对抗知识焦虑,从看懂这条开始
App 下载
科研不再靠熬时间,国家竞赛拼工业化速度
国家级战略|科研工业化|创世纪计划|蛋白质结构预测|AlphaFold2|公共政策|AI产业应用|社会人文|人工智能
对抗知识焦虑,从看懂这条开始
App 下载国家级战略|科研工业化|创世纪计划|蛋白质结构预测|AlphaFold2|公共政策|AI产业应用|社会人文|人工智能
2020年,DeepMind的AlphaFold2把困扰生物学界50年的蛋白质结构预测,从“耗时数月的实验室攻坚”压缩到“秒级出结果”——这不是单点技术突破,而是一场科研范式革命的发令枪。当AI能自动生成假设、设计实验、分析数据甚至撰写论文,科学研究正从少数天才的“手工活”,变成算力驱动的“工业化流水线”。2025年,这场革命彻底越过技术边界,成为大国间的核心竞争武器。美欧英几乎同时砸下国家级战略,目标只有一个:谁先把科研体系彻底工业化,谁就锁定下一代产业的主导权。
美国直接搬出了“曼哈顿计划”的架势。2025年启动的“创世纪计划”,把全国17个国家实验室、企业和学术资源拧成一股绳,要在10年内让美国科学生产力翻倍。他们拆监管、砸算力、整合数据,甚至让机器人在8天内完成688次聚变实验——这效率是人类科研团队的数十倍。本质上,美国要的是“集中式工业化”,用算力和数据的垄断优势,拉开和其他国家的科研效率代差。
