对抗知识焦虑,从看懂这条开始
App 下载
FID从裁判变教练,单步生成器追平多步效果
生成模型训练|USC团队|图像生成质量|单步生成器|FID指标|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载生成模型训练|USC团队|图像生成质量|单步生成器|FID指标|多模态视觉|人工智能
想象一下:你练了十年短跑,每次比赛都有个裁判在终点打分,但他从来不会下场教你怎么摆臂、怎么蹬地——这就是过去十年生成模型领域的“金标准”FID的处境。它是所有顶会论文的“入场券”,是衡量图像生成质量的终极裁判,却只能在训练结束后冷冰冰地给出分数,永远碰不到训练的核心流程。直到2026年4月,来自USC、CMU、CUHK和OpenAI的团队把这个裁判拉下了席——他们让FID直接变成了训练模型的教练,甚至把原本要跑200步的生成模型,硬生生改造成了一步就能冲线的飞人。
要理解这次突破,得先搞懂FID到底是什么。你可以把它想象成一场“图像选美比赛”:先用一个叫Inception-v3的预训练模型当“评委”,给每一张真实图像和生成图像打一个2048维的“特征分”——这个分数里藏着图像的颜色、纹理、物体结构所有关键信息。然后计算真实图像的“平均分”和“分数波动范围”,再算出生成图像的对应数据,最后用Fréchet距离公式衡量两组数据的差距,这个差距就是FID值,越低说明生成图像越像真的。
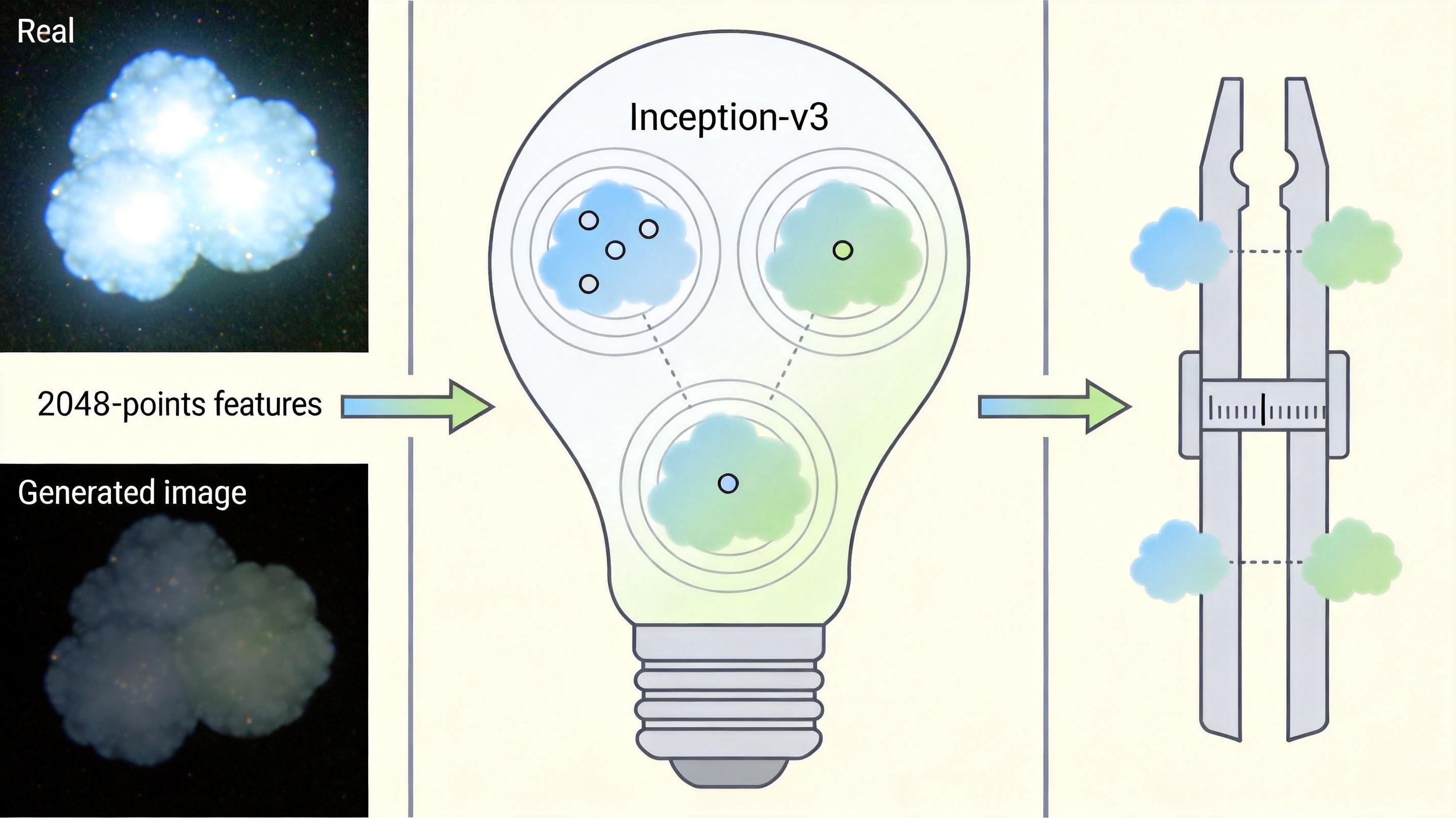
但FID当不了教练的核心矛盾,就藏在这个计算里:要得到稳定的“平均分”和“波动范围”,它需要至少5万张图像的大样本;但训练模型时,每次只能喂进去几百到上千张的小批量——用这么小的样本算出来的FID,噪声大到能把模型带偏,甚至越练越差。过去十年,所有人都在围着FID的分数转,却没人能解决这个“样本量矛盾”。
这次研究的核心解法,说穿了就是“拆分工”——把FID需要的“大样本统计”和训练需要的“小批量梯度计算”彻底分开。
他们设计了两种实现方式:一种是“队列法”,就像给FID专门建了一个能装5万张图像特征的“大数据库”,每次训练新生成一批图像,就把它们的特征放进数据库,同时删掉最老的一批,用整个数据库的特征来计算稳定的FID值,但只让当前这批图像的特征参与梯度更新——相当于裁判拿着过去所有选手的打分表给指导,但只纠正当前选手的动作。
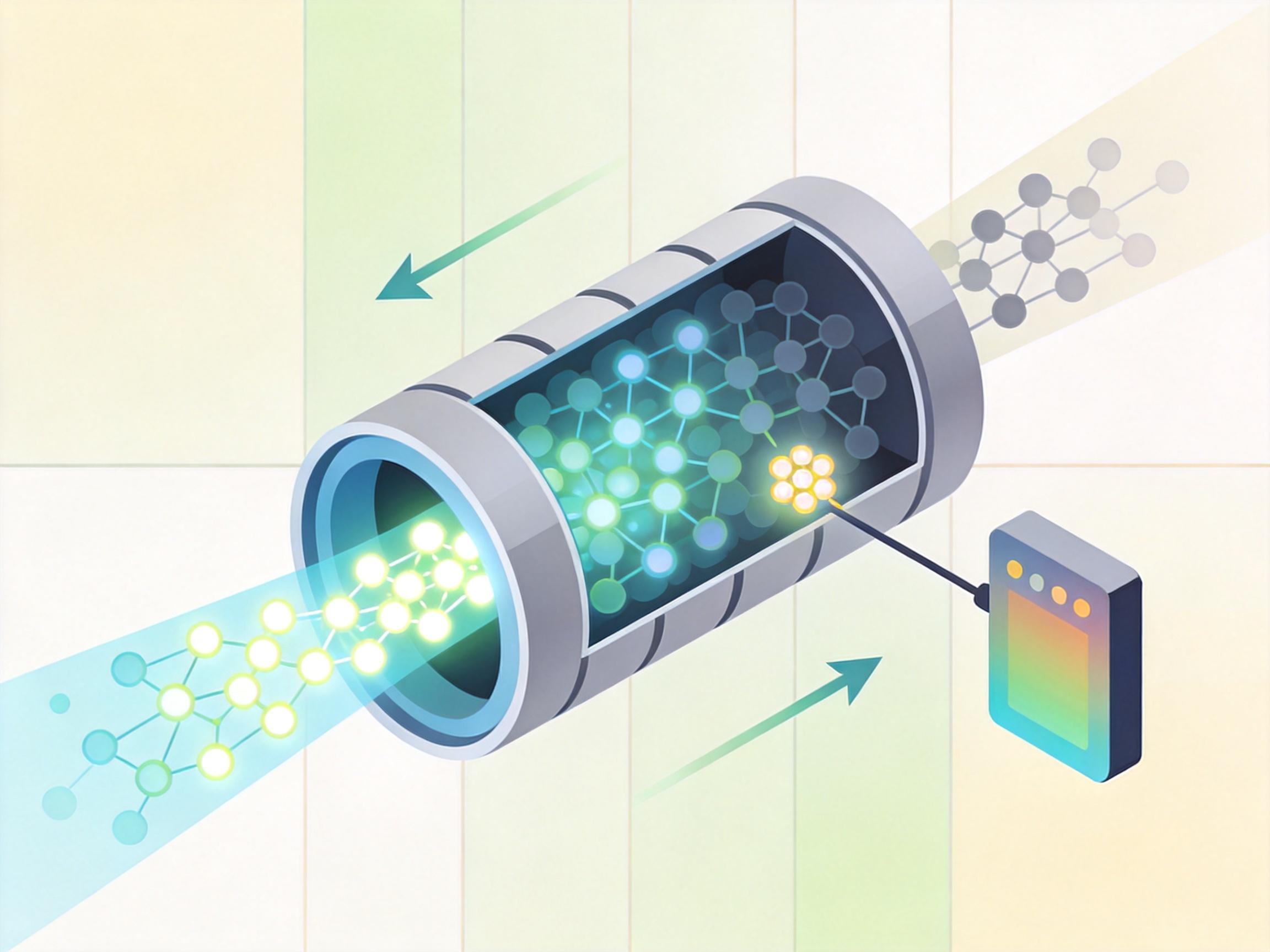
