对抗知识焦虑,从看懂这条开始
App 下载
AI学会“换脑”思考?跨语言推理准确率暴涨12.7%
跨语言推理|新加坡科技设计大学|新加坡科技研究局|AdaMCoT框架|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载跨语言推理|新加坡科技设计大学|新加坡科技研究局|AdaMCoT框架|大语言模型|人工智能
想象一位学识渊博的学者,他能解答世间万物,却只精通一门语言。当面对一个用其他语言提出的、充满文化隐喻的诗歌难题,或是一个逻辑严密的数学挑战时,他会陷入困境:是生硬地翻译问题,冒着丢失精髓的风险?还是用自己不擅长的语言勉强作答,导致错误百出?这正是今天多语言大模型(MLLM)面临的窘境。
然而,这一困境正被悄然打破。来自新加坡科技研究局(A*STAR)和新加坡科技设计大学(SUTD)的联合研究团队,推出了一个名为**AdaMCoT(自适应多语言思维链)**的全新框架。这项已被人工智能顶级会议AAAI 2026接收为口头报告的突破性研究,不再强迫AI“说英语”,而是教会它一项更接近人类智慧的元技能:根据问题的性质,自适应地“换一种语言思考”。
长期以来,多语言AI的发展存在一种根深蒂固的“路径依赖”。要么,模型直接用接收到的语言(例如,资源较少的印度尼西亚语)进行推理,但这往往会导致知识储备不足,产生事实性错误和“幻觉”。要么,模型采取“一刀切”策略,将所有问题强制翻译成数据资源最丰富的英语进行处理,再翻译回原语言。这种方法在处理科学、逻辑类问题时或许有效,但当面对需要保留文化韵味或特定语义的任务(如创作中文对联或理解日语双关语)时,则会显得弄巧成拙,丢失语言的灵魂。
核心矛盾在于:没有一种语言是解决所有问题的万能钥匙。 英语的逻辑严谨性使其在科学推理中占据优势,而中文或马来语在处理特定文化背景或韵律任务时,则更具表现力。如何让AI摆脱这种非此即彼的僵化选择,像一个真正的多语言专家那样,为不同任务找到最顺手的“思维工具”?这正是AdaMCoT试图解答的问题。
