对抗知识焦虑,从看懂这条开始
App 下载
给大模型装“透明脑”,从解释黑箱到设计玻璃箱
事后解释|玻璃箱模型|模型可解释性|北京大学|潘亮铭团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载事后解释|玻璃箱模型|模型可解释性|北京大学|潘亮铭团队|大语言模型|人工智能
当你问AI“为什么这个病要开这个药”,它给你的回答可能只是一串漂亮的“事后补写”——和它真正的思考过程毫无关系。过去五年,我们一直在用各种工具“撬”大模型的黑箱:看它关注了哪些词、哪些神经元在激活、甚至把它的计算过程拆成碎片分析。但这些努力始终绕不开一个尴尬:我们看到的,只是黑箱的影子,不是黑箱本身。直到北京大学潘亮铭团队的一篇综述被ACL接收,学界终于把目光从“解释黑箱”转向了更根本的问题:能不能直接造一个从里到外都看得懂的“玻璃箱”模型?
过去的可解释性研究,就像给一台已经造好的复杂机器装了个外部检测仪——能测出温度、转速,却没法告诉你内部齿轮到底怎么咬合。这种“事后解释”的方法有个致命缺陷:解释和模型真实计算之间存在“忠实性差距”,就像用影子来还原物体,永远是模糊的近似。
内生可解释性的思路完全相反:在设计模型的第一天,就把“可解释”写进基因里。它不是给黑箱贴标签,而是直接把黑箱改造成透明的玻璃箱——模型的每一步计算都有明确的语义,关键部件的改动会直接影响输出,解释不再是外挂,而是模型本身的一部分。
你可以把两种思路比作两种厨房:事后解释是在做好的菜里挑配料猜菜谱,内生可解释性则是从备菜开始就把每一步都写在食谱上,你改任何一种配料,最终的菜味都会跟着变。
