对抗知识焦虑,从看懂这条开始
App 下载
AI自己评视频质量,分类精度直接拉满
安防监控|远程问诊|丹佛大学|自监督学习|视频质量评估|多模态视觉|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载安防监控|远程问诊|丹佛大学|自监督学习|视频质量评估|多模态视觉|临床诊疗技术|医学健康|人工智能
当医生对着模糊的远程问诊视频判断老人是否有认知障碍,当安防系统盯着满是运动模糊的监控找暴力行为——他们可能没意识到,眼前的AI正经历一场「学霸和学渣同卷考试」的荒诞:清晰视频上能拿100分的模型,碰到马赛克画质直接掉到58分。给每段视频标质量分?人工标注的成本能堆出一座数据中心。丹佛大学的研究员们偏不信这个邪,他们让AI自己学会给视频「打分」,还能用这个分数给自己的分类结果「纠偏」,在医疗和安防两个完全不搭的领域,准确率直接冲上了90%以上。这背后,是自监督学习这个「AI自学秘籍」的又一次神操作。
你可以把普通AI当成需要老师批改作业的学生——每道题都要有标准答案(人工标签),它才能学会对错。但自监督学习(Self-Supervised Learning,SSL)不一样,它是那种会自己找题做的学霸:给它一张打乱的拼图,它能自己拼回去;给它一张旋转过的图片,它能判断转了多少度;给它一段视频,它能预测下一秒画面是什么。
这种「自己创造监督信号」的思路,本质是让模型从数据本身的规律里学东西,而不是依赖人类标注。在视频领域,这简直是破局的钥匙:现实世界里的视频有几十亿小时,标注质量分的成本是天文数字,但每段视频里的帧与帧、片段与片段之间,天然就藏着「质量线索」——清晰帧的细节更多,模糊帧的特征更混乱,运动模糊的帧会有连续的轨迹变化。
自监督学习不是什么新东西,但把它用到视频质量评估上,丹佛大学的SSL-V3模型踩中了一个关键:质量评估不用追求「人类觉得好看」,只要能帮分类任务「做对题」就行。这就像学霸不用纠结作文的文采分,只要能帮自己总分提上去,怎么实用怎么来。
SSL-V3的核心逻辑说穿了很简单:让AI同时干两件事——给视频评质量分,用这个分数调整分类的信心。但它的巧劲藏在细节里。
首先是双分支的对比学习结构:模型同时看原始视频和一段被打乱顺序的视频片段,通过对比两者的特征,让自己学会区分「清晰的有用信息」和「混乱的噪声」。这就像让学霸同时看正确的笔记和抄错的笔记,自然能更清楚什么是对的。

