
1 天前
1 天前
你让ChatGPT描述苹果落地,它能把牛顿的生平都给你讲一遍;但你要是把苹果递到它「眼前」,它根本不知道这东西会砸到脚——它只是在背文本,从来没真的理解重力。2026年春天,当全球还在为大语言模型的「文采」惊叹时,AI圈最顶尖的一批人已经悄悄换了赛道:杨立昆带着10亿美元融资创办新公司,李飞飞的World Labs完成同量级融资,DeepMind、英伟达、Verses各出杀招,所有人都在盯着同一个目标:让AI真正「懂」世界。这不是简单的技术升级,而是要给AI装一套能感知物理规律、理解空间关系、预测行为后果的「大脑操作系统」——也就是世界模型。
没人能说清世界模型到底是什么,但有五个方向正在被验证。杨立昆的JEPA派走的是「抽象极简风」:它不浪费算力去预测每片树叶的飘落轨迹,而是让AI在一个看不见的「抽象空间」里学规律——比如风会吹落树叶,球会滚下桌子。它的最新模型V-JEPA 2,只用62小时机器人数据就学会了在陌生环境里操作新物体,成功率达65%-80%,比传统方法省了几千小时的训练成本。
李飞飞的空间智能派则在「搭真实的3D积木」:他们的产品能把一段文字、一张照片变成可编辑的3D世界,你能在里面走、看、移动物体,甚至导出到游戏引擎里用。但这套「积木世界」目前还不怎么懂物理——走几步就会出现视觉变形,更别提预测物体的运动了。
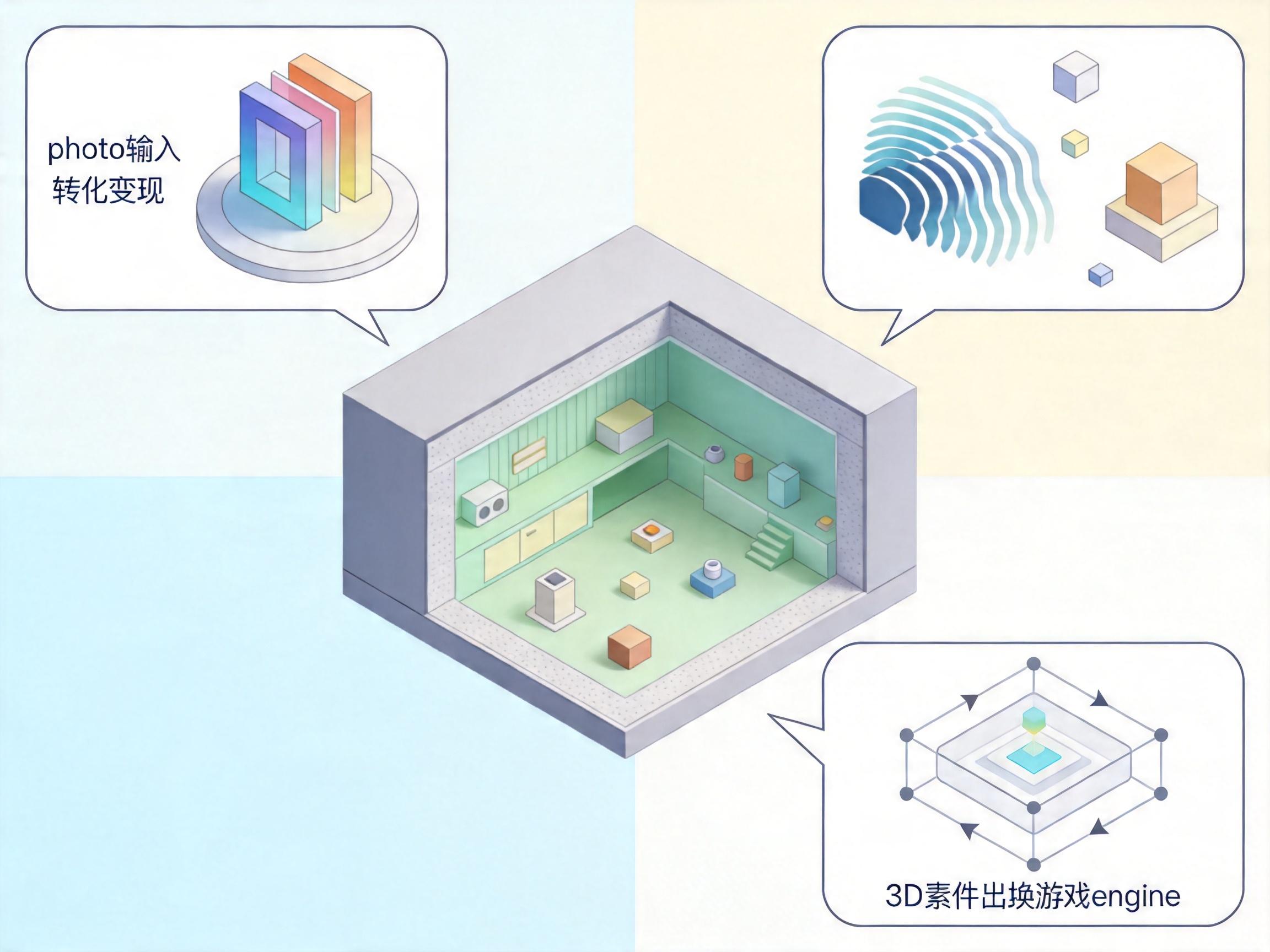
DeepMind的学习型仿真派干脆给AI造了个「平行宇宙」:输入一句「暴风雨里在威尼斯划船」,就能生成一个720p的可交互虚拟环境,你打碎的花瓶碎片会一直留在地上,走回来还能看见。但这个宇宙的物理规律是AI从视频里学来的,不如传统游戏引擎精确,而且只能维持几分钟的连贯。

英伟达扮演的是「卖铲子的人」:它的Cosmos平台能在14天内处理2000万小时视频,比CPU方案快了60多倍,还提供现成的预训练模型给开发者用——本质是用软件生态锁定自己的GPU硬件。而最「异端」的主动推断派,则从神经科学出发,让AI像人类一样用贝叶斯推理「猜世界」,遇到新东西时会先承认「我不确定」,而不是瞎猜一个答案。
世界模型的核心,是补上大语言模型的三个致命缺陷:不懂物理、没有空间感、不会预测后果。
