对抗知识焦虑,从看懂这条开始
App 下载
AI画的图总糊?给它装个「频率雷达」就好
ImageNet|约翰霍普金斯大学|字节跳动|细节纹理处理|频率雷达|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载ImageNet|约翰霍普金斯大学|字节跳动|细节纹理处理|频率雷达|多模态视觉|人工智能
你有没有过这种经历?让AI画一只猫,轮廓像模像样,可凑近看,猫毛像打了马赛克;让它画老砖墙,整体结构没问题,砖缝却糊成一片。这不是你要求不够细,也不是AI偷懒——直到2026年4月,字节跳动与约翰霍普金斯大学的团队才揪出真正的病根:AI画图时,对「整体轮廓」和「细节纹理」的处理天生失衡。他们给AI装了个「频率雷达」,让它像人眼一样先看大局再抠细节,直接在ImageNet上刷出了新的最高精度。
你可以把一张图想象成一首交响乐:低频是沉稳的大提琴,负责勾勒整体轮廓和色彩;高频是细碎的小提琴,负责毛发、砖缝这些细节纹理。传统流匹配模型——现在AI画图的主流框架之一——就像一个只会听大提琴的指挥,全程把小提琴声当成杂音。
问题出在噪声上。AI画图是从一片噪声里「提纯」出清晰图像的过程,传统模型会把噪声均匀泼在整张图上,但在频率视角下,噪声对高频细节的冲击要猛烈得多,就像在小提琴声部突然砸进一块石头。等AI终于处理完低频轮廓,高频细节早被噪声冲得七零八落,自然只能画出糊成马赛克的纹理。
