对抗知识焦虑,从看懂这条开始
App 下载
无干净图像也能去噪,AI学会自我修正了
噪声自适应|图像修复|统计一致性|无参考去噪|布里斯托大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载噪声自适应|图像修复|统计一致性|无参考去噪|布里斯托大学|多模态视觉|人工智能
你有没有过这种经历:翻出一张多年前的老照片,想修复却发现满是噪点;或者用显微镜拍样本,明明调好了参数,图像还是糊着一层颗粒?过去要解决这些问题,要么得有一张干净的“标准答案”图像当参考,要么得精准判断噪声类型——可现实里,我们往往只有那一张带噪的图。2026年,布里斯托大学的研究团队拿出了一个反常识的方案:不用干净图像,不用预设噪声模型,让去噪器自己“检查作业”。这背后的秘密,藏在一个人工加的小信号和一套统计规则里。
过去的去噪器像个埋头干活的工人,做完就交差,从不管结果对不对——比如把本该保留的纹理磨平,或者留下肉眼难辨的伪影。这些“隐形错误”的根源,是去噪结果和真实噪声的统计特性不匹配:真实噪声的分布是有规律的,比如高斯噪声的像素值会围绕均值随机波动,而错误的去噪结果,残差会出现明显的系统性偏差。
这个研究的核心洞察,就是把这种“统计一致性”变成一个可量化的标准。你可以把它想象成给去噪器配了个质检员:不用拿标准答案对比,只需要看产品(去噪结果)的残差,是否符合真实噪声的“出厂标准”。比如真实噪声是随机分布的,那残差就不能有明显的条纹或斑块;真实噪声的均值为0,那残差的整体平均值就不能偏离0太多。
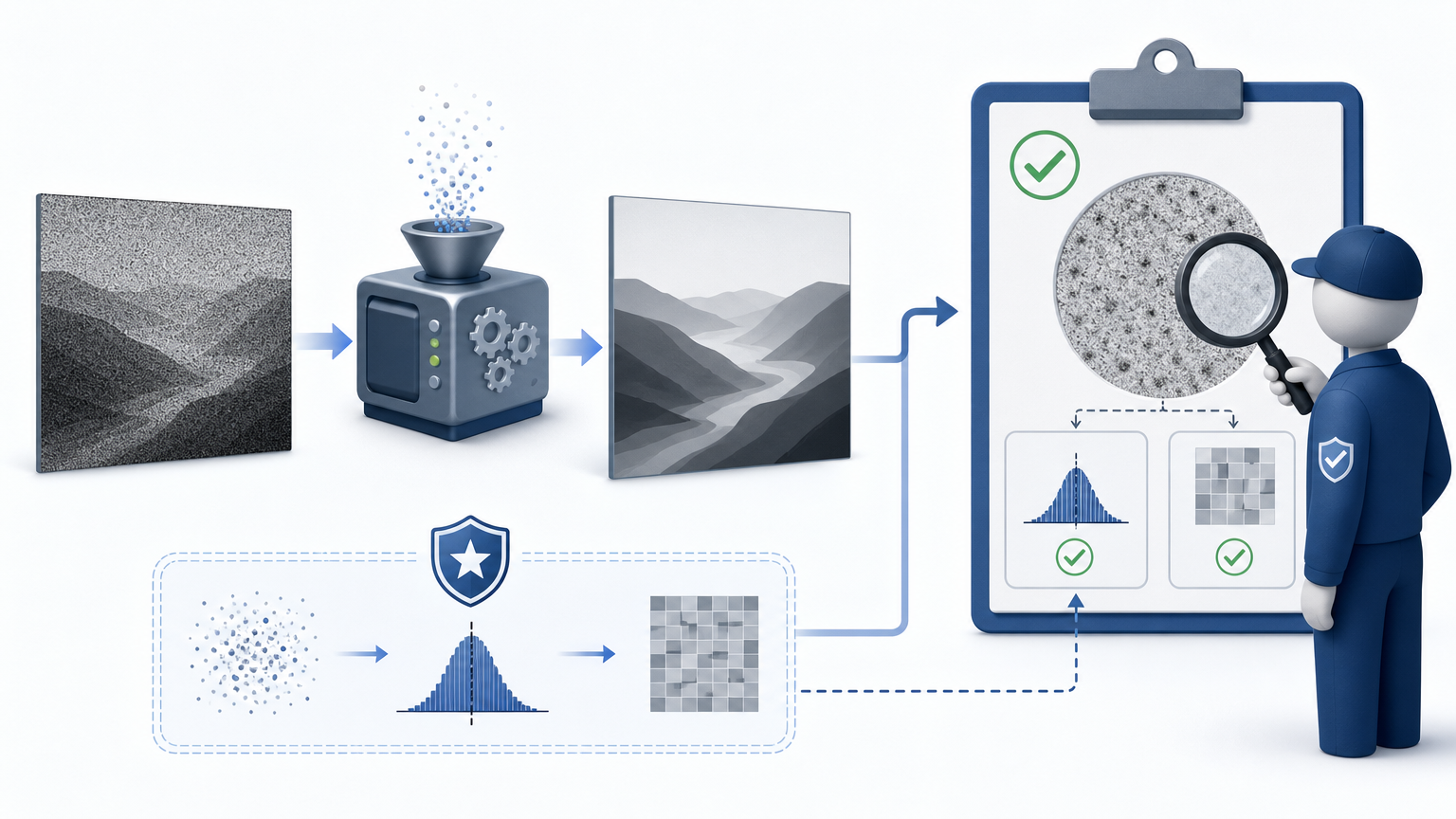
但问题来了,我们没有干净图像,怎么知道真实噪声的统计特性?研究者的解法是引入一个“辅助信号z”——就像给带噪图像撒上一层已知分布的细沙,然后通过观察这层细沙的“痕迹”,反推去噪结果的合理性。
辅助信号z是整个方法的关键,它是我们主动加到带噪图像上的微小随机扰动——比如均值为0、方差远小于真实噪声的高斯信号。为什么要加这个东西?
