对抗知识焦虑,从看懂这条开始
App 下载
AI能同时看懂文字视频,还懂物理规律
统一架构|视频内容生成|物理规律建模|生成式AI模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载统一架构|视频内容生成|物理规律建模|生成式AI模型|多模态视觉|人工智能
你对着手机拍的一段手摸镜子的视频,说一句“让镜子像液体一样泛起涟漪,手臂变成反光材质”——下一秒,视频里的镜子真的开始波动,手臂的皮肤也泛起金属光泽,而你的动作全程丝毫不乱。这不是科幻电影的特效,而是2026年多模态生成模型的常规操作。它能把文字、图片、视频甚至随手画的圆圈,都揉成全新的内容画布,还能严格遵守重力、动能这些物理规则。这背后的技术,到底是怎么让机器像人一样“看懂”又“创造”的?
过去的AI像一群各说各话的专家:文本模型只会读字,图像模型只会看图,视频模型只能处理连续帧。它们之间隔着看不见的墙,要让文字生成视频,得靠好几个模型“接力”,效率低还容易出错。
现在的多模态生成模型,把这些专家都拉进了同一个“会议室”——统一的语义空间。你可以把这个空间想象成一个通用翻译器:不管是文字拆成的token、图像提取的像素特征,还是视频拆解的时空帧,进来后都会转换成同一种“通用语言”。
具体来说,它靠两套核心模块协同工作:一套是多模态大语言模型,负责理解你的指令、梳理逻辑,比如“蛋白质折叠的黏土动画解说”里,它得先搞懂什么是α螺旋、β折叠;另一套是视觉生成模型,比如扩散模型,负责把这些逻辑转换成具体的画面——用黏土质感的动画,把抽象的分子结构演出来。
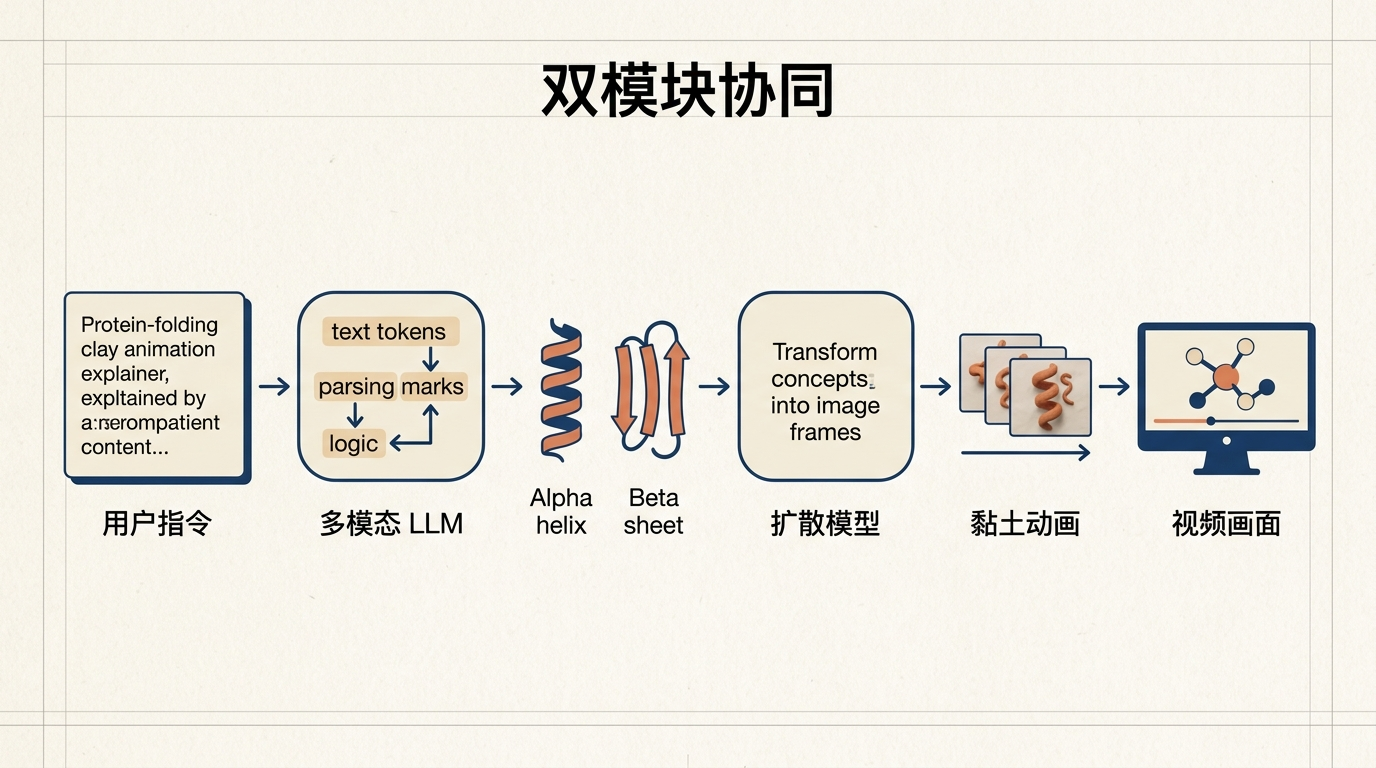
关键的融合环节,靠的是跨模态注意力机制。就像你看菜谱做菜时,眼睛盯着文字,手却能对应到食材上,模型会让文字指令里的每一个关键词,都精准“盯”住视频里该变化的部分,比如“黄昏风格”对应光影,“液体镜子”对应材质,绝不会把涟漪画到手臂上。
你让AI生成一个滚动的弹珠,它不会凭空让弹珠飘起来,也不会在撞到墙后还直线前进——这就是多模态模型的新本事:理解物理规律。
