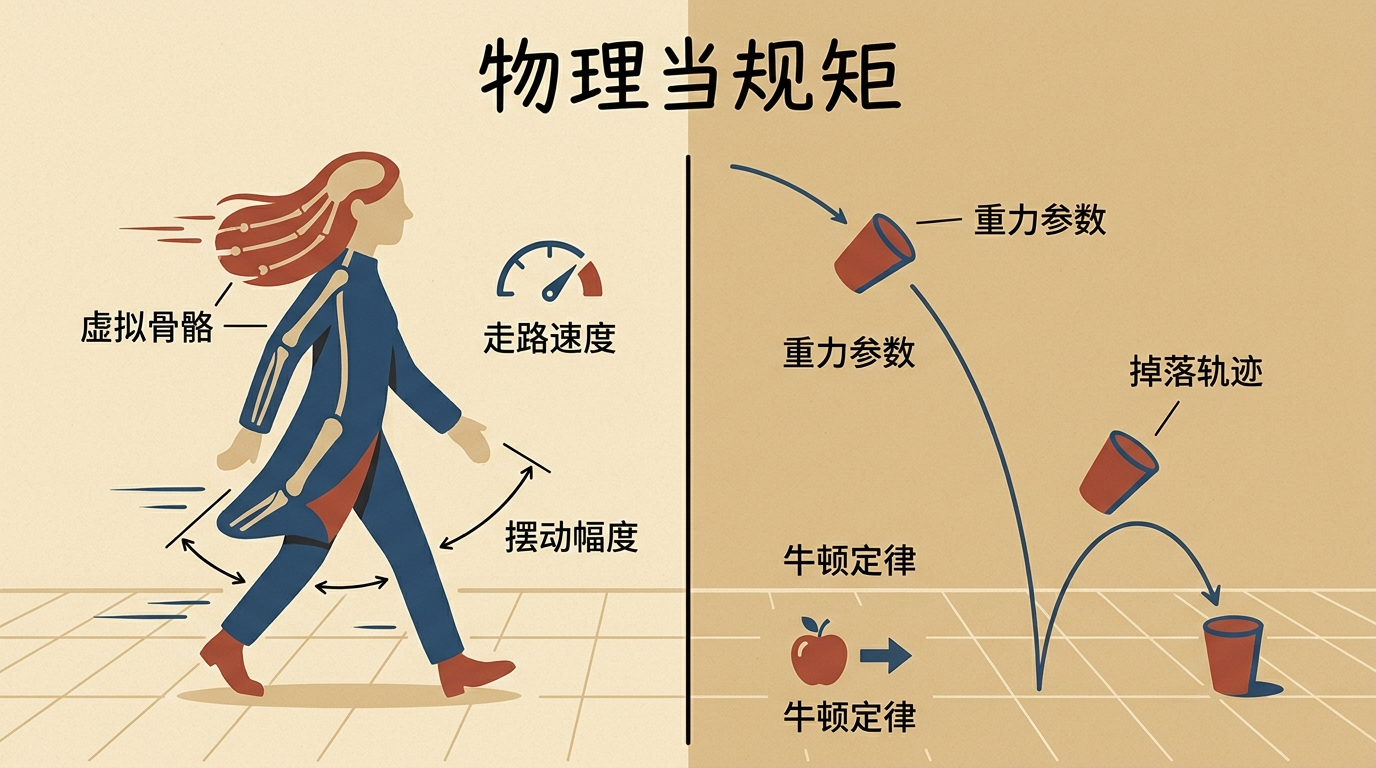
还有团队直接把物理引擎和生成模型绑在一起——先让物理引擎算出物体该怎么动,再让AI照着这个轨迹生成画面。这样一来,人物跑步时衣角的摆动、球被踢出去的弧线,终于和现实世界对上了。这些细节不决定画面“好不好看”,却决定了AI视频能不能从“演示片段”变成“能用的素材”——毕竟没人会用一个杯子往天上飞的视频做广告。
技术突破只是第一步,真正让AI视频落地的,是把创作者的真实需求喂给模型。有团队收集了数十万创作者的反馈:有人说生成的视频人物动作太僵硬,没法用来做舞蹈教程;有人说场景切换时灯光突然变了,剪进视频里太突兀。这些问题不是实验室里的测试数据能发现的,只有真正用在创作里才会暴露。
他们把这些反馈变成了模型的“新作业”:针对舞蹈视频优化肢体运动的流畅度,针对广告视频强化场景切换时的光影一致性。这种“用户用→提问题→改模型→再给用户用”的闭环,让模型的迭代不再是“为了技术而技术”,而是“为了好用而技术”。
当然,现在的AI视频还不算完美:生成1分钟以上的长视频时,偶尔还是会出现逻辑断裂;复杂的多人互动场景,比如一群人打球,还是可能出现人物“穿模”。而且版权问题像一把悬剑——AI学了太多真实视频,生成的内容一不小心就可能侵权。这些都是摆在面前的新难题。
当AI视频终于能“不穿帮”“讲逻辑”,它就不再是实验室里的玩具,而是能帮创作者省时间、提效率的工具。未来可能不会再有“AI生成视频”这个说法——就像现在没人会特意说“用电脑剪的视频”,AI会变成视频创作里的标配,就像相机、剪刀、调色板一样。
技术的终极意义从来不是炫技,而是让人能更轻松地表达自己。AI视频的未来,是让创意追上想象。