对抗知识焦虑,从看懂这条开始
App 下载
AI训练巨变:过程首次比结果更重要?
美团研究团队|香港中文大学|过程奖励机制|Reagent方法|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载美团研究团队|香港中文大学|过程奖励机制|Reagent方法|AI智能体|人工智能
在传统的AI训练赛场上,长期存在一种不公:一个AI智能体(Agent)可能在解决复杂问题的过程中,逻辑混乱、工具乱用,最终却误打误撞“蒙”对了答案,从而获得满分奖励。而另一个Agent思路清晰、步骤严谨,只因最后一步计算或工具调用失误,便与前者一同被判为零分。这种“唯结果论”的奖惩机制,尤其在需要多轮对话、搜索、编码等长链条任务中,成了一个巨大的瓶颈。它无法分辨哪种失败更有价值,也无法教会AI如何“聪明地思考”,只能鼓励它成为一个更幸运的“猜测者”。
然而,一场深刻的变革正在发生。来自香港中文大学与美团的研究团队联合发布了一项名为 Reagent 的新框架,其核心目标直指这一痛点:让AI Agent的训练,从“只看结果”转向“全过程反馈”。这不仅是一次技术迭代,更是一场关于AI如何学习与进化的哲学转变,推动AI从一个只会“背答案”的学生,向一个真正懂得“解题思路”的思考者进化。
变革的核心,在于创造了一位不知疲倦、明察秋毫的AI“阅卷老师”——Agent Reasoning Reward Model(Agent-RRM)。为了训练这位老师,研究团队首先构建了一套特殊的“错题本”,收集了大量真实的Agent解题轨迹,其中包含了各种情况:有推理顺畅但执行失误的“可惜案例”,也有一路乱猜却侥幸成功的“幸运案例”。

每一条轨迹都被人工标注了详细的“阅卷意见”,不仅指出其思路的闪光点与逻辑的断裂处,还给出了一个0到1之间的精细“过程分”。基于这份高质量教材,Agent-RRM被训练成一个能够深度“批改作业”的评审模型。它会从头到尾审视Agent的整个思考和行动过程,然后输出三样东西:
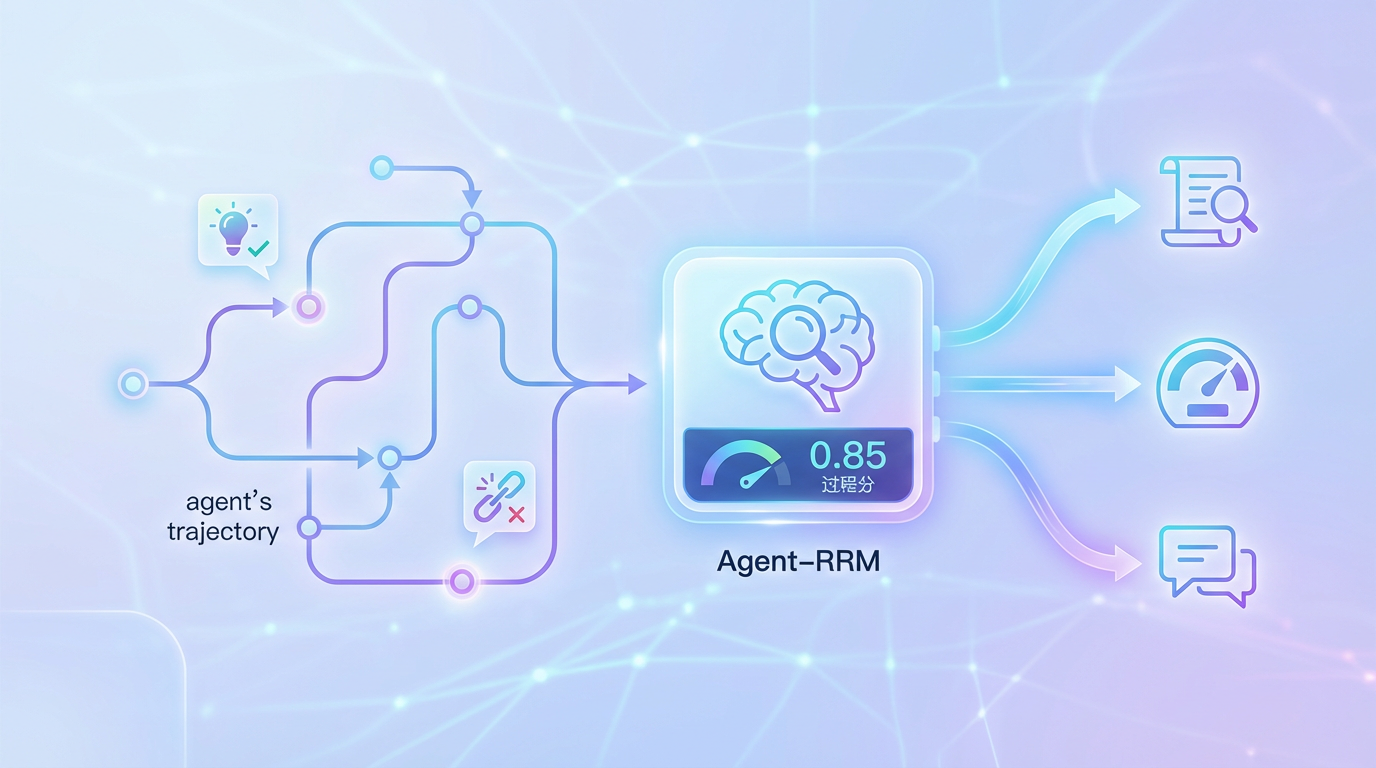
就像一位优秀的数学老师,Agent-RRM不仅看最终答案,更看重演算过程。一条逻辑严谨但最终答案出错的轨迹,可能会得到0.8的过程分;而一条胡乱猜测蒙对的轨迹,可能只有0.3分。这一机制的根本目标是:教会Agent“怎么想”和“怎么用工具”,而非“怎么猜对答案”。