第一道坎是「摆脱文本的牢笼」。大语言模型的训练数据是互联网上的文字,而真实世界是三维的、连续的、有重量的。你让它描述「杯子掉在地上」,它能写出「清脆的响声」,但它不知道杯子会碎,碎了会溅出水,水会在地板上形成水渍——这些都是文本里没写全的细节,却是人类不用想就知道的常识。
第二道坎是「把规律装进脑子里」。JEPA的思路最能体现这一点:它用编码器把视频转成抽象的数学向量,然后在这个向量空间里预测未来。比如看到一个球被推了一下,它不用预测每帧画面,直接就能输出「球会滚出画面」这个结论。这就像人类看球,不会去算每毫秒的位置,而是凭直觉知道它会往哪走。
第三道坎是「学会在错误里调整」。主动推断派的AI遇到没见过的物体时,会先给这个物体打个「不确定」的标签,然后通过观察和互动慢慢修正自己的判断——就像人类第一次见新东西时会先观察再动手。而大语言模型只会硬着头皮编一个答案,哪怕这个答案错得离谱。

但这些流派都有自己的死穴:JEPA的商业化要等好几年,空间智能派不懂物理,DeepMind的虚拟世界撑不了太久,英伟达的平台离不开它的硬件,主动推断派的生态太小众。
没人能确定哪个流派最终会成,但有一点很清楚:未来的通用AI,一定是融合了这些流派的长处。它会像JEPA一样懂抽象规律,像空间智能派一样能感知3D世界,像DeepMind的模型一样能在虚拟环境里练习,像主动推断派一样会学习和调整,还得靠英伟达的算力支撑运行。
2026年的这场竞赛,本质上是人类在给AI「造脑子」——不是造一个只会背课文的书呆子,而是造一个能感知、会思考、能行动的智能体。这个过程中,我们也在重新理解人类自己的智能:我们的大脑是怎么把眼睛看到的像素、耳朵听到的声音、皮肤摸到的温度,整合成一个连贯的世界模型的?我们的常识、直觉、判断力,到底是怎么来的?
现在的世界模型还只是一个个碎片,但这些碎片正在慢慢拼起来。也许用不了十年,我们就能看到一个能自己开门、拿杯子、倒水,还能理解「水会洒出来」的AI——到那时候,AI才算真正迈出了「懂世界」的第一步。
当大语言模型还在为写出一首好诗沾沾自喜时,世界模型已经在教AI理解「苹果为什么会落地」。这不是一场技术竞赛,而是人类在尝试给机器装上「常识」——这种我们生来就有,却从来没说清楚过的东西。
懂文本不算智能,懂世界才算。 未来的AI不会只是一个聊天框里的声音,它会成为一个能在真实世界里行动、感知、思考的存在。而我们现在做的,就是给这个存在打第一块地基。
点击充电,成为大圆镜下一个视频选题!