AdaMCoT的精髓并非“先翻译再回答”,而是引入了一套优雅的自适应路由机制。它赋予模型一种动态决策能力,在两条推理路径之间智能切换:
跨语言思维链(Cross-Lingual CoT): 当模型判断输入的问题(比如一个用马来文提问的数学题)用原语言处理不够“顺手”时,它会自动启动“换语言思考”模式。模型会综合评估候选语言池(如英语、中文)的知识丰富度、主题一致性等因素,选择一个最合适的“思考语言”(如英语)展开一步步的链式推理,最终再将严谨的推理结果映射回马来文,生成精准的答案。
直接生成(Direct Generation): 对于模型本身就擅长的任务,或者那些与语言文化高度绑定的问题(如用特定语言写诗),模型会选择直接在源语言上进行思考和生成。这最大限度地避免了跨语言转换可能带来的语义损耗和文化韵味流失。
那么,模型如何“知道”何时该切换路径,又该选择哪种语言呢?研究团队为此设计了一套巧妙的基于奖励的微调机制。他们利用强大的GPT-4o作为“裁判”(奖励模型),对不同推理路径生成的答案,从事实正确性、逻辑连贯性、指令遵循度等多个维度进行打分。在训练过程中,模型只学习那些获得高分(≥9分)的“优秀路径”。通过这种“优胜劣汰”的强化学习,AdaMCoT逐渐内化出一种直觉,能够根据问题类型自动切换最优策略,实现了从“被动执行”到“主动思考”的跃迁。
理论的优雅最终需要数据的验证。研究团队在mTruthfulQA、Cross-MMLU等多个权威的多语言基准测试集上,对搭载了AdaMCoT框架的LLaMA 3.1和Qwen 2.5等主流开源模型进行了评估。结果令人振奋。
在衡量事实准确性的mTruthfulQA数据集上,LLaMA3.1-8B-AdaMCoT在测试的32种语言中,有31种都取得了性能提升。尤其对于长期处于AI技术洼地的低资源语言,效果更是惊人:
更重要的是,AdaMCoT不仅提升了答案的准确性,还显著增强了跨语言一致性。这意味着,无论用户使用哪种语言提问同一个事实性问题,模型都能调用其内部最核心、最一致的知识库来回答,大大减少了以往那种“见人说人话,见鬼说鬼话”的逻辑矛盾和幻觉现象。