有了会打“过程分”的老师,如何将这些反馈有效地“喂”给学生Agent?这便是Reagent框架要解决的核心问题。它巧妙地将文字点评和分数奖励统一起来,并设计了三种不同强度的“辅导模式”:
模式一:课后点评(Reagent-C) 这是一种最轻量级的介入。Agent模型本身不做任何改动。它先独立完成一次任务,然后Agent-RRM给出一段文字评语。Agent在阅读评语后,再尝试做一遍。这相当于为任何现成的AI配备了一位“审稿人”,在提交最终答案前获得一次宝贵的修正机会。
模式二:过程分计入总成绩(Reagent-R) 这一步将Agent-RRM打出的“过程分”直接纳入奖励函数。过去,Agent的训练得分只有“答对(1分)”和“答错(0分)”两种。现在,总分变成了“结果分 + 过程分”。这意味着,即便任务最终失败,但只要思考路径清晰、工具使用合理,Agent依然能获得正向激励。这极大地缓解了复杂任务中奖励过于稀疏(大部分尝试都是0分)的难题,鼓励Agent探索更有价值的“虽败犹荣”的路径。

理论的优雅最终需要实践来证明。实验结果显示,Reagent框架带来了显著的性能提升。
简单“听劝”就有用:仅仅是Reagent-C模式,在多个数学和搜索任务上,“听完批评再答一次”就能稳定提升正确率。
过程奖励引导方向:加入过程分(Reagent-R)后,Agent明显更倾向于选择逻辑正确的路径,而不是在错误的道路上“一条道走到黑”。
统一学习实现超越:当最强的Reagent-U模式被应用时,一个80亿参数的中等规模模型,在通用Agent基准测试GAIA上的表现,追平甚至部分超过了许多更大参数量的模型。在WebWalkerQA等其他复杂任务上,它的表现也远比只看结果的传统模型更稳定,更不容易被“瞎蒙”或“瞎忙”带偏。
港中文与美团的这项工作,成功地将人类教育中至关重要的“过程性评估”理念,系统性地引入了AI Agent的训练流程。它揭示了一个深刻的道理:对于追求通用智能的AI而言,一个好的思考过程,远比一个偶然正确的答案更有价值。
这一转变的意义超越了简单的性能指标提升。它意味着未来的AI将更加可解释、可信赖。当AI不仅能给出答案,还能清晰地展示其得出答案的逻辑链条时,我们就更容易诊断它的错误,信任它的决策。这种关注过程的训练范式,正在为我们塑造一个全新的AI未来——一个AI不再是冰冷的“答案机器”,而是能够与我们协同思考、共同解决复杂问题的“思考伙伴”。