对抗知识焦虑,从看懂这条开始
App 下载
单标记微调搞定跨域监控,AI安全有了新解法
推理能力提升|Anthropic团队|跨域风险识别|单标记微调|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推理能力提升|Anthropic团队|跨域风险识别|单标记微调|AI安全治理|人工智能
当你用AI聊天时,后台正有另一个AI盯着——判断你有没有问危险问题,AI自己有没有越界。过去要训练这种“AI监工”,得给每个领域单独标注数据,成本高到离谱。但2026年Anthropic团队的研究,把这件事简化到了极致:只让模型输出“1”或“0”两个标记,居然不仅能跨领域识别风险,还顺便提升了模型的推理和摘要能力。这就像让一个只会做判断题的学生,突然把论述题也答得超出预期。这种“简单到离谱”的方法,为什么能撬动AI安全的核心难题?
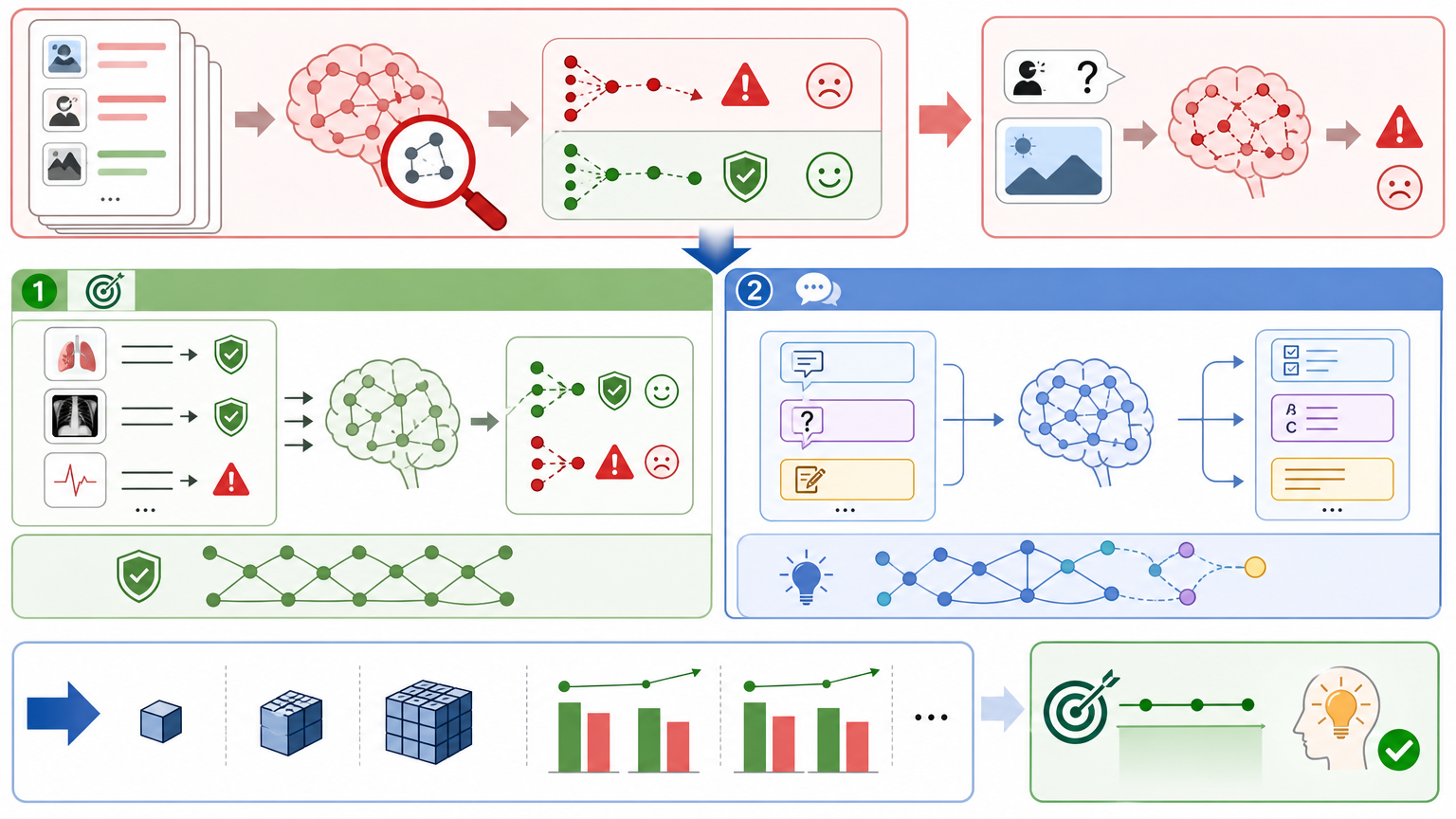
你可以把大语言模型想象成一个刚毕业的实习生,什么都懂一点,但做具体任务得手把手教。过去训练AI监工,要么让它对着提示词临时判断,要么花大成本做全任务微调。而Anthropic的单标记分类SFT,相当于只给实习生练判断题:给一段对话,只需要回答“是(有风险)”或“否(无风险)”,而且只针对这个答案计算对错,其他内容一概不管。
