对抗知识焦虑,从看懂这条开始
App 下载
AI算力成本战:SRAM芯片正在挑战英伟达
算力成本|芯片初创企业|AI服务器|英伟达|SRAM芯片|先进材料|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载算力成本|芯片初创企业|AI服务器|英伟达|SRAM芯片|先进材料|AI算力|前沿科技|人工智能
2026年春天,一家估值超800亿美元的AI公司陷入了前所未有的算力焦虑——它的服务器负载因用户需求激增而濒临崩溃,每年数百亿美元的芯片开支像一块巨石压在利润率上。这家公司没有继续抱紧行业巨头的GPU,反而转头找上了一家成立仅三年、还没量产过芯片的英国初创企业。
这不是一时冲动的冒险。当AI行业终于从「训练大模型的狂欢」转向「跑通推理的盈利」,一场围绕算力成本的暗战已经打响。而这场战争的胜负,可能由一种你从未听过的内存芯片决定——SRAM,静态随机存取存储器。为什么一块小小的内存,能让AI巨头们集体转向?
你可以把AI模型的运行拆成两个阶段:训练是「教AI做题」,需要海量算力同时运算;推理是「让AI答题」,要根据用户输入逐字生成答案,这过程像你翻书查资料——每写一个字,就得跑回书架找对应的内容。
传统GPU的问题就出在这里。它用的DRAM(动态随机存取存储器)像放在书房另一头的大书架,容量大但离书桌远,每次取资料都要跑老远,不仅慢,还费力气(也就是功耗)。尤其是推理的「答题」阶段,AI要逐字调取模型权重,DRAM的带宽瓶颈会让GPU的算力直接浪费掉70%以上——就像你明明能一秒写10个字,却要花9秒在跑路上。