过去的视频生成模型更像“拼图选手”,靠海量数据里的画面碎片拼接内容,根本不懂什么是重力。而现在的模型,相当于内置了一个迷你物理引擎。你可以把它想象成小时候玩的弹珠台:弹珠的重量、台面的摩擦力、碰撞的角度,这些规则都提前写进了模型的“潜意识”里。

实现这一点,靠的是在训练时加入物理知识数据。比如给模型看几百万段真实的物体运动视频,让它自己总结“物体下落会加速”“硬的东西撞在一起会反弹”这些规律;或者直接把物理引擎生成的模拟数据喂给模型,让它学习精确的运动参数。
当然,这事儿没那么简单。比如要让AI生成“字母表物品视频”,它不仅要把C对应水豚、D对应迪斯科球,还要保证每个物体放在桌子上时,底部都有真实的阴影,被碰一下会有符合重量的晃动。这需要模型同时处理语义对应、视觉风格和物理规则,相当于一边写文案、一边做动画、一边当物理老师。
多模态模型看起来无所不能,但它的天花板依然清晰。
第一个难题是“时序一致性”。生成一张图片容易,但要生成1000帧连贯的视频,就像让一个人连续画1000张一模一样的脸——每一秒都可能出现人物脸型变形、物体突然消失的bug。目前的解决办法是先画好“关键帧”,再用模型补中间的过渡帧,就像动画片的原画师和动画师分工,但还是没法做到100%完美。
第二个难题是“计算成本”。要处理这么多模态的数据,模型的参数规模动辄几十亿,训练一次要花掉几百万度电,推理一段视频的时间,可能比你自己拍一段还长。现在的技术只能靠“压缩”和“蒸馏”——把大模型的知识“灌”给小模型,就像让学霸给学渣划重点,虽然能省点力气,但总会漏掉一些细节。
还有最棘手的“幻觉问题”。你让它生成蛋白质折叠视频,它可能会凭空造出一个不存在的分子结构,因为它只是在“模仿”数据里的画面,不是真的懂生物学。这在医疗、教育这些严肃领域,可能会造成致命错误。
当AI能看懂你的画、听懂你的话、还能造出符合现实逻辑的视频时,我们其实在见证一个新的认知边界被打破:机器不再是只会执行指令的工具,它开始拥有“理解”世界的雏形。
当然,这绝不意味着AI能取代人类。它不懂为什么蛋白质折叠会影响生命,也不懂一段黄昏漫步的视频里,藏着人的情绪——这些需要温度和深度的认知,依然是人类的主场。
AI懂规则,而人类懂意义。 未来的内容创作,会是一场人和AI的协作:你负责提出想法、注入情感,AI负责把这些想法变成看得见、动起来的现实。就像画家和画笔的关系,画笔越好用,画家的想象力才能走得越远。