这种训练方式的效率高得惊人——计算量只有传统微调的几分之一,却能让模型抓住“风险判断”的核心逻辑。实验数据更让人意外:原本只练判断题的模型,居然能把这种能力迁移到更复杂的任务上——比如让它先写一段推理过程再判断风险,它的AUC(分类准确率指标)从0.84直接跳到了0.94;甚至在做文本摘要时,它也会自动突出风险内容。
更关键的是跨领域能力:在“网络攻击检测”任务上训练好的模型,直接拿去做“AI越权监控”,能达到专门训练该模型75%的效果。就算目标领域只有4000条数据,搭配14倍量的相邻领域数据,性能还能持续提升。这意味着,企业不用再为每个细分风险场景单独标注数据,靠现有资源就能搭建起覆盖多领域的AI监控网。
当然,这种极简方法也不是万能的。Anthropic的研究里,模型出现了两种典型的“泛化失败”:一种是“溢出”——比如只练过“网络攻击”判断的模型,会把所有带“危害”的内容都标成风险,哪怕你问的是“化学危害”;另一种是“卡住”——如果新任务的数据风格和训练数据像,哪怕你问的是“用户是不是法国人”,它还是会盯着内容里的“攻击”关键词答“是”。
这些问题本质上是模型走了“学习捷径”:它不是真的理解了任务要求,而是记住了训练数据里的统计规律。为了破解这个难题,研究团队提出了“分组两阶段训练”:先集中火力练分类,让模型把风险判断的逻辑刻进参数里;再用通用指令训练,让它学会听懂新任务的要求。这种方法既避免了分类信号被稀释,又能让模型保持对新提示的敏感性——在不同规模的模型上测试,分类能力几乎没有损失。
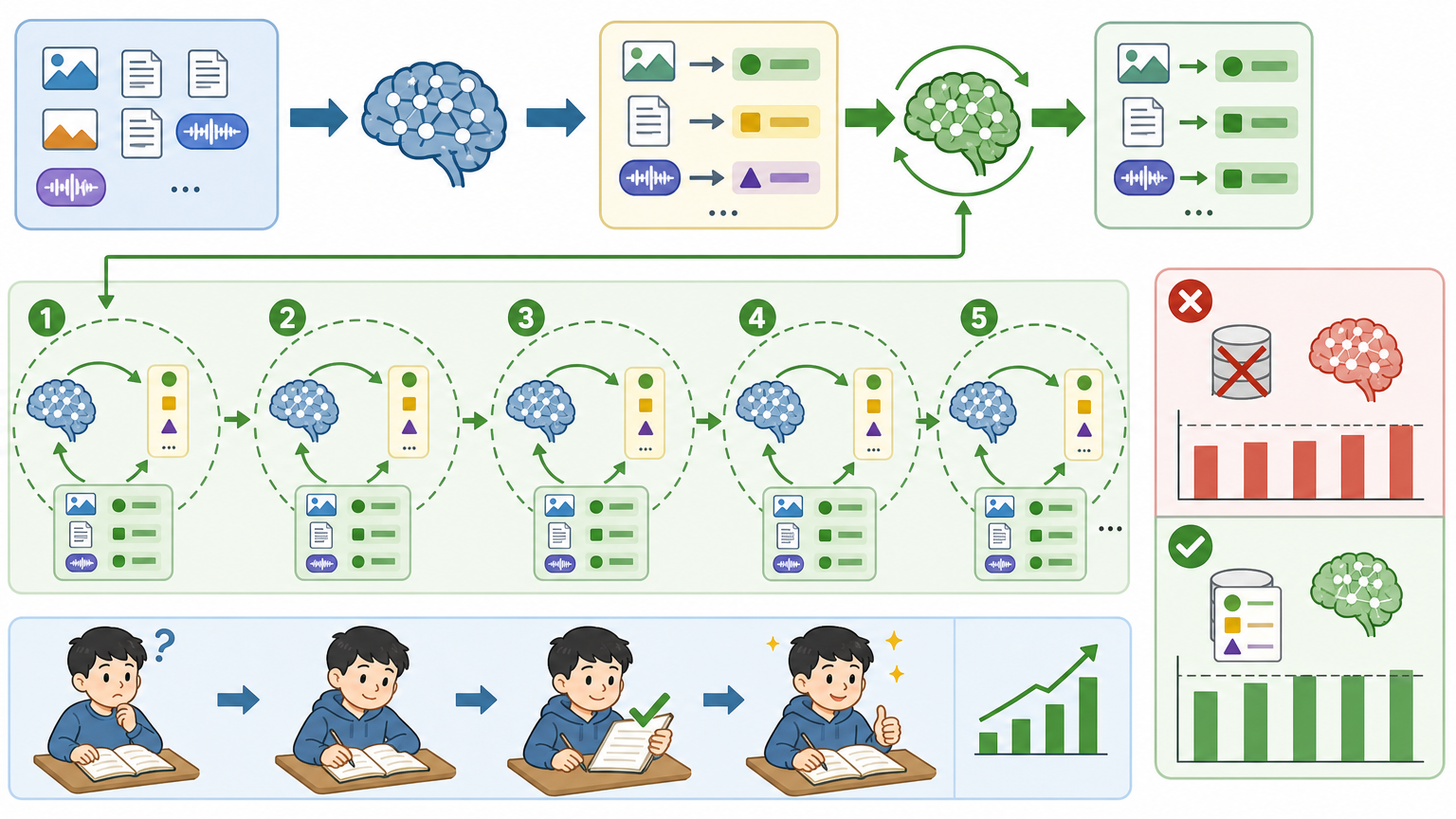