假设真实干净图像是x,带噪图像是y=x+n(n是真实噪声),我们给y加上z得到新图像ŷ=y+z。如果去噪器输出的结果x̂是准确的,那么ŷ - x̂ = (x+n+z) - x = n+z,这个残差的统计特性应该等于真实噪声n加上辅助信号z的特性。而z是我们自己生成的,它的分布完全已知——这就相当于给我们提供了一个“已知的标尺”,可以用来测量去噪结果的残差是否合理。
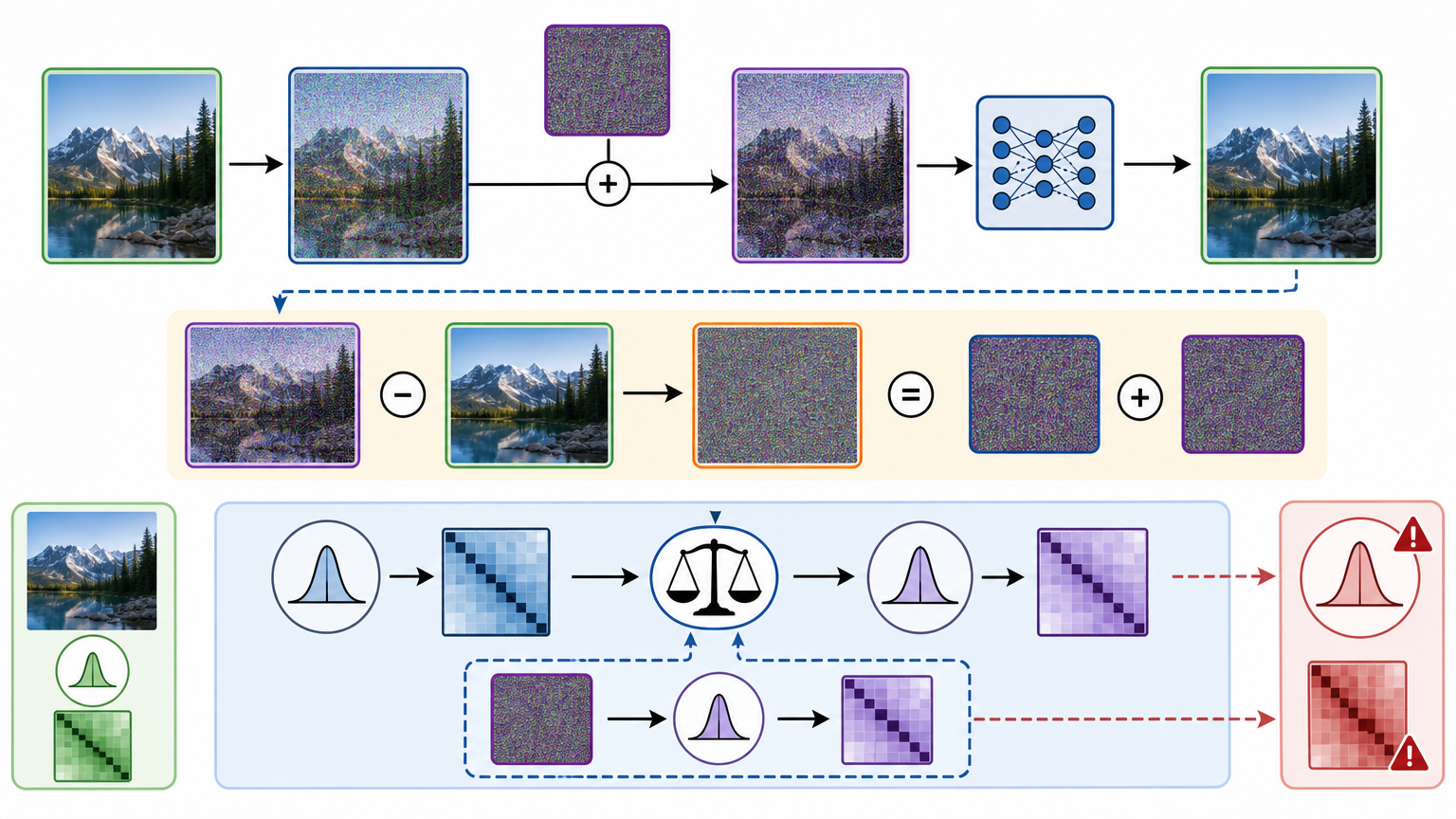
研究者设计了两个神经网络来实现这个逻辑:一个是后验采样网络,用来模拟真实图像在带噪数据下的可能分布;另一个是一致性函数网络,专门计算残差和辅助信号的统计偏差。训练时,让这两个网络配合,一边保证精炼后的结果不偏离原始去噪器太多,一边强制残差符合统计一致性。整个过程完全不需要干净图像,只需要带噪数据和我们自己加的辅助信号。
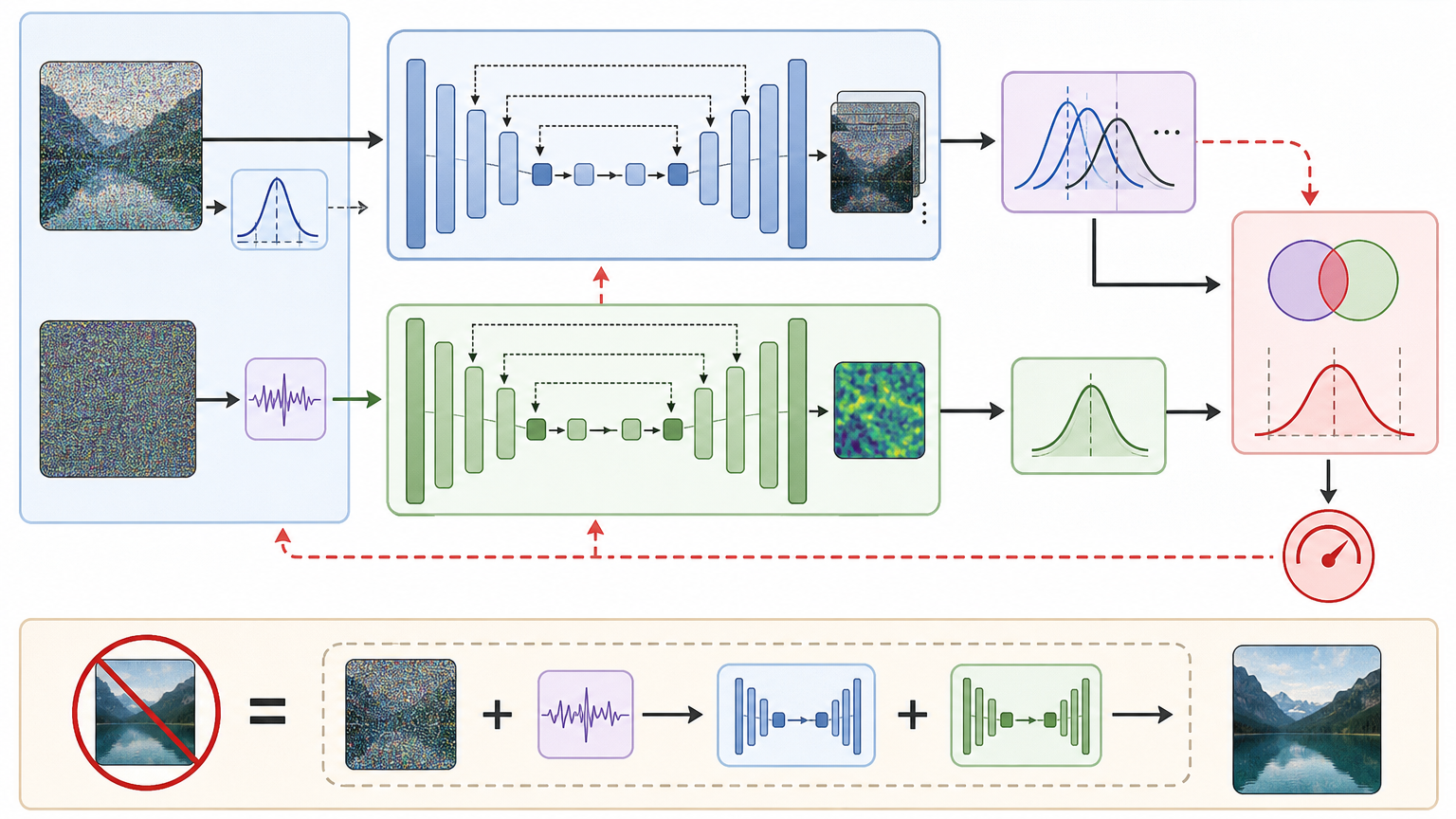
在BSD68、Set12等标准数据集上,这个方法展现出了惊人的通用性:给传统的NLM去噪器做精炼,在椒盐噪声下PSNR能提升3~4dB,几乎完全消除残留的白点;给已经很强的DnCNN做精炼,也能稳定提升0.1dB左右。更重要的是,它兼容几乎所有基础去噪器——不管是传统的滤波方法,还是深度学习模型,都能像插插件一样直接用上。
但它也不是万能的。比如它假设噪声是逐像素独立的,对于条纹噪声这种空间相关的噪声,就得先做预处理把噪声“掰成”独立的;训练时需要大量多样的带噪数据,否则精炼网络学不到通用的统计规律;辅助信号的强度和分布也得根据噪声类型调参,没有一劳永逸的设置。另外,推理时多了一次网络前向,对于实时性要求极高的场景,比如手机拍照预览,可能还需要进一步优化。
从依赖干净图像的监督学习,到只用带噪数据的自监督方法,再到现在能自我修正的统计一致性精炼,图像去噪的发展,本质上是在一步步摆脱“标准答案”的束缚。这个研究最有意思的地方,不是它提升了多少PSNR,而是它提供了一种全新的思路:与其追求一个完美的去噪模型,不如教会模型自己判断“什么是对的”。
当AI不再需要人类给的标准答案,而是能从数据本身的规律里学会自我校准,这可能才是真正的智能开端——毕竟人类的学习,从来不是靠死记硬背标准答案,而是靠在实践中不断修正自己的认知。不用标准答案,AI也能学会改错。