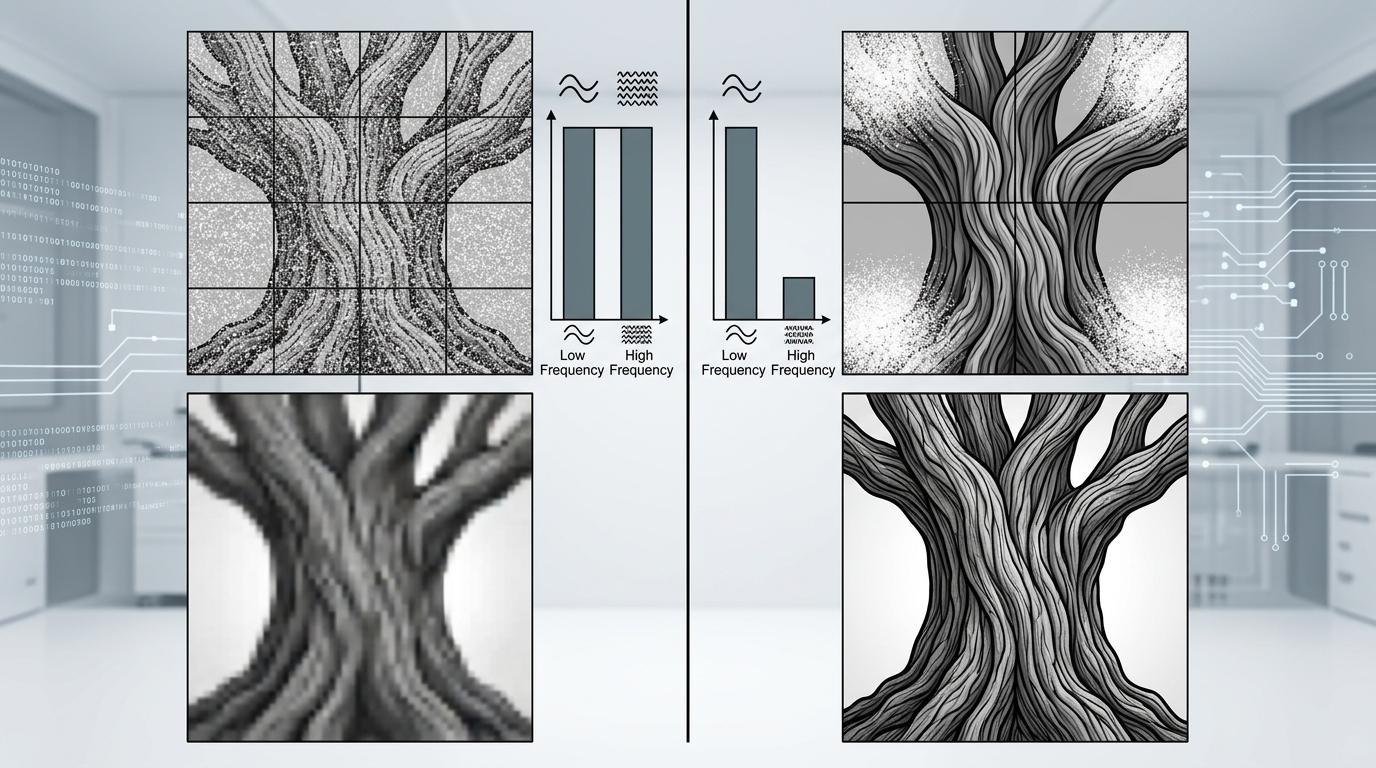
团队做了个实验:盯着AI画图的过程看频谱变化,发现低频信息在生成早期就快速成型,而高频信息要到最后才慢悠悠冒出来,还没等画清楚就到了收尾阶段——就像画家花99%的时间画轮廓,留1%的时间勾细节,效果能好才怪。
既然AI天生分不清高低频,那不如直接给它装个「雷达」——这就是FreqFlow的核心思路:把频率分析直接焊进AI的画图框架里。
它的双分支架构像给AI配了两个助手:一个是「频率专家」,专门负责拆解高低频信号,分别计算不同频率该怎么「提纯」;另一个是「合成大师」,拿着频率专家的指导,在原图基础上把细节补回去。
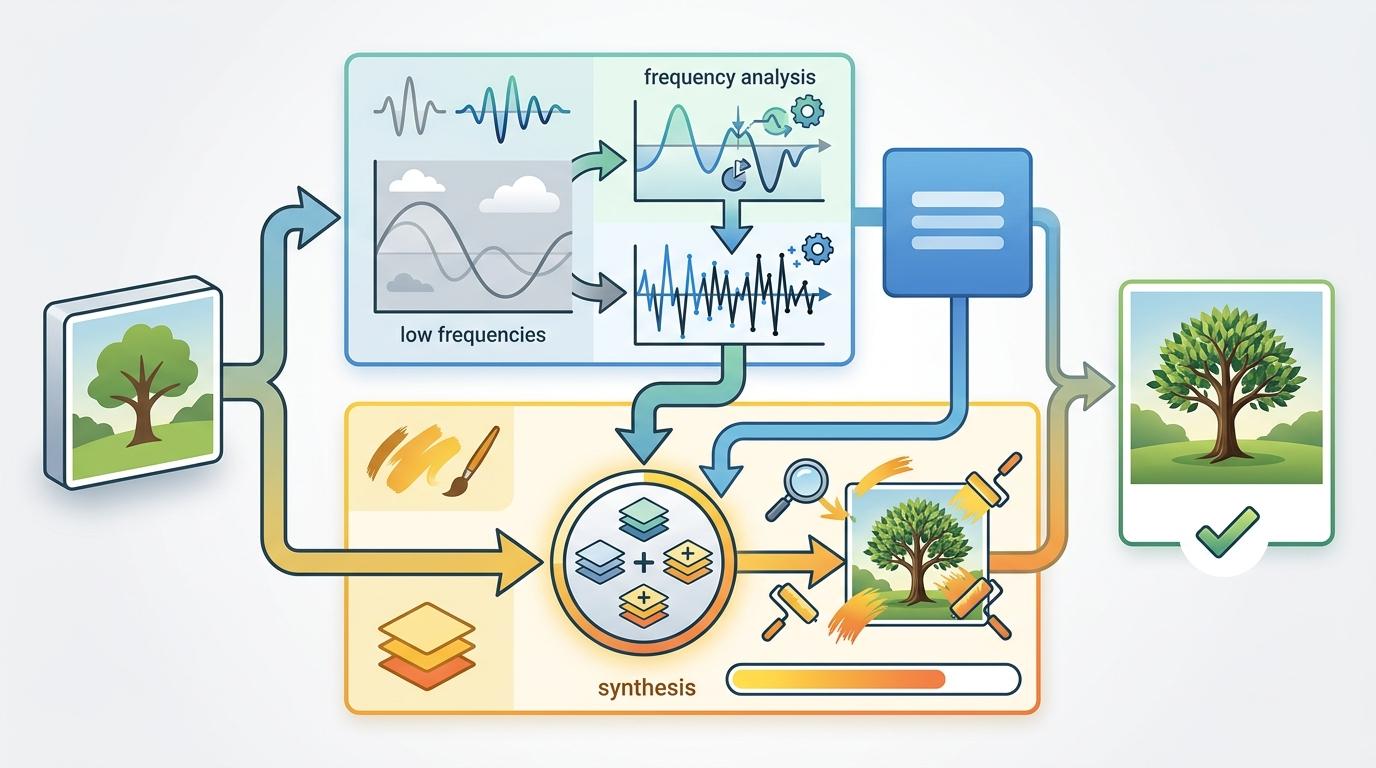
更聪明的是「动态权重」设计。就像人眼先扫一眼整体,再聚焦细节,AI画图的早期,这个权重会全力偏向低频,先把猫的轮廓、砖墙的结构搭起来;到了后期,权重自动转向高频,把猫毛的纹理、砖缝的棱角一一补全。这个权重不是预设的,是AI自己从数据里学来的——它会根据当前画到哪一步,自动调整注意力。
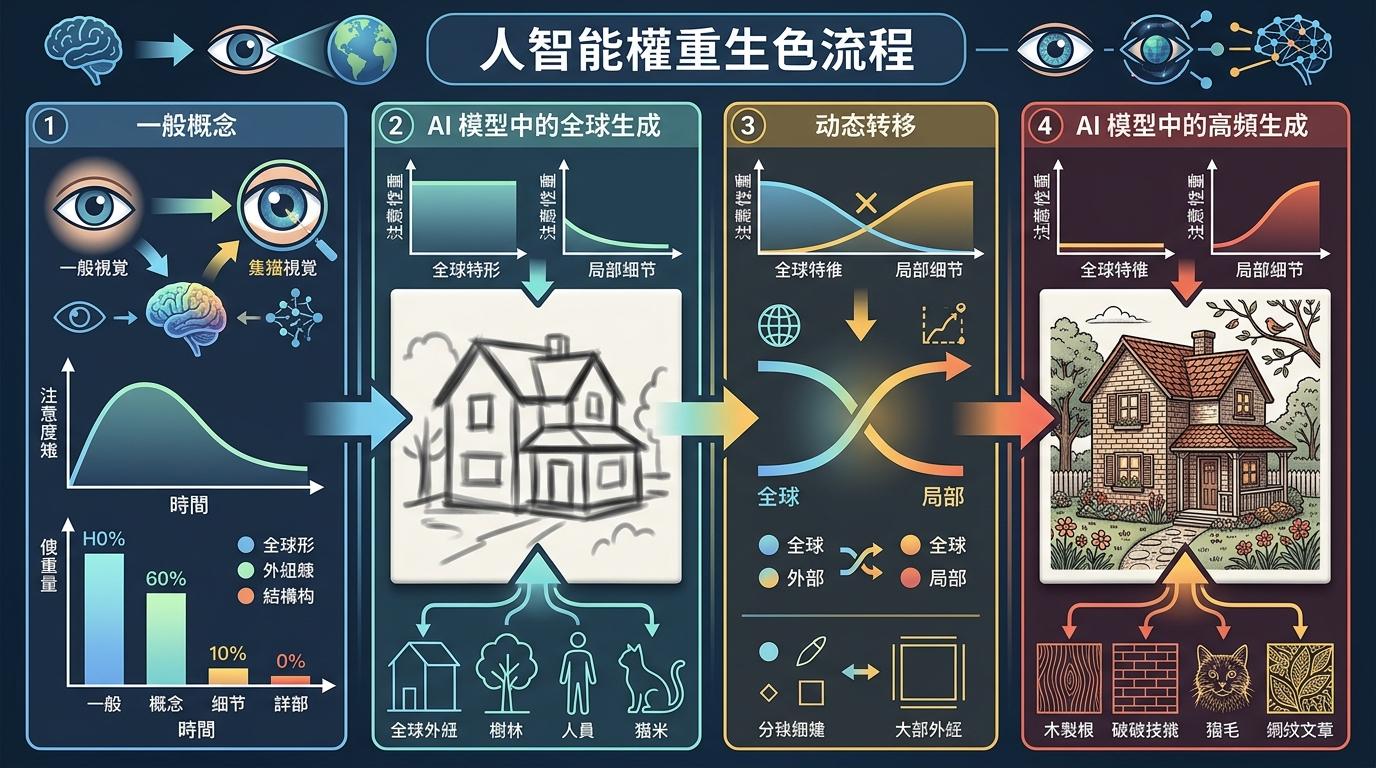
训练时,团队还专门加了「频域监督」:不仅要让画出来的图看起来像,还要让它在频率层面和真实图完全匹配。相当于给AI同时立了两个规矩:既要画得像,也要「听起来像」那首完整的交响乐。