欧盟则走了另一条路。在严监管的《人工智能法案》基础上,他们推出RAISE体系,要建一个“泛欧洲科研操作系统”:共享算力、统一数据标准、培养跨学科人才,还要输出“可信AI”的全球标准。欧盟不拼速度极限,而是用规则和协同筑造长期壁垒,走的是“合规型工业化”路线。
英国选择了“精英化工业化”:攥紧有限资源,只砸生物医药、先进材料、核聚变这些高回报领域。利物浦的材料创新工厂里,机器人自主完成实验;Isambard-AI超算专门服务前列腺癌筛查和痴呆症研究。他们要靠高ROI的科研项目,维持自己在全球科学圈的话语权。
科研工业化的本质,是把“提出问题-验证假设-得出结论”的全流程,拆解成标准化、可重复、可自动化的环节。这背后靠的是四个关键机制:
首先是一体化算力平台。像美国的NAIRR平台,把云计算、GPU算力、数据集和AI模型打包成公共资源,科研团队不用再自己攒设备,按使用量付费就行——就像用工业流水线的共享车间,不用自己建工厂。宾夕法尼亚大学用类似平台,把免疫健康数据的分析时间从3天压缩到了数分钟。
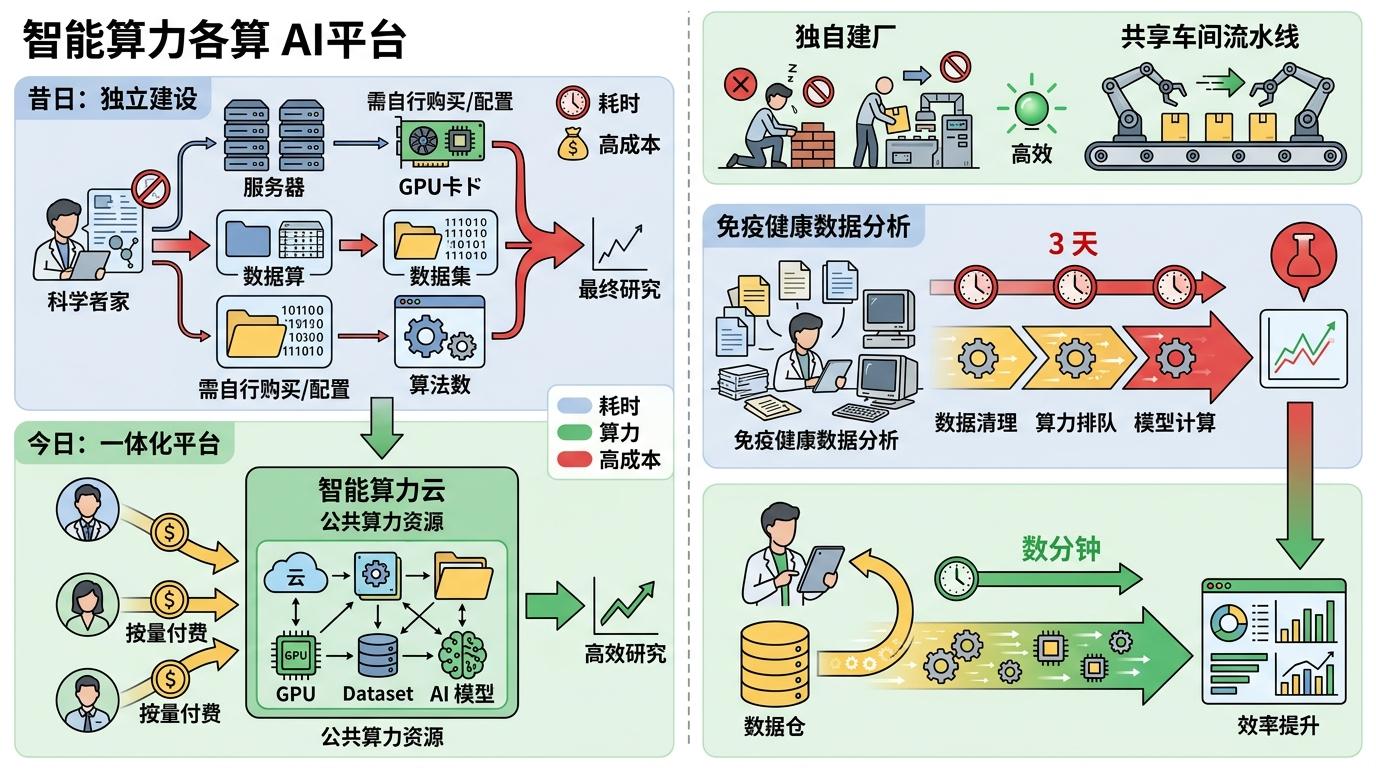
其次是大规模高质量数据集。现在科研数据动辄以PB计,传统下载分析早已过时,“让计算靠近数据”成了趋势。欧洲的RI-SCALE项目建了“数据利用平台”,让AI直接在数据环境里训练,既保证了数据安全,又避免了冗余传输。
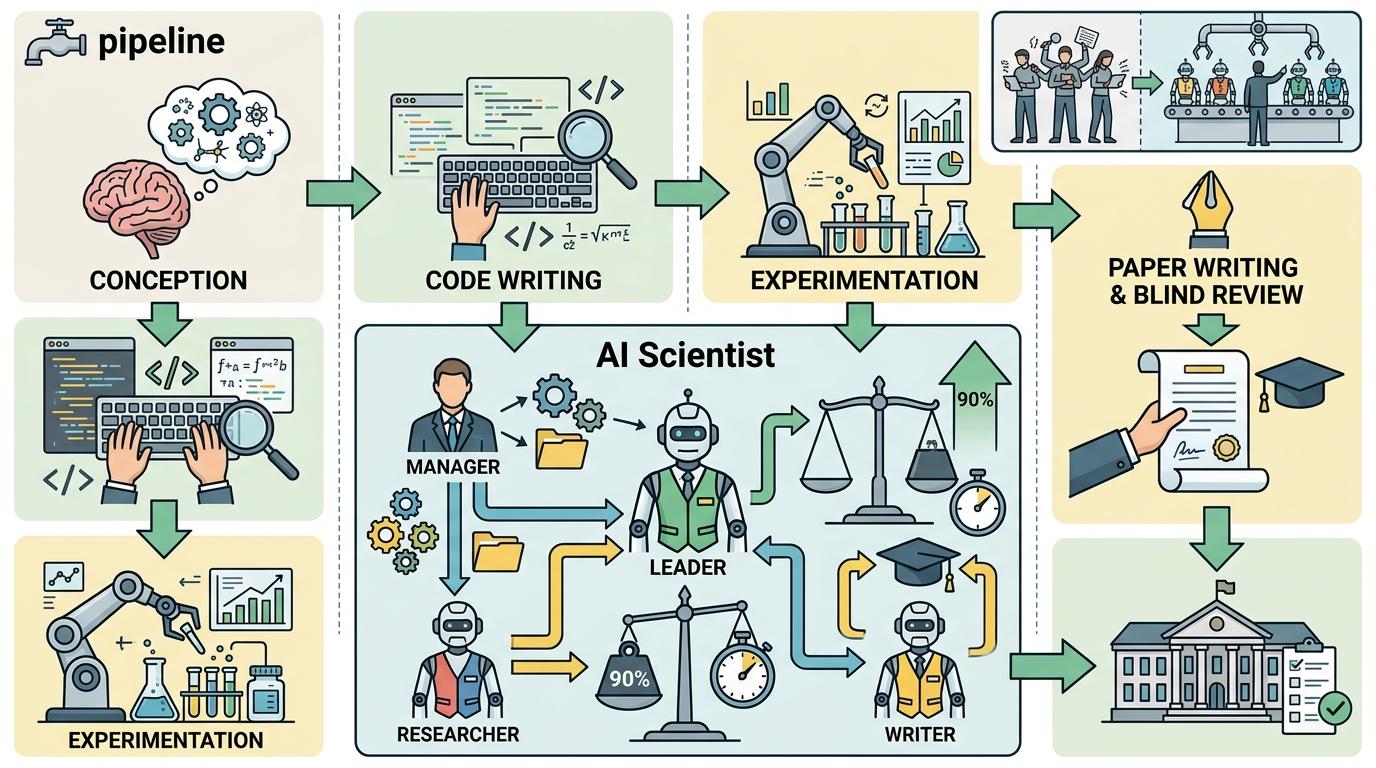
第三是AI多智能体系统。比如“AI科学家”系统,能自动完成从构思、写代码、做实验到写论文的全流程,甚至能通过顶级学术会议的盲审。它就像一个科研流水线的“智能厂长”,分解任务、调配资源、并行推进,效率比单个人类科研团队高90%。
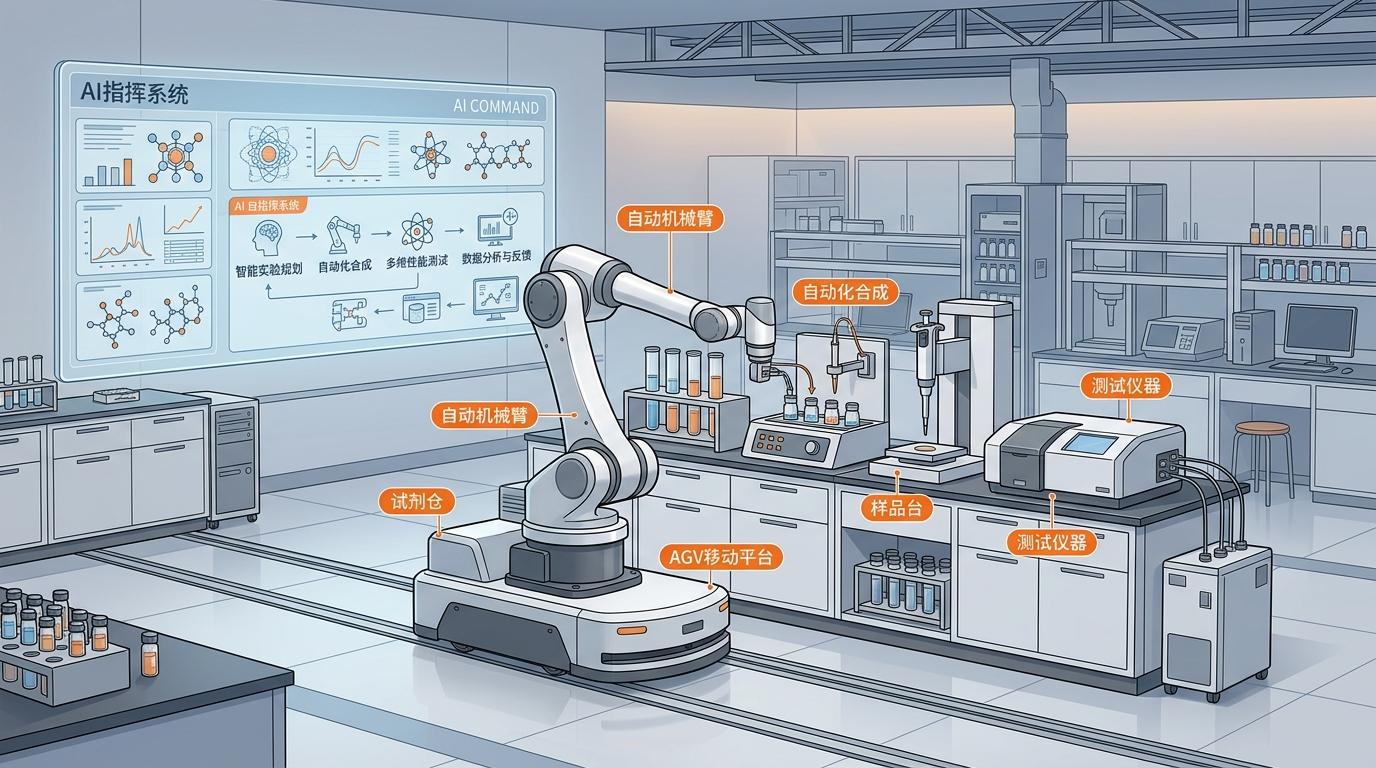
最后是自动化实验室。美国阿贡国家实验室的自驱动实验室,机器人在AI指挥下自主合成材料、测试性能,把达到结论所需的实验次数缩减了30倍。未来的科研,人类负责提出好奇的问题,AI和机器人负责把答案跑出来。
在这场竞赛里,中国的位置有点特殊:我们在机器人制造、AI应用场景上有优势,但在高端芯片、核心算法、高质量数据集上还被卡着脖子。不过更关键的挑战,其实不是技术差距,而是科研机制的效率。
我们有全世界最多的科研人员和研发投入,但企业的R&D效率偏低,基础研究占比还赶不上美国;地方政府的碎片化竞争,导致科研资源重复建设;学术评价体系还在盯着论文数量,跨学科的创新很难冒头。
更现实的是,当美国用国家工程的方式整合资源,欧盟用统一规则协同27国,我们需要解决的是:如何把分散的科研力量拧成一股绳,从“点状突破”转向“系统性工业化”。比如我们的ScienceOne 100平台已经在做跨学科科研,但要真正追上美欧的效率,还得在数据共享、人才流动、产学研协同上动真格。
当AI把科研变成流水线,科学发现的速度第一次和国家竞争力直接挂钩。过去,我们说“科学无国界”,但现在,科研体系的工业化水平,正在成为划分科技阵营的新边界。
未来的科研竞争,比的不是谁能偶尔爆出一个“黑科技”,而是谁能持续、稳定、高效地输出新发现——从提出问题到拿到答案,谁的时间更短。这就是科研工业化的本质:速度决定话语权,效率定义竞争力。
对中国来说,这场竞赛的核心不是追着买芯片、抄算法,而是要造出自己的“科研流水线”。毕竟,在工业化的时代,手工活再精巧,也赶不上流水线的产量。