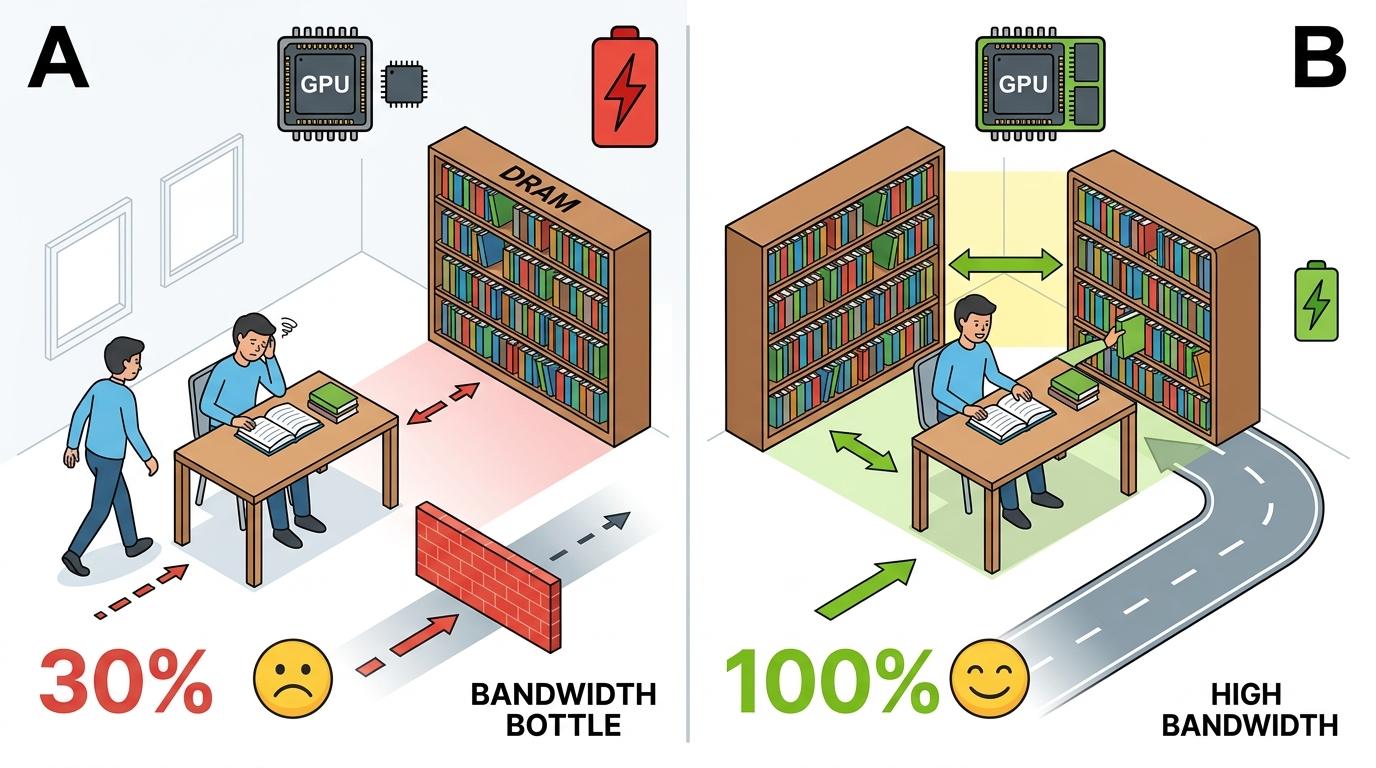
这就是为什么2025年,多家头部AI公司的推理成本远超预期,毛利率被硬生生啃掉了一大块。OpenAI和Anthropic的财报里,「服务器与芯片开支」成了最刺眼的项目:一台H100 GPU每小时租金2美元,生成100万个token就要烧掉3美元,而用户输入100万个token的成本才0.003美元——输出成本是输入的1000倍。
SRAM的出现,相当于把整个书架直接钉在了书桌桌面上。
它的核心结构是6个晶体管组成一个存储单元,不用像DRAM那样靠电容存电、反复刷新,读取速度能达到1纳秒——是DRAM的10到15倍。更关键的是,SRAM可以和计算单元做在同一块芯片上,数据不用再跨芯片传输,带宽能跟着计算单元的数量线性增长。比如NVIDIA最新的Blackwell GPU里,单个计算核心的SRAM缓存带宽能到37.5TB/s,是HBM3e内存带宽的4倍多。
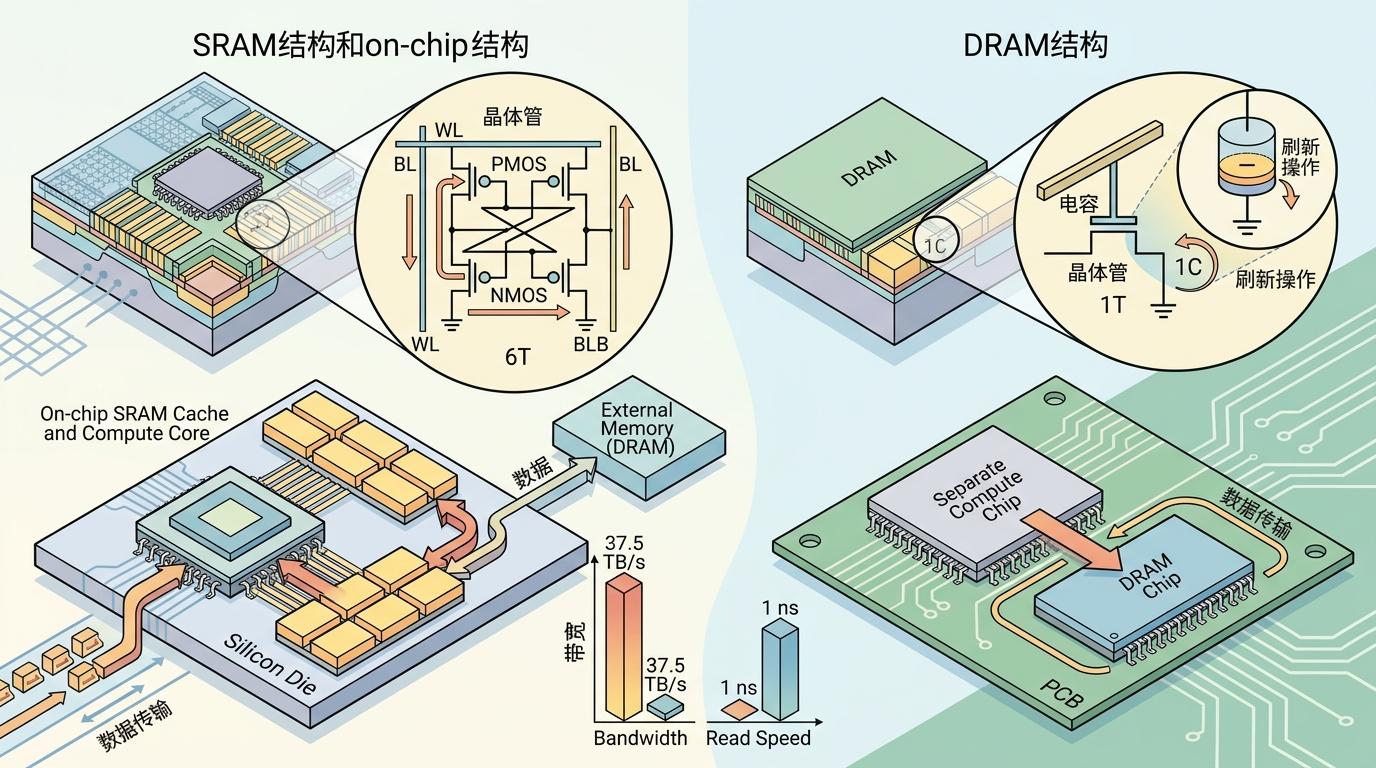
但真实的机制比这个类比更精确:
这就是为什么那些初创公司会赌上全部身家做SRAM架构芯片。英国的Fractile宣称,他们的芯片能让推理速度达到GPU的100倍,成本降90%;Groq的LPU芯片靠230MB的SRAM,实现了80TB/s的带宽,比HBM3e快10倍。这些数字不是画饼——当Anthropic的用户因为算力不足被限制高峰使用时,SRAM芯片的低延迟特性,恰恰能解决最让用户抓狂的「卡顿」问题。
Anthropic找上Fractile,本质上是在打一场供应链的「去垄断战」。