效果是实打实的:在ImageNet 256×256分辨率测试中,FreqFlow用10.8亿参数跑出了1.38的FID值——这个衡量生成图真实度的核心指标,比之前最好的扩散模型低了近1,比传统流匹配模型低了0.68。更关键的是,它的高频恢复误差从0.69降到了0.48,那些之前糊成马赛克的细节,终于能看得清纹理了。
但它也不是没有缺点。双分支和频域计算带来了额外的开销,训练和推理的时间都比传统模型长——就像给指挥加了个小提琴声部的副指挥,虽然曲子更好听了,但排练时间也变长了。未来要走向实用,还得想办法把这个「雷达」做轻做快。
更值得关注的是,这个思路不止能用来画图。视频里的帧间闪烁、超分辨率里的细节丢失、甚至气候模拟里的小尺度波动,本质上都是「高频信息没处理好」的问题。给AI装个「频率雷达」,说不定能解决一大串类似的难题。
过去我们总觉得,AI要画得更好,就得堆更多参数、用更复杂的网络。但FreqFlow给了另一个答案:有时候不用教AI怎么画,只需要教它怎么「看」——像人一样,先看整体,再看细节,分清什么是大提琴,什么是小提琴。
让AI先看懂世界,再画好世界。 这个思路的价值,远不止刷出一个新的SOTA。它提醒我们,AI的进化不一定是变得更复杂,有时候只是变得更「懂」——懂信息的本质,懂人类感知的逻辑。