然后是分层的质量评估头:先给视频的每个时空小片段打分(序列评分器),再结合时间效应把这些分数合成整体质量分(视频评分器)——它会考虑「连续模糊的帧比单帧模糊更影响判断」「前面的清晰帧会让后面的模糊帧显得更差」这些人类视觉的规律,但完全是从数据里学来的,不用人类教。
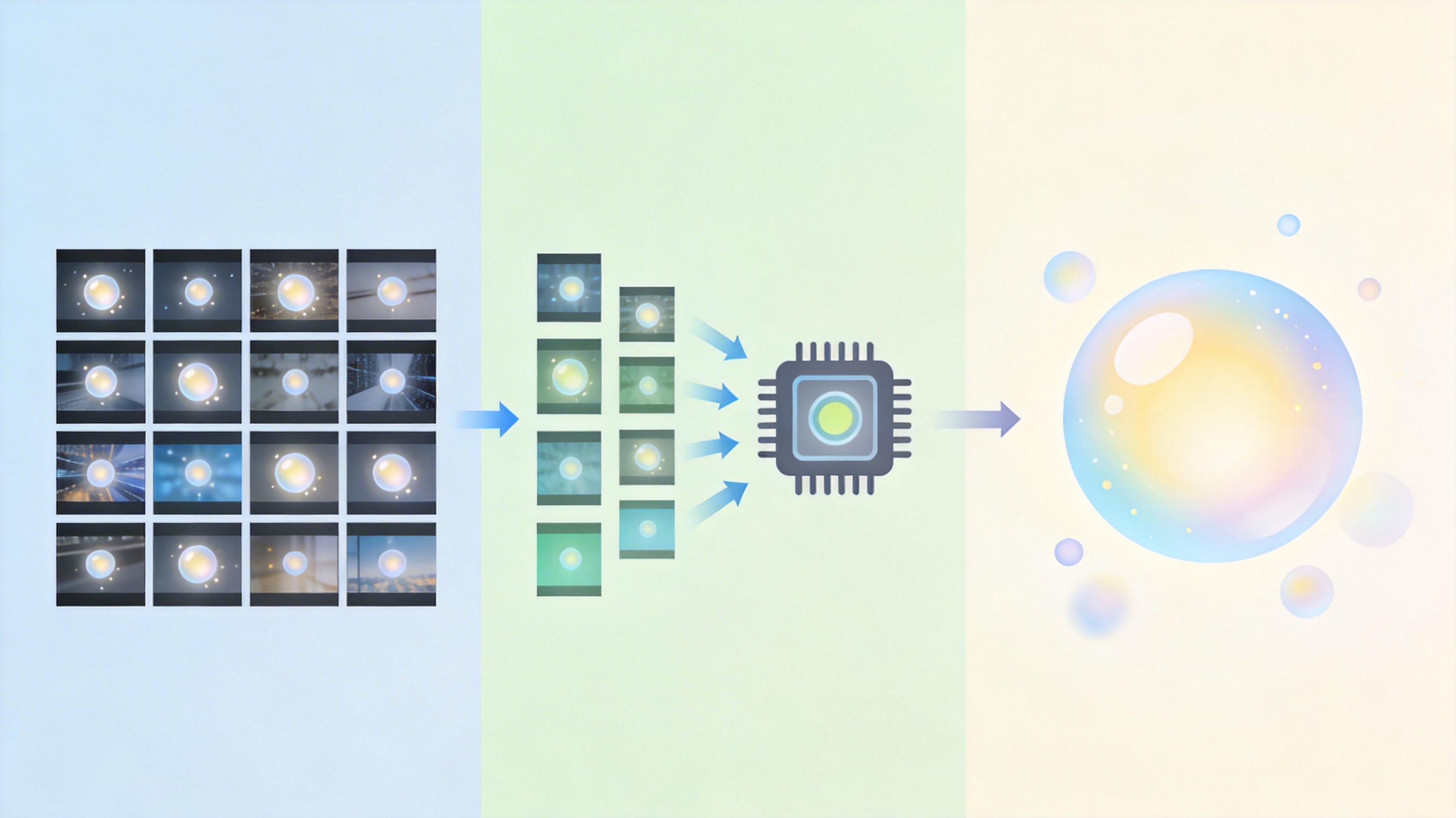
最妙的是Tune-CLS模块:它用预测出的质量分,直接去「放大」或「缩小」分类结果的信心——质量分高,就给模型的判断加权重;质量分低,就压低它的信心,相当于让AI自己知道「这题我可能做错了,别太当真」。而这个质量分的学习,完全是靠分类任务的结果反向指导的:如果某个质量分让分类结果更准,模型就会记住这个判断逻辑;如果错了,就自动调整。整个过程没有任何人工标注的质量分,全是AI自己在「试错-修正」。
在医疗的认知障碍检测数据集上,它把准确率从不到60%拉到了94.87%;在安防的暴力行为检测数据集上,面对高速运动的模糊画面,准确率超过了91%。
很多人会把SSL-V3的质量分和人类的主观评分混为一谈,但这恰恰是它最聪明的地方——它的质量分不是「人类觉得好看的分数」,而是「对分类任务有用的分数」。
传统的无参考视频质量评估(No-Reference VQA),总想着去逼近人类的主观感受,为此要收集大量人工标注的平均意见分(MOS),成本高到离谱。但SSL-V3完全跳出了这个框架:它根本不在乎人类觉得视频好不好看,只在乎这个分数能不能帮自己把分类做对。这就像考试时,学霸不用纠结卷面整洁,只要能做对题就行。
当然,它也有局限:双分支的结构让计算量翻了倍,实时应用还得轻量化;它的质量分是个抽象的数字,没法直接说清楚是「模糊」还是「曝光不足」;目前也只针对分类任务,能不能用到检测、分割上还得再探索。但这些都是技术优化的问题,核心思路的突破已经足够重要——它证明了,在AI的世界里,「有用」比「完美」更重要。
当我们还在为AI的「智商」惊叹时,SSL-V3给我们提了个醒:AI的「自学能力」可能比「智商」更重要。现实世界里的数据永远是混乱的、不完美的、没有标签的,能在这种环境里自己找规律、自己调整的AI,才是真正能落地的AI。
数据不用完美,有用就行。 这句话不仅是SSL-V3的核心,也是AI从实验室走进现实的关键。未来的AI不会是那种需要人类喂标准答案的乖学生,而是会自己在混乱里找秩序、在噪声里找信号的探索者——就像我们人类自己,在不完美的世界里,一步步学会怎么把事情做对。