
1 天前
1 天前
你让AI根据一张折线图生成代码,它敲出的程序运行后,坐标轴标签挤成一团,颜色也和原图完全不符。你把结果反馈给它,要求修改——但多数大模型要么输出更混乱的代码,要么干脆重复之前的错误。这不是某款模型的缺陷,而是当前多模态AI的普遍困境:它们能‘写代码’,却不会‘改代码’。直到亚马逊AGI团队的MM-ReCoder出现,这个70亿参数的小模型不仅能生成图表代码,还能像人类程序员一样反复调试优化,甚至在多项测试中追平了GPT-4o这类千亿参数的巨无霸。它是怎么做到的?
MM-ReCoder的训练逻辑像极了人类学编程:先打基础,再练调试。
第一步是‘冷启动’——用16万对‘图表-代码’数据做监督微调,让模型先学会最基本的‘看图写代码’能力,就像新手先背熟语法和例题。但光会写还不够,它得知道‘怎么改’。研究团队用2350亿参数的超大模型自动生成了一批‘错误代码-反馈-修正代码’的对话样本,过滤掉那些越改越差的无效案例,再用这些高质量的‘改题范本’微调模型,让它先看懂‘正确的修正逻辑是什么’。
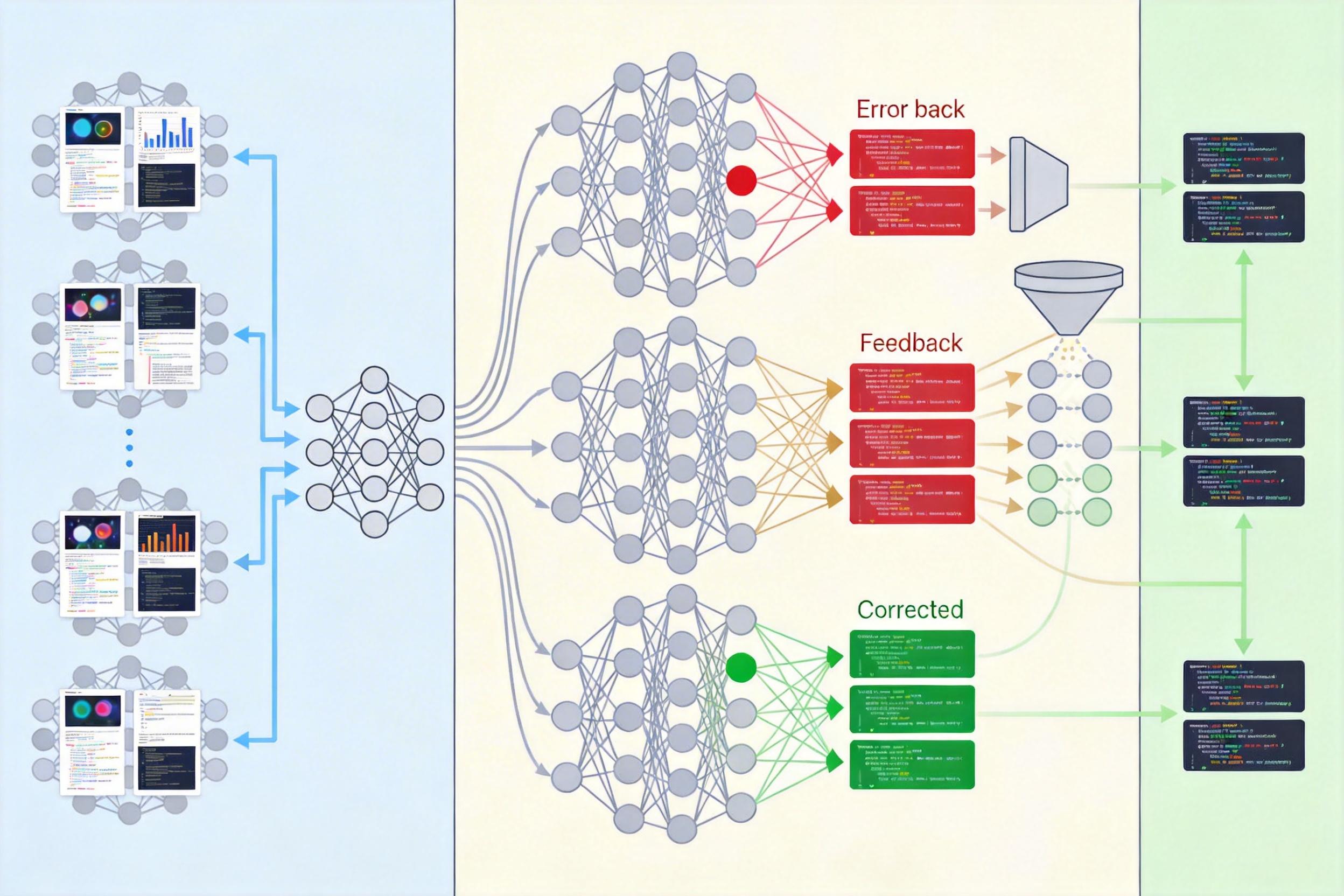
这两步走完,模型已经能模仿修正的格式,但还不理解‘为什么要这么改’。真正的突破,来自后续的两阶段强化学习。
研究团队没有直接让模型自由迭代,而是拆成了两个针对性的强化学习阶段,用的是一种叫GRPO的算法——简单说,就是让模型生成多个修改方案,在小组里‘比拼’,比平均水平好的就给奖励,差的就调整策略,比传统算法更稳定。
第一阶段是‘共享首轮优化’:固定一段有缺陷的初始代码和它的运行结果,让模型围绕这个‘错题’生成8种不同的修正方案,只优化这些修正方案。这相当于把模型按在‘错题本’前,强制它专注于‘怎么从错误中修正’,而不是重新写一份新代码。