另一种更聪明的“EMA法”,干脆不存那么多数据,只存“平均分”和“分数波动”的动态平均值,每次用新批次的特征去更新这个平均值,就像裁判记着所有选手的平均水平,用这个动态标准来指导当前选手。这种方法几乎不占额外内存,效果还更好——在ImageNet 256×256的测试中,用EMA法训练的单步生成器,FID直接降到了0.72,甚至比真实验证集的FID(1.68)还低。
更惊人的是,他们用这个方法把原本要跑200步的多步生成模型改成了单步生成器:原本直接一步输出的图像模糊到认不出,经过FD-loss训练后,生成的图像和200步的原版几乎没有差别,推理速度直接提升了200倍。
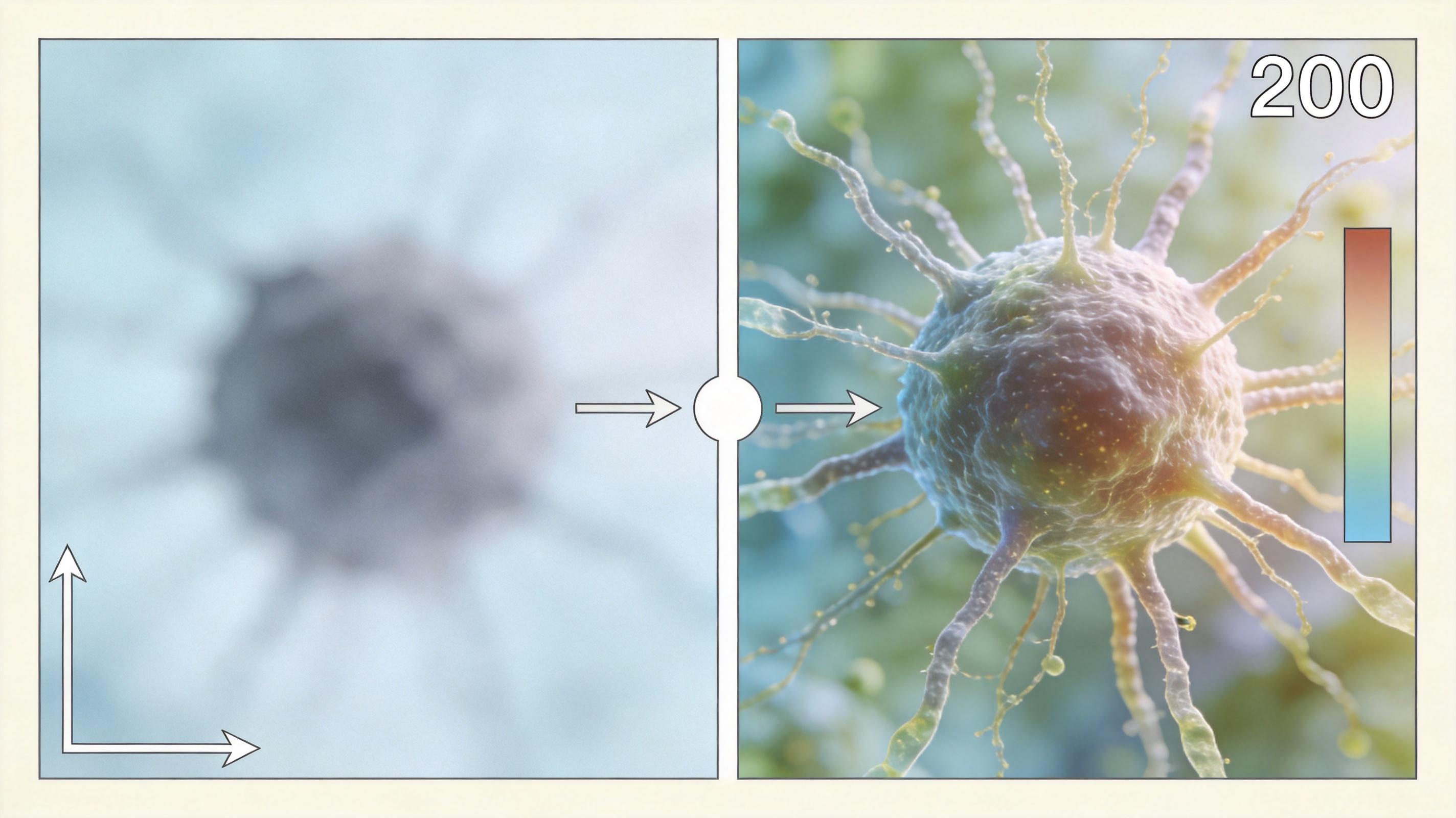
就在研究团队用FD-loss刷出新纪录的时候,他们意外发现了一个更扎心的事实:现在最好的生成模型,FID分数已经比真实验证集还低,但生成的图像和真实图像依然有肉眼可见的差距。这意味着统治了十年的FID指标,其实已经“失效”了——它只能区分“差图像”和“好图像”,却分不出“极好图像”和“真实图像”。
