对抗知识焦虑,从看懂这条开始
App 下载
AI卡壳在内存上,谷歌的破局全栈图
Transformer模型|数据中心|全栈优化|内存瓶颈|谷歌|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载Transformer模型|数据中心|全栈优化|内存瓶颈|谷歌|大语言模型|人工智能
2026年的AI圈像一场被掐住水管的狂欢:大模型参数越堆越大,推理速度却卡在原地;科技巨头砸千亿建数据中心,服务器却因缺内存趴在机房里。谷歌CEO皮查伊的一句话点破了真相:这不是算法的瓶颈,是物理世界的极限——当AI模型的胃口追上了硬件产能的天花板,整个行业突然发现,自己正站在一个看不见的边界前。而谷歌给出的答案,不是等工厂扩产,而是从芯片到代码,从产品到组织,重新定义AI的全链路。
你可以把大模型的运行想象成一场超级派对:CPU是派对策划,GPU是现场乐队,而内存就是能容纳所有人的宴会厅。当Transformer模型把上下文窗口从8K扩展到1M,相当于把派对人数从几十人翻到上万人,宴会厅的面积却没跟上——每增加一段长文本,内存的开销就会呈平方级暴涨,KV缓存里存的键值对像越堆越高的餐盘,最终把通道堵得水泄不通。
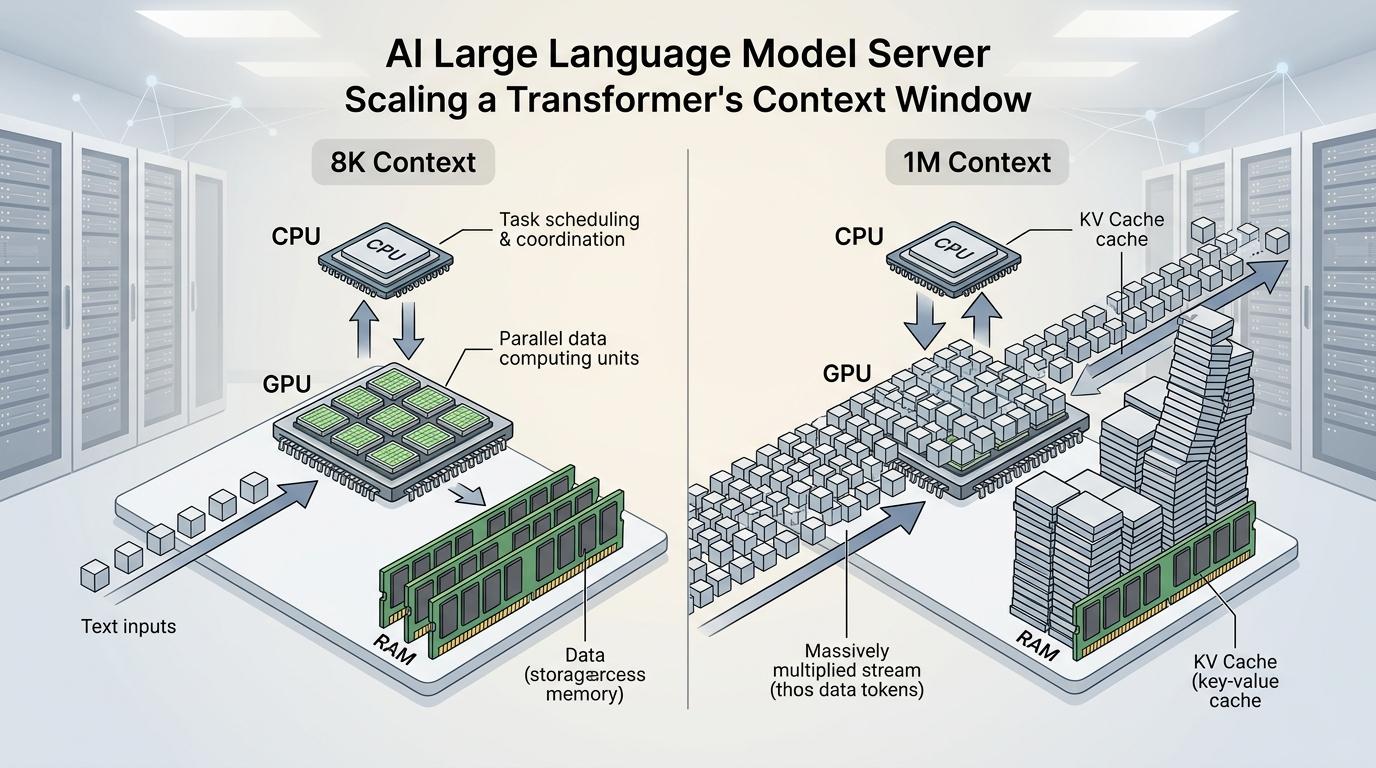
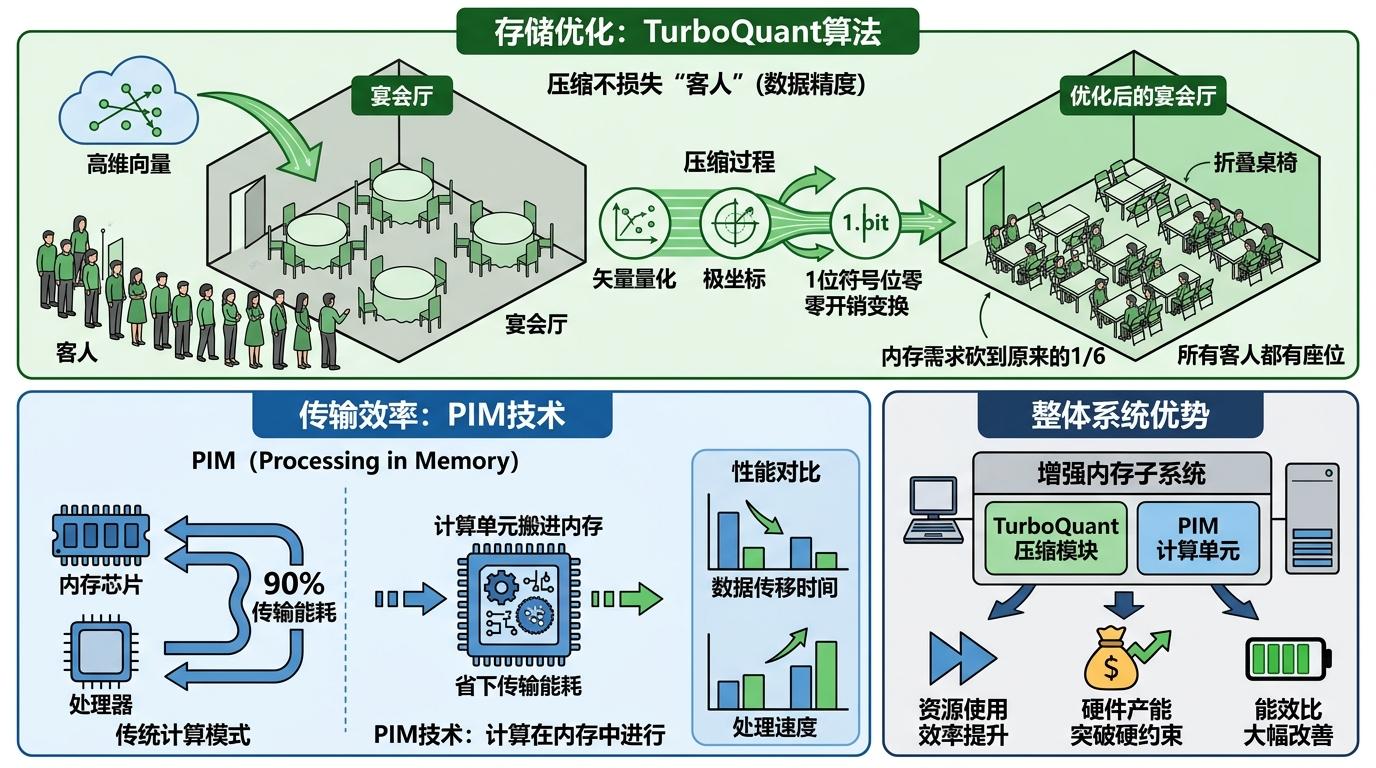
谷歌的TurboQuant算法相当于给宴会厅装了折叠桌椅:通过矢量量化把高维向量压缩成极坐标,再用1位符号位的零开销变换,硬生生把内存需求砍到原来的1/6,却没让任何一个客人离场。这种“压缩不缩水”的思路,本质是在硬件产能的硬约束下,用算法重新定义资源的使用效率。而更底层的突破来自PIM技术——把计算单元直接搬进内存芯片里,就像在宴会厅里直接搭舞台,让数据不用在“舞台”和“观众席”之间来回奔波,把90%浪费在传输上的能量省了下来。
