对抗知识焦虑,从看懂这条开始
App 下载
AI学大脑只在犯错时学习,能耗降八成
能耗优化|参数更新|节能学习机制|诺丁汉大学|脑科学|大语言模型|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载能耗优化|参数更新|节能学习机制|诺丁汉大学|脑科学|大语言模型|心理认知|人工智能
你有没有过这种体验:打字拼错一个词,手指会下意识顿一下,那瞬间的注意力比打对一整段都集中?这不是矫情,是刻在基因里的节能本能——大脑只把能量花在「错误」上。而现在的AI训练,就像个不管对错都在瞎忙活的愣头青:哪怕已经能准确识别猫和狗,每喂一张图它都要全量更新参数,白白浪费算力和电力。英国诺丁汉大学的研究者突然反问:如果让AI学大脑,只在犯错时才「动真格」,会发生什么?结果让人意外——参数更新次数最多能砍去80%,模型性能却丝毫不打折。
你可能没意识到,学习是件极度耗能的事:果蝇学会避开危险后,挨饿时会比没学过的同类早死20%;人类大脑只占体重2%,却要耗掉全身20%的能量。为了活下去,大脑进化出了一套「抠门」的学习规则:只有当你犯错时,它才会启动高强度学习模式。
神经科学家早就发现,人犯错的瞬间,大脑前扣带皮层会产生一个叫「错误相关负波」的电信号——就像触发了一个警报,多巴胺迅速释放,神经突触开始调整连接,确保你下次不再犯同样的错。而那些你已经做对的事,大脑会直接「忽略」,绝不浪费能量重复巩固。
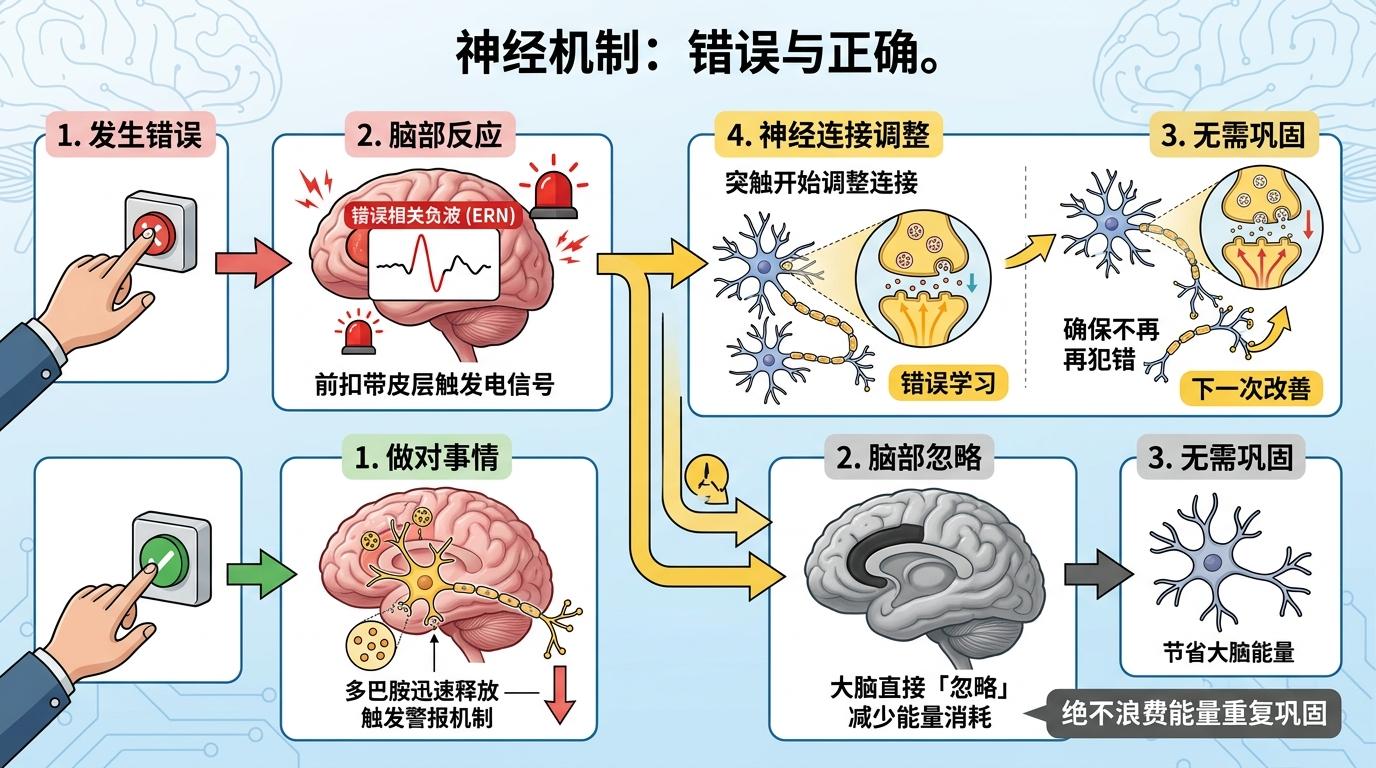
这背后的逻辑很残酷:对生存来说,记住「哪里错了」远比重复「哪里对了」重要得多。而现在的AI训练,完全违背了这个逻辑。
诺丁汉大学的研究者把大脑的「错误优先」机制,翻译成了一套极简算法——「记忆化错误门控」。
它的核心操作简单到离谱:只需要一个和数据集样本数一样大的布尔数组,用来标记哪些样本「曾经被模型分错过」。每次训练时,只有两种情况会触发参数更新:一是当前样本被分错了,二是这个样本在历史上被分错过。
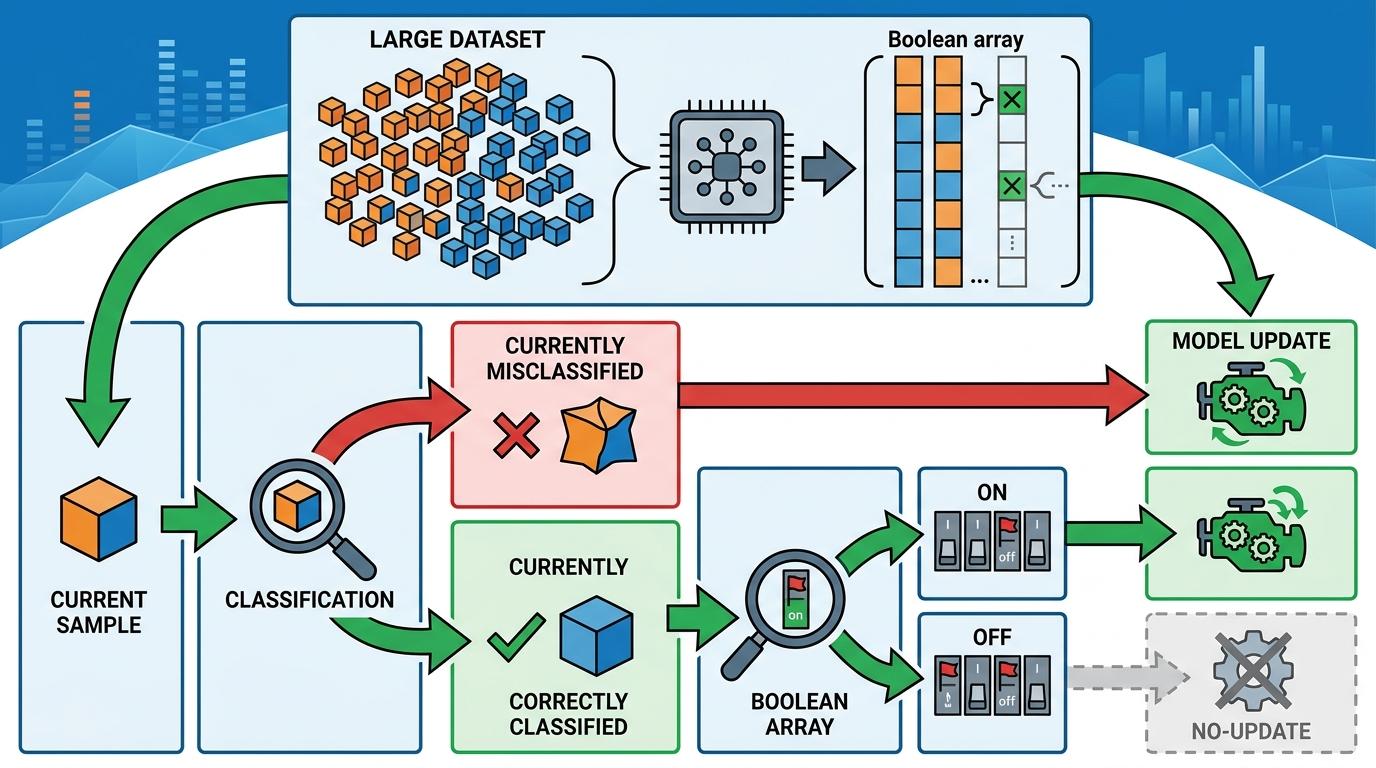
你可以把它想象成一本错题本:AI第一次做错的题会被记下来,之后每次遇到这道题,哪怕这次做对了,也会再复习一遍。对比之下,传统训练就像不管会不会,每道题都要重新做一遍。
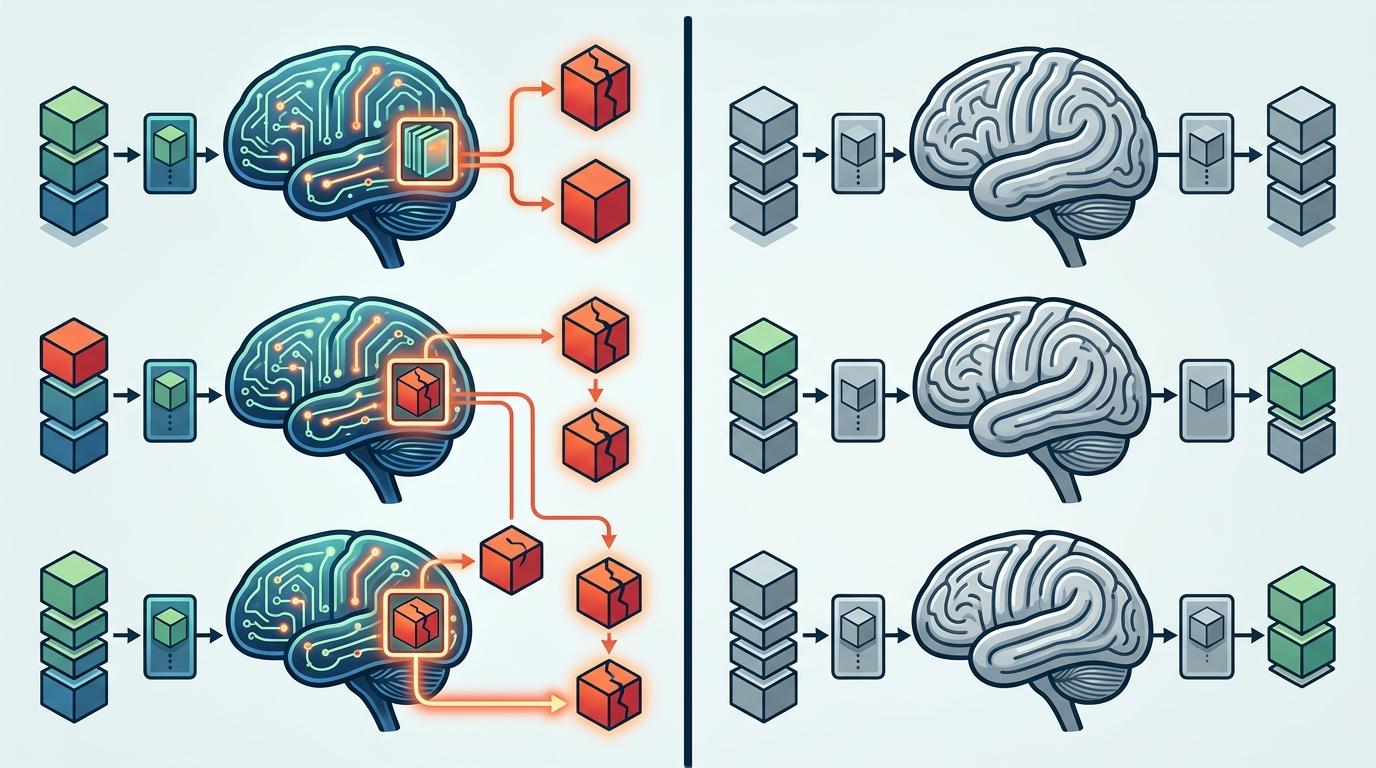
在MNIST手写数字识别实验中,这套算法把参数更新次数降到了传统方法的20%-50%,达到97%的测试准确率所需的步数更是大幅减少;在更大规模的EMNIST数据集上,需要存储的「关键错误样本」随数据集规模呈亚线性增长——数据集扩大100倍,存储需求只增加10倍。
