对抗知识焦虑,从看懂这条开始
App 下载
自动驾驶人才涌向机器人,补全具身智能最后一块拼图
数据闭环|技术人才流动|端到端模型|人形机器人|具身智能|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据闭环|技术人才流动|端到端模型|人形机器人|具身智能|人工智能
当一辆自动驾驶汽车稳稳停在你面前时,你可能不会想到,操控它的技术团队正集体转向另一个战场——人形机器人。2026年春,一位曾主导千万级用户智驾系统的技术负责人,正式加入一家机器人团队。这不是孤例:过去两年,至少20位车企智驾核心骨干转投具身智能赛道。他们带着数据闭环、端到端模型、量产落地的成熟经验,要解决的是机器人从“能走会跳”到“能干活”的关键难题。这场跨领域迁徙的背后,是具身智能行业最迫切的需求:把分散的技术链条拧成一股能落地的力量。
你可以把传统机器人的决策模式想象成“看一步走一步”——摄像头每拍一帧画面,就传给AI分析,再输出一个动作指令。这种“逐帧推断”的方式就像人走路时每一步都要停下来想“迈哪只脚”,不仅延迟高(单帧总延迟约249毫秒),还会让AI消耗98%的算力在重复思考上,根本没法应对复杂的实时任务。
端到端的视觉-语言-动作(VLA)模型试图打破这个困局。它就像给机器人装了个能“预判未来”的大脑:不再逐帧分析,而是直接从原始传感器数据(视觉、语言指令)里,一次性预测出未来几秒的连续动作轨迹。比如接到“拿起杯子”的指令,它能直接规划出“伸手-握杯-抬起”的完整动作序列,而不是走一步看一步。