过去几年,英伟达靠着GPU和CUDA生态占据了AI芯片市场90%以上的份额,黄仁勋甚至敢说「没有我们的芯片,AI公司活不下去」。但当AI公司的年芯片开支达到数百亿美元,没人愿意把命运攥在一家供应商手里。Anthropic早就开始布局:和谷歌签大额芯片订单,能在谷歌云之外使用;和亚马逊签1000亿美元的长期协议,锁定Trainium芯片的算力;现在又找上Fractile——不是要完全替代英伟达,而是要在谈判桌上拿到更多筹码。
这背后还有更现实的供应链安全考量。台积电的先进制程产能已经排到了2027年,三星的罢工、内存芯片的涨价,随时可能让AI公司的算力计划泡汤。而SRAM芯片的另一个优势,是它对先进制程的依赖没那么高——Groq的LPU用的还是14nm工艺,照样能实现超高带宽。这意味着它的供应链更分散,不会被「卡脖子」。
当然,SRAM不是万能药。它的容量瓶颈决定了它只能做推理,做不了训练;而且它需要软件层显式管理数据布局,不像GPU那样能自动缓存——这对AI公司的技术团队又是新的挑战。但在「活下去并盈利」的压力下,这些挑战都成了值得啃的硬骨头。
当我们谈论AI的未来时,总爱说「模型越大越好」,但真正决定AI能不能走进普通人生活的,是「推理的成本能不能降下来」。SRAM芯片的出现,不是要颠覆GPU,而是要补上AI商业化的最后一块拼图——让AI公司不用再为每一个token的输出烧钱,让用户不用再为高峰时段的卡顿买单。
算力的本质,从来不是比谁的芯片更强大,而是比谁能把每一分算力都用在刀刃上。当书架终于搬到了书桌旁,AI的盈利故事,才真正开始。