第二阶段是‘全轨迹优化’:放开限制,让模型独立生成从‘初始代码’到‘修正代码’的完整流程,优化整个创作轨迹。这时候模型已经学会了‘改’,现在要练的是‘一开始就尽量写好’,同时保留修正的能力。
两个阶段结束后,模型就成了既能一次生成高质量代码,又能反复迭代优化的‘全能选手’。
强化学习的核心是‘奖励什么,模型就会往什么方向走’。MM-ReCoder用了三重奖励机制,既抓细节,又保美观。
第一重是‘规则奖励’:通过拦截图表渲染的底层数据,精确对比生成图和原图的类型、文字、颜色、布局等细节,确保代码在功能上完全正确——但它管不了‘文字重叠’这种‘看起来不好但技术上合规’的问题。
第二重是‘模型奖励’:用720亿参数的多模态模型当‘评委’,从图表类型、布局、清晰度等6个维度打分,补上规则奖励的盲区,惩罚那些‘技术正确但视觉糟糕’的输出。
第三重是‘格式奖励’:鼓励模型先输出<think>思考过程</think>再写代码,强化它的逻辑推理习惯。
三者加权结合,就成了驱动模型进化的‘指挥棒’。在ChartMimic等三个主流测试集上,这个70亿参数的小模型不仅远超同规模对手,还在多项指标上追平了GPT-4o。更关键的是,在‘初始代码已可运行,只需优化质量’的高难度测试中,它是唯一一个越改越好的开源模型——其他模型要么原地踏步,要么越改越差。
MM-ReCoder的突破,本质上是让AI学会了‘对自己的输出负责’。过去的多模态AI更像‘一次性打字机’,而现在它开始拥有‘程序员的思维’——不是靠记忆例题,而是靠反馈迭代。
当然它也有局限:目前只能处理Matplotlib图表,奖励计算依赖大模型导致成本较高,还不会用静态代码分析工具找深层错误。但它证明了一件事:参数规模不是AI能力的唯一决定因素,训练方法的创新,能让小模型爆发出意想不到的能量。
小模型的未来,在于学会自我进化。
点击催更,成为大圆镜下一个视频选题!