更巧妙的是“自举式训练”:用模型自己输出的推理结果当标签,再反过来训练单标记分类。经过5轮迭代,模型在没有任何真实标签的情况下,性能居然接近了有监督训练的效果。这相当于让学生自己改作业,还越改越好,为解决“数据稀缺”这个AI行业的老难题,提供了新的思路。
当我们把目光从实验室转向产业落地,单标记SFT的优势就更明显了。首先是成本:用LoRA(低秩适配)技术做单标记微调,只需要调整模型的少量参数,一台普通的GPU服务器就能搞定,比强化学习的成本低了一个数量级。其次是速度:训练一个跨领域的AI监工,只需要几天时间,企业能快速响应新的风险场景。
但落地也有需要注意的细节:比如训练数据的选择,必须覆盖足够多的风险类型,避免模型出现“溢出”;再比如要和企业现有的AI安全体系结合——它可以作为第一道防线,快速过滤大部分风险,再把疑似案例交给更复杂的模型或人工审核。
Salesforce的实践也验证了这一点:他们把基于单标记SFT训练的Claude模型集成到Slack里,既提升了代码生成的效率,又能实时监控是否有恶意指令。这种“轻量级监控+核心业务赋能”的模式,正在成为企业AI部署的标准配置。
当AI技术越来越复杂,我们反而在最简单的逻辑里找到了破局的钥匙。单标记分类SFT的本质,是抓住了AI安全的核心:不是用复杂的技术堆砌防线,而是让模型学会“判断风险”的底层逻辑。
未来的AI安全,或许不需要越来越复杂的算法,而是需要更多这种“回归本质”的思考——用最少的成本,解决最核心的问题。毕竟,真正可靠的AI监工,从来不是那些只会照本宣科的“专家”,而是能抓住问题本质的“聪明人”。
简单即强大,本质即安全。