但这不是简单的“一步到位”。现实中,端到端模型会遇到“大脑想得出,身体做不到”的问题——AI规划的动作轨迹,机器人的关节和电机没法实时跟上。于是分层控制成了必要的折中:高层用大语言模型做任务规划,中层生成具体动作轨迹,底层用专用控制器实时执行,既保留了端到端的高效,又保证了动作的稳定性。
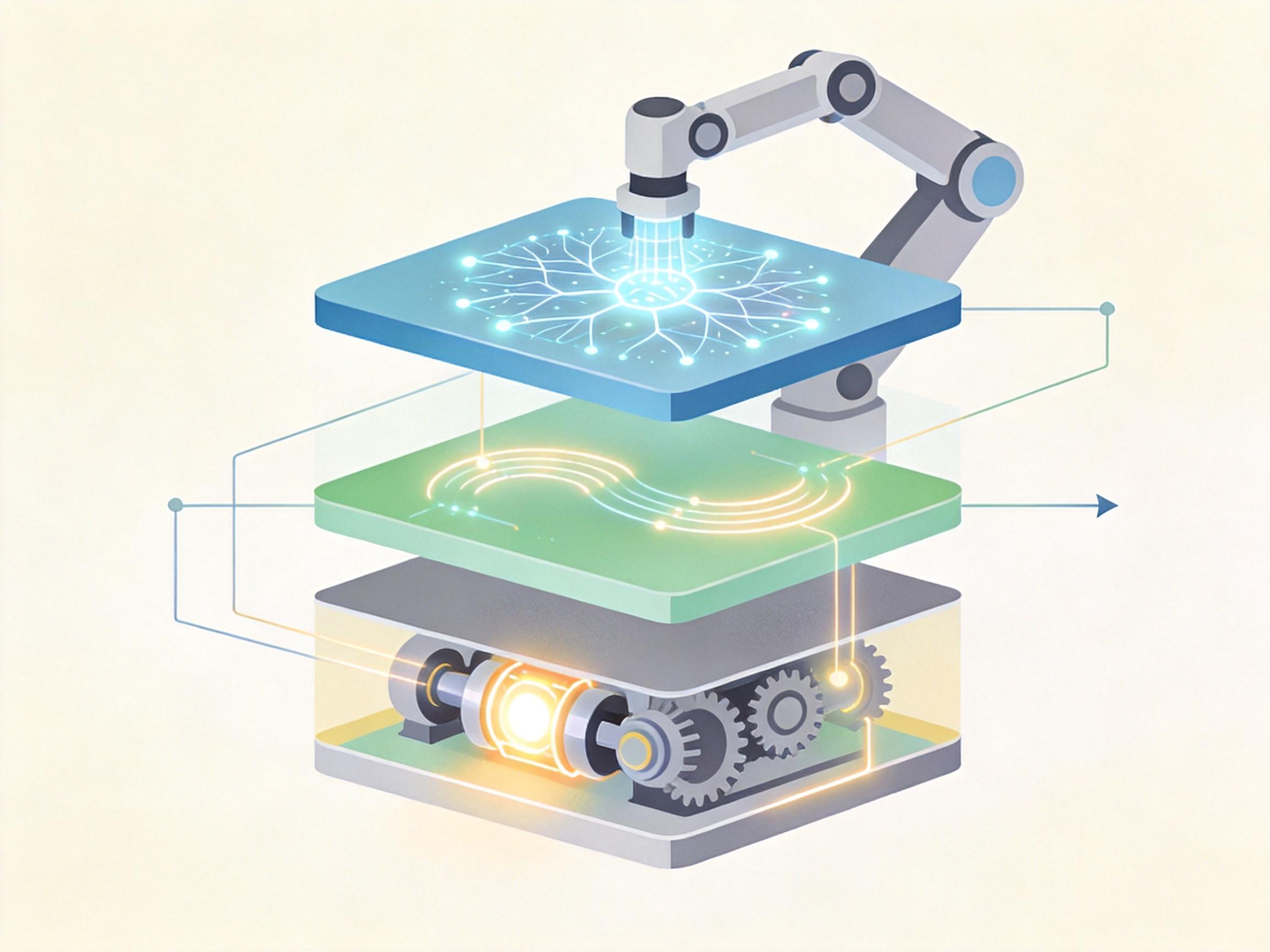
如果说端到端模型是机器人的“大脑”,数据飞轮就是让这个大脑持续进化的“营养循环”。这个从自动驾驶领域迁移来的逻辑很简单:机器人在真实环境中运行,会不断产生感知和动作数据;这些数据被送回训练平台,优化模型;优化后的模型再通过OTA远程更新到机器人上,让它下次做得更好——形成“数据采集-模型训练-部署迭代”的闭环。
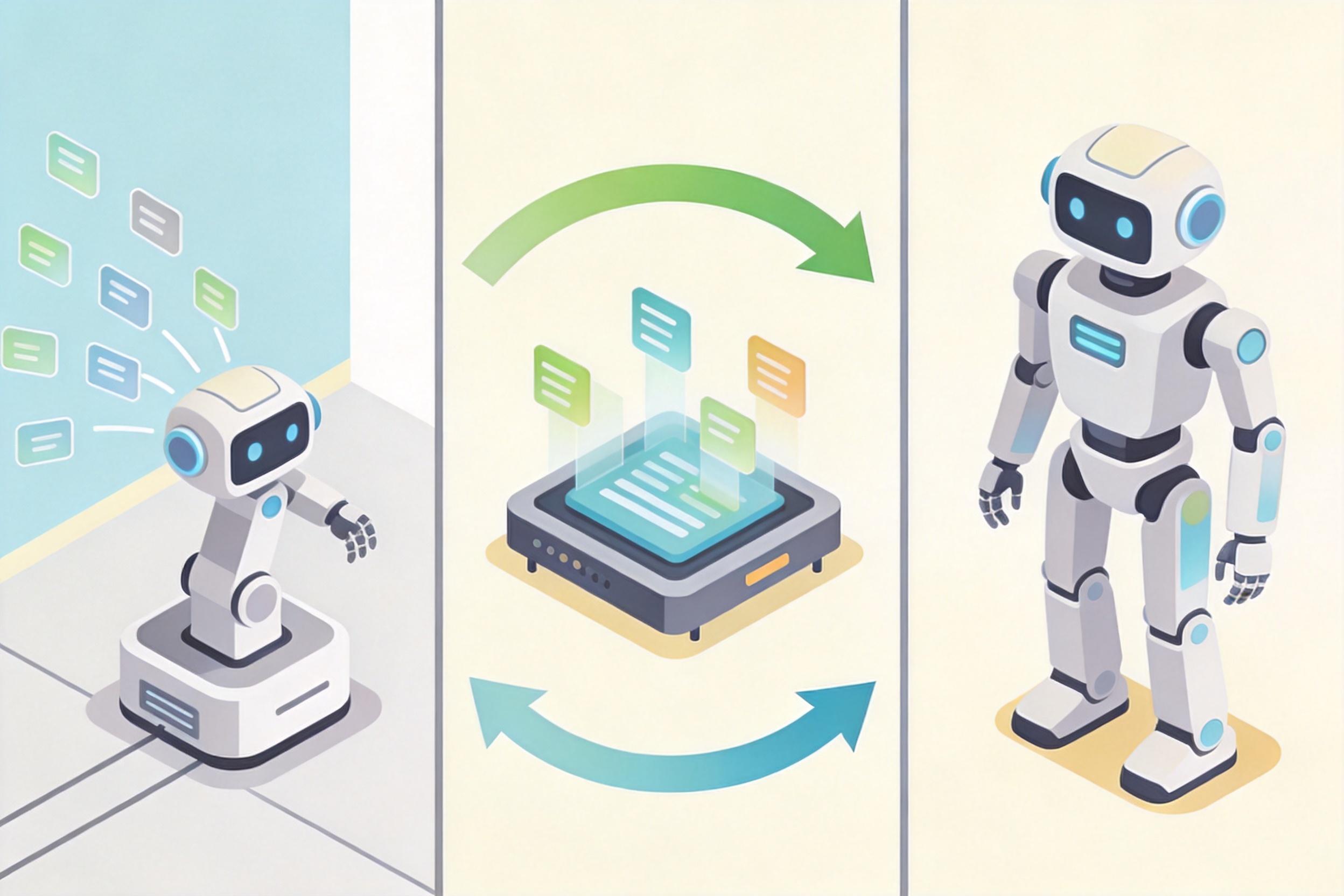
比如自动驾驶团队靠百万级车队积累的道路数据,能让智驾系统不断优化识别路况的能力。现在这套逻辑被用到机器人上:一台在工厂里搬运零件的机器人,每一次抓取、每一次移动都会生成数据,这些数据能帮它学会应对不同重量、不同形状的零件,甚至适应地面的轻微磨损。
但机器人的数据飞轮比自动驾驶更难转。自动驾驶面对的是结构化的道路,而机器人要应对的是五花八门的生活场景,数据采集成本高、标注难。于是仿真技术成了关键:在数字孪生环境里,机器人可以模拟十万次抓取动作,生成的仿真数据能大幅降低对真实数据的依赖。有团队靠这种方式,把机器人从仿真到现实的迁移成功率提升了29%。
