对抗知识焦虑,从看懂这条开始
App 下载
AI终于学会像人一样边听边聊天了
实时语音交互|语音信号处理|语音助手|端到端全双工语音模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载实时语音交互|语音信号处理|语音助手|端到端全双工语音模型|多模态视觉|人工智能
当你在嘈杂的咖啡馆里对着语音助手说话,它能精准过滤掉邻座的交谈和咖啡机的轰鸣,还能在你话音刚落的瞬间接话——甚至在你中途打断它时,立刻停下调整回应。这不是科幻场景,而是端到端全双工语音模型带来的真实体验。
传统语音交互像一条流水线:先把你的声音转成文字,再让AI读懂文字生成回复,最后把文字转回语音。每多一道工序,就多一分延迟,也多一分丢失语气、情绪这些细腻信息的可能。端到端模型则像一个直接对接的联络员,从你开口的第一秒就接收完整的语音信号,跳过所有中间转换,直接生成语音回复。这不仅把延迟压缩到了人类对话的自然区间,还能完整捕捉你说话时的停顿、语调,甚至背景里的环境线索。
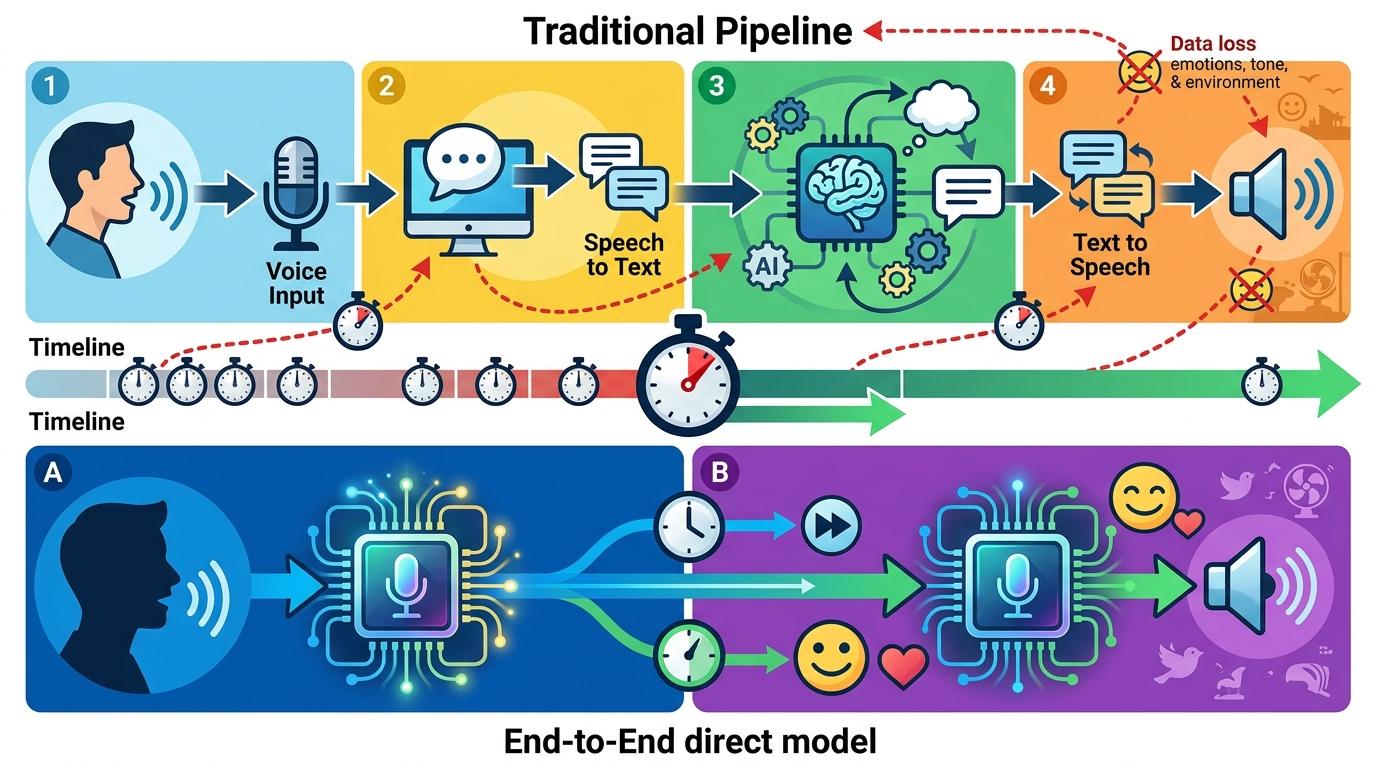
全双工是让对话真正自然的另一把钥匙。以前的语音助手像个守规矩的听众,必须等你说完所有话才敢开口,就像开会时必须举手发言。而全双工模型能同时“听”和“说”:你可以在它解释问题时突然插话提问,它会立刻停下,顺着你的新问题回应;甚至你只是“嗯”了一声表示在听,它也能读懂这个信号,继续流畅地说下去。这种同步交互,才是人类对话的真实状态。

要实现这一点,模型得解决两个核心难题:一是在重叠的语音里准确区分“谁在说话”“哪部分是给我的指令”。实验室数据显示,优秀的全双工模型能把嘈杂环境下的误触发率降低50%以上,即便是身边有人在念旁白,也能精准抓住你的提问。二是把响应延迟压到极致——人类自然对话的回应间隔通常在300毫秒到1秒之间,现在的全双工模型已经能做到平均500毫秒内回应,部分场景下甚至能缩短到250毫秒。
更值得关注的是,这种技术突破正在打破语音助手的“工具属性”。当AI能听懂你的情绪,能跟上你随时跳转的话题,它就不再只是个执行命令的机器,而可能成为能陪你模拟吵架练逻辑、能顺着你的语气哄人的“对话伙伴”。当然,它也还有局限:比如面对极其复杂的方言或口音,识别准确率仍有提升空间,在多轮长对话中偶尔也会丢失上下文。
从必须字正腔圆地下命令,到能像和朋友一样随意聊天,语音AI的进化,本质上是在向人类的沟通方式靠拢。未来它或许会走进更多场景:在车里帮你边导航边聊路况,在医院里陪老人边做康复边拉家常,在厨房里听你念叨菜谱的同时调整火候。技术的终极目标,从来不是让机器更像机器,而是让机器懂人,懂人类最自然的沟通本能。