问题出在FID的“单一特征空间”上:它只认Inception-v3的打分,而这个模型是为ImageNet的1000类自然图像训练的,对现代生成模型能做出的复杂细节、风格变化,它根本“看不见”。于是团队又提出了一个叫FDr^k的新指标,同时用6种不同的特征模型打分,包括Inception-v3、DINOv2、CLIP等,然后取它们的归一化距离平均值。这个指标下,即使是FID达到0.72的模型,得分也只有1.89,而真实图像的得分是1.0——终于能准确衡量生成图像和真实图像的细微差距了。
当然,FD-loss也不是完美的:它需要多GPU的大显存支持,训练时的超参数调整也需要经验,而且只优化分布距离可能会牺牲一部分生成多样性——这些都是未来需要解决的问题。
当我们把FID从裁判席拉到训练场时,我们得到的不仅是一个更好用的训练工具,更是一次对“什么是好的生成模型”的重新思考。过去十年,我们为了刷FID分数,把生成模型训练成了“FID应试选手”,却忘了我们真正要的是“像人一样能创造出真实、多样图像的模型”。
指标的意义,从来不是为了被优化,而是为了接近真实。 这次突破不仅让生成模型的训练效率提升了一个量级,更让我们看到了一条新的道路:让评估指标直接指导训练,让训练目标更贴近人类的真实感知——这可能才是生成模型真正的未来。