具身智能的终极难题,从来不是某一项技术的突破,而是从机械结构、传感器,到感知算法、决策模型的全链条协同。就像人要完成“拿杯子喝水”的动作,需要骨骼、肌肉、眼睛和大脑的配合,机器人的硬件和软件也必须像一个整体一样工作。
过去很多机器人团队要么偏硬件,把机器人做得“能走会跳”却不会干活;要么偏软件,AI模型能规划复杂动作,却找不到能执行的硬件。而自动驾驶团队带来的全栈经验,恰恰补上了这块短板:他们懂怎么让传感器数据实时传给AI,懂怎么让AI的指令精准控制电机,更懂怎么通过OTA让硬件和软件一起迭代。
比如有团队设计了一套软硬件协同的框架,把AI的轨迹预测和硬件的实时控制结合起来,不仅把AI的推理频率降低了8倍,还让机器人的动作速度提升了3.6倍,成功率提高了17.3%。这种协同不是“软件适配硬件”或者“硬件迁就软件”,而是从设计之初就把两者当成一个整体来考虑。
当自动驾驶人才带着成熟的技术体系涌入机器人赛道,我们看到的不是简单的跨界跳槽,而是具身智能从实验室走向真实世界的关键一步。这些曾让汽车学会“自己开车”的工程师,现在要让机器人学会“自己干活”——不是在镜头前表演翻跟头,而是在工厂里搬运零件、在医院里递送药品、在家庭里帮忙做家务。
智能从来不是孤立的大脑,而是身体、感知和决策的完整闭环。这正是具身智能最迷人的地方:它不是让AI模仿人类的思考,而是让机器像人类一样,用身体去感知世界,用经验去适应环境。
智能的终极形态,是身体与大脑的共生。