潘亮铭团队把当前的内生可解释性方法总结成了五大范式,每一种都对应着把透明性嵌入模型的不同路径:
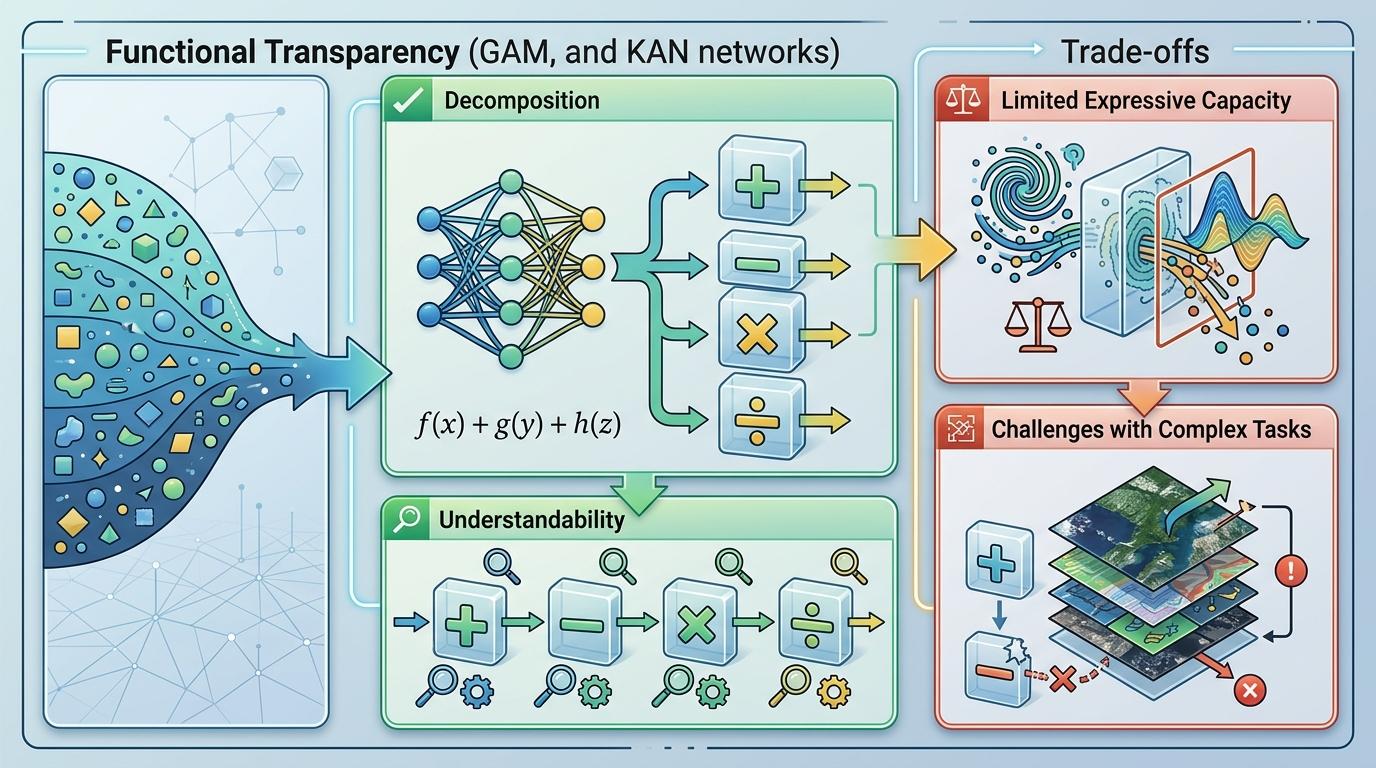
第一种是功能透明性,比如广义加性模型(GAM)和KAN网络,它们把模型的计算拆成一个个清晰的步骤,就像把复杂的数学题拆成加减乘除,每一步都能看懂。代价是这类模型的表达能力有限,很难处理太复杂的任务。
第二种是概念对齐,最典型的是概念瓶颈模型(CBM)——模型会先把输入转换成人类能理解的概念,比如判断一张X光片时先识别“阴影”“钙化点”,再用这些概念得出结论。但人类的概念体系本身就有局限,强行对齐可能会限制模型的创造力。
第三种是表征可分解性,比如Backpack语言模型,它把模型的内部表示拆成一个个独立的子空间,就像把不同的食材放在不同的碗里,互不干扰。这样我们就能清楚地看到哪个部分对应哪个语义,也能单独调整某个部分的输出。
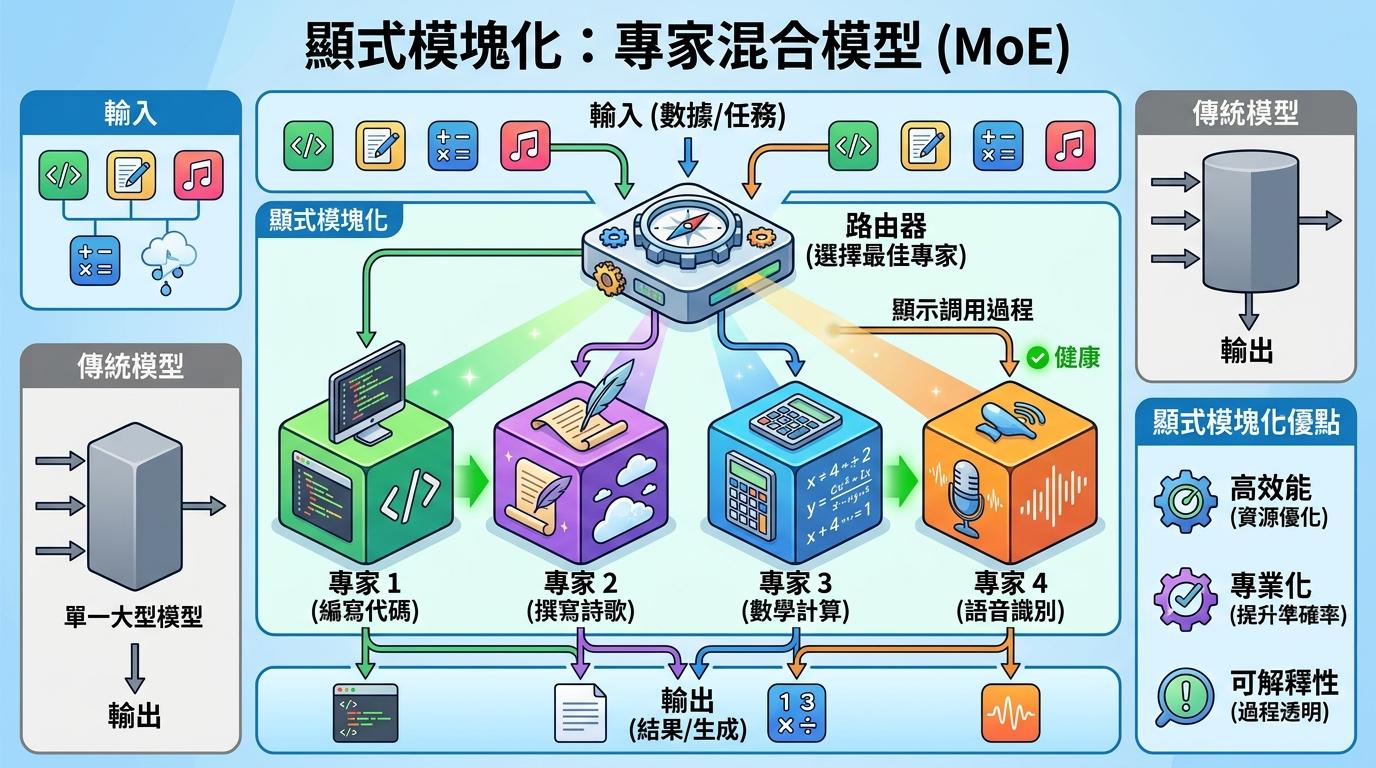
第四种是显式模块化,最火的是专家混合模型(MoE)。它把模型拆成一个个“专家”模块,每个专家只负责处理特定的任务,比如有的专家擅长写代码,有的擅长写诗。路由器会根据输入选择合适的专家,我们能清楚地看到模型调用了哪个专家来完成任务。
第五种是**潜在稀疏性诱导**,比如用GLU门控结构或者稀疏训练,让模型在计算时只激活必要的通路,就像厨房做菜时只拿出需要的工具和食材,不用把整个厨房都翻一遍。这样一来,模型的计算路径会变得更清晰,也更容易解释。