当内存的瓶颈被算法撕开一道口子,谷歌的全栈优势开始显现。第七代TPU芯片Ironwood把内存带宽拉到7.37TB/s,相当于每秒能传输1800部高清电影,专门为推理任务设计的架构,让大模型的响应速度从“分钟级”压到“秒级”。但硬件只是基础,真正的革命发生在产品端:传统搜索被改造成了Agent管理器,用户输入的不再是关键词,而是“帮我完成下周的出差计划”——AI会自动拆分任务,调用订票工具、查询天气、生成行程单,甚至能记住你对酒店的偏好。
这种“有状态AI”的核心,是给模型装上了“长期记忆”。就像你不用每次跟朋友见面都重新自我介绍,AI Agent能跨会话记住你的需求,通过向量数据库快速检索之前的对话,把零散的信息拼成完整的任务链。而谷歌内部的Antigravity平台,把这种能力开放给了所有开发者——用不到100行代码就能搭建一个能处理复杂任务的Agent,相当于给每个企业都配了一个AI项目经理。
当行业都在盯着内存产能的短期缺口时,谷歌已经把目光投向了更远的地方。量子计算芯片Willow能在200秒内完成超级计算机1.3万年才能算完的物理仿真,这意味着未来的AI模型可以直接模拟分子结构,不用再靠试错研发新药;Waymo自动驾驶每周完成15万次付费出行,背后是端到端深度学习对复杂路况的精准判断;甚至连“太空数据中心”这种听起来科幻的项目,也被列在了长期研发清单上——当地球的能源和土地不够用的时候,把数据中心搬到轨道上,用太阳能供电,或许是下一个百年的解决方案。
这些押注的逻辑很简单:当AI的边界被硬件和能源限制时,真正的突破往往来自“非对称创新”——不是在同一个赛道上比谁的芯片更快,而是换一个赛道,重新定义“计算”本身。就像当年谷歌用TPU打破GPU的垄断,现在它用量子计算、自动驾驶、机器人,在AI的边界外,提前圈好了下一个赛场。
当我们谈论AI的瓶颈时,我们其实在谈论人类对效率的极限追求——从算盘到计算机,从晶体管到量子芯片,每一次技术革命,都是在突破物理世界给我们设定的边界。谷歌的全栈创新路径告诉我们,真正的破局者不会等风来,而是自己造风:用算法挤干硬件的最后一点潜力,用产品重新定义用户的需求,用长期主义的押注,在别人看到瓶颈的地方,看到下一个十年的机会。
约束不是终点,而是创新的起点。