当然,这套算法也不是没有软肋。它最大的局限,恰恰是现代AI训练最依赖的「批处理」机制。
现在的GPU训练都是按「批次」计算的,一个批次里只要有一个样本需要更新,整个批次的梯度都要计算更新。随着训练推进,模型准确率越来越高,一个批次里全是正确样本的概率越来越低,这就会让「错误门控」的节能优势被大幅削弱。
研究者也提出了可能的解决方案:动态构建只包含错误样本的批次。但这需要额外的工程调度,比如提前把样本按是否被分过错分类,训练时只取错误样本批次。这在技术上可行,但会增加系统复杂度。
更重要的是,这套算法在训练初期效果有限——毕竟一开始模型几乎全错,相当于还是在全量更新。但在模型已经有一定基础的增量学习场景,比如机器人不断学习新环境,或者边缘设备持续接收新数据时,它的优势就会彻底显现。
当我们还在追求更大的模型、更多的数据时,诺丁汉大学的研究给了一个反方向的提醒:有时候,向自然学习「少做什么」,比「多做什么」更重要。
大脑用了几百万年进化出的节能逻辑,其实在告诉我们:真正高效的学习,从来不是无差别地接收所有信息,而是精准抓住那些能让你进步的「错误」。这对AI适用,对我们自己也一样。
少做无用功,才是最高效的努力。