这些范式不是孤立的,很多模型会同时用到多种思路——比如MoE模型可以结合概念对齐,给每个专家贴上明确的语义标签,让它的分工更清晰。
内生可解释性的思路听起来很完美,但要落地还有不少难题。
首先是定义和评估标准的混乱。什么才算真正的“内生可解释”?是每个神经元都有明确语义,还是整个计算路径能被追踪?目前学界还没有统一的答案,评估方法也大多依赖主观判断,很难量化。
其次是性能和可解释性的平衡。虽然近年的研究已经证明两者不是绝对对立,但在超大规模模型上,要做到既透明又高性能仍然困难。比如功能透明性模型虽然易懂,但处理复杂语言任务时性能远不如GPT-4这样的黑箱模型。
最后是规模扩展的挑战。很多内生可解释性方法在小模型上表现不错,但扩展到百亿、千亿参数的大模型时,计算成本会急剧上升,解释的实时性和稳定性也会大打折扣。
更值得关注的是,我们对“可解释”的需求本身就千差万别:开发者需要知道模型的内部逻辑来调试,用户需要知道模型的决策依据来信任它,监管者需要知道模型是否合规。一个统一的透明模型,可能永远无法满足所有人的需求。
从“解释黑箱”到“设计玻璃箱”,这不仅是技术路线的转变,更是我们对AI的期待的转变——我们不再满足于AI能做事,更希望知道它为什么能做、怎么做的。
未来的AI,可能不会是一个完美的玻璃箱,而是一个“半透明”的系统:它在关键决策路径上保持透明,让我们能理解和干预;在非关键路径上则保留黑箱的灵活性,保证性能。
透明不是目的,可信才是。 当我们能真正理解AI的思考过程,才能真正信任它,让它成为我们可靠的伙伴,而不是一个神秘的黑箱。