“换语言思考”为何如此有效?为了揭开AdaMCoT工作原理的神秘面纱,研究团队动用了Logit Lens和UMAP两种前沿的可视化分析技术,仿佛为我们打开了AI的“思维天窗”。
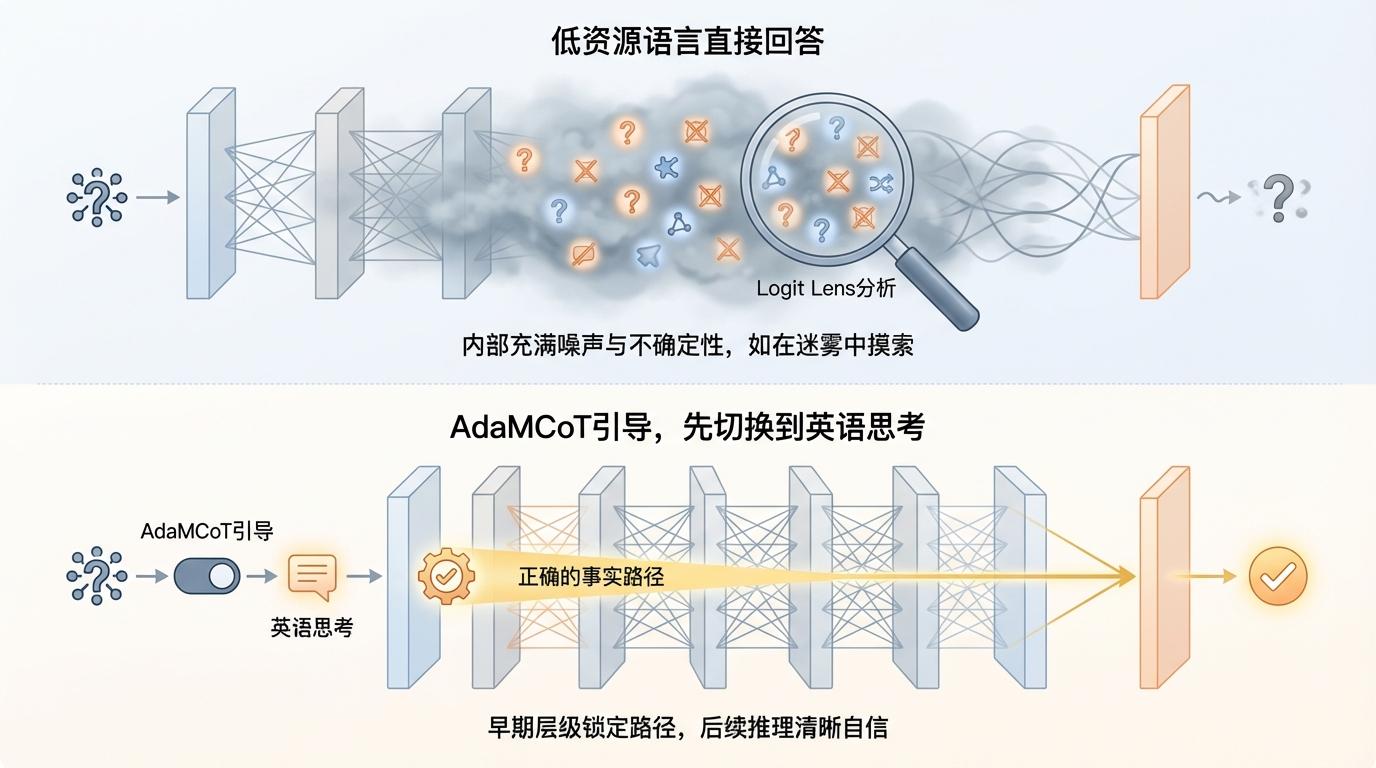
通过Logit Lens的分析,研究者发现,当模型被迫用低资源语言直接回答复杂问题时,其内部神经网络的中间层充满了大量的噪声和不确定性预测,如同在迷雾中摸索。而当AdaMCoT引导模型先切换到英语进行“思考”时,模型在非常早期的层级就能锁定正确的事实路径,后续的推理过程清晰而自信,最终生成的答案自然更加准确可靠。
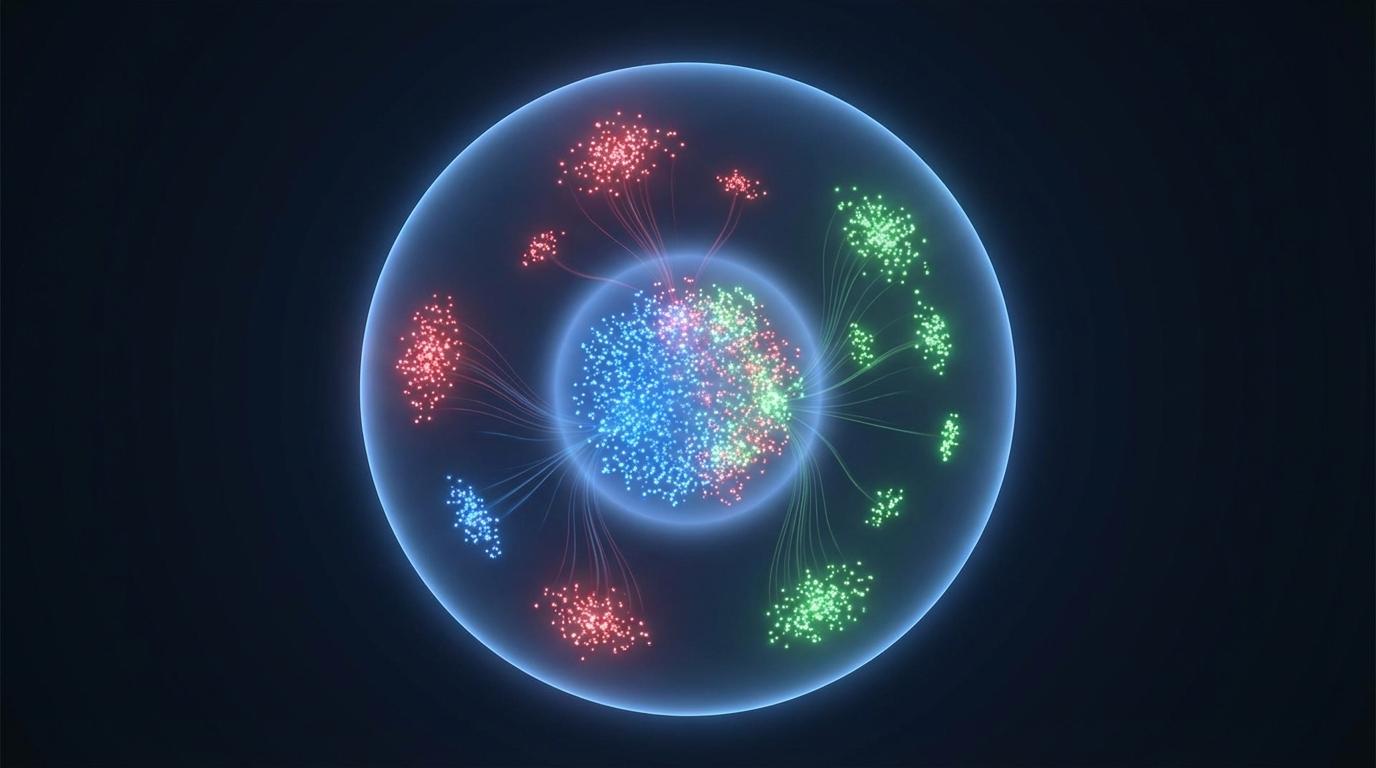
UMAP降维可视化则揭示了更深层次的变化。经过AdaMCoT微调后,不同语言在模型内部的语义空间发生了奇妙的“靠拢”。非英语语言的嵌入向量(Embeddings)显著地向英语的中心区域移动,但又没有破坏各自原有的语义结构。这表明,AdaMCoT促成的并非简单的表层翻译,而是多语言知识在语义层面的深度融合与对齐。模型学会了在同一个“通用知识空间”里理解和推理不同语言提出的问题。
AdaMCoT的提出,标志着多语言AI推理范式的一次重要革新。它没有依赖于更大规模的模型参数,也没有消耗海量的多语言预训练数据,仅仅通过教会模型“如何更聪明地选择思考语言”这一轻量级的方法,就成功释放了现有大模型的巨大跨语言潜能。
这项工作不仅为提升低资源语言的AI性能提供了一条低成本、高效率的路径,也为我们理解大模型内部跨语言知识如何对齐与互动,提供了全新的视角。在全球化日益深入的今天,语言不应再是获取信息和技术的壁垒。像AdaMCoT这样的技术,正是有望打破数字世界的语言隔阂,构建起一座座通往“AI普惠”的坚实桥梁,让智能的福祉真正触达每一个角落,每一种声音。