对抗知识焦虑,从看懂这条开始
App 下载
光计算破局电芯片瓶颈,烧钱换未来的赌局
数据中心能耗|功耗墙|内存墙|GPU集群|光计算芯片|半导体技术|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载数据中心能耗|功耗墙|内存墙|GPU集群|光计算芯片|半导体技术|前沿科技
当AI大模型把GPU集群的功耗推到兆瓦级,当数据中心的电费账单比硬件成本还高,所有人都在等一个破局者。2026年4月,港交所迎来了一家特殊的上市公司:它靠卖光计算芯片,三年营收刚过2亿,却亏了25亿;开盘涨了380%,市值冲过800亿港元,散户认购超5700倍。这不是资本的狂热泡沫——它瞄准的,是卡住所有AI公司脖子的两道墙:电芯片的“内存墙”和“功耗墙”。而光,成了唯一能穿墙的钥匙。
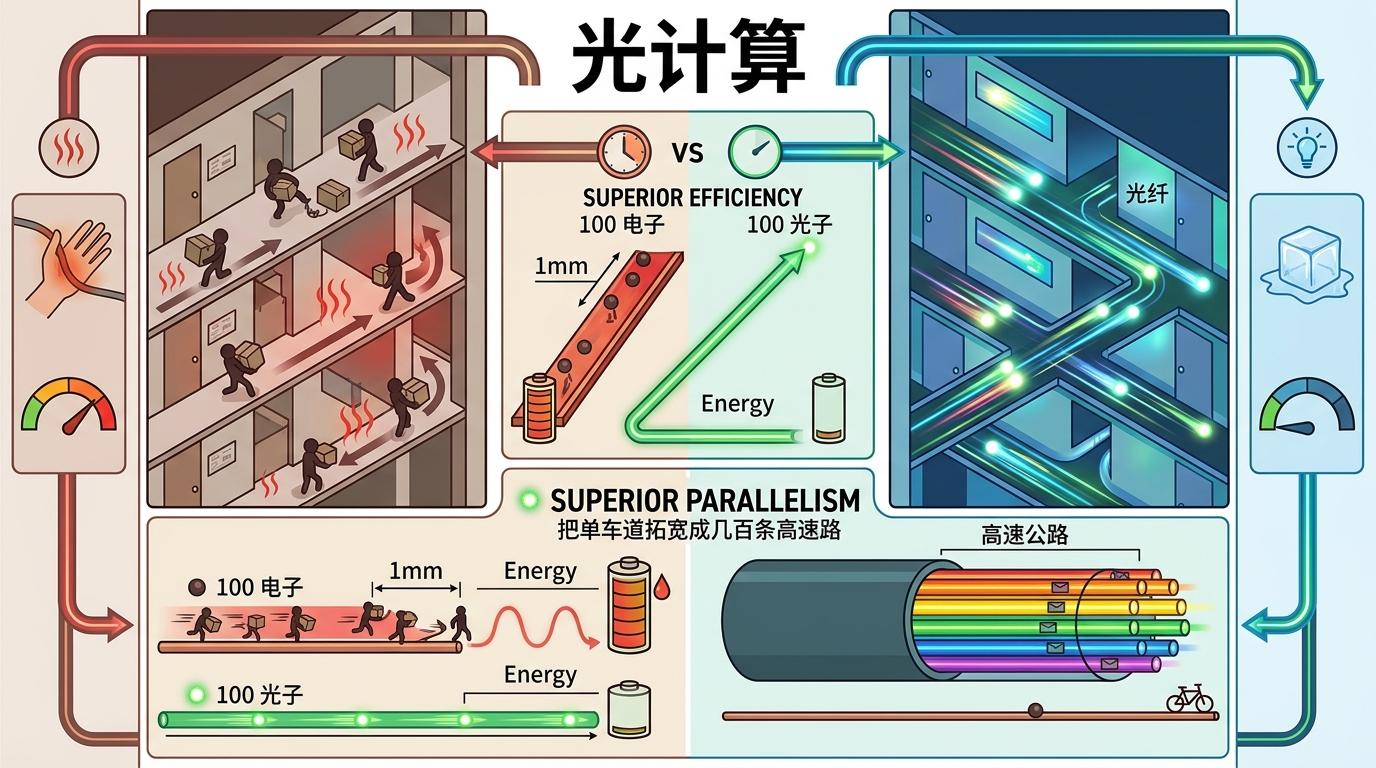
你可以把传统电芯片想象成一个挤满人的写字楼:计算核心是办公室,内存是仓库,数据是需要搬运的文件。电子就是跑腿的员工,在铜线走廊里挤来挤去——不仅慢,还会因为摩擦(电阻)发热,跑太快整栋楼都要过热断电。这就是“内存墙”(数据跑不赢计算)和“功耗墙”(发热限制速度)。
光计算的思路,是把写字楼的走廊换成光纤高速公路,用光子当快递员。光子没有质量,跑起来接近光速,而且不会因为摩擦发热——100个光子跑完全程的能耗,可能还不如一个电子爬1毫米铜线的能耗。更狠的是,光子能“分身”:一根光纤里可以同时跑几百束不同颜色的光,每束光都能扛着数据独立传输,相当于把单车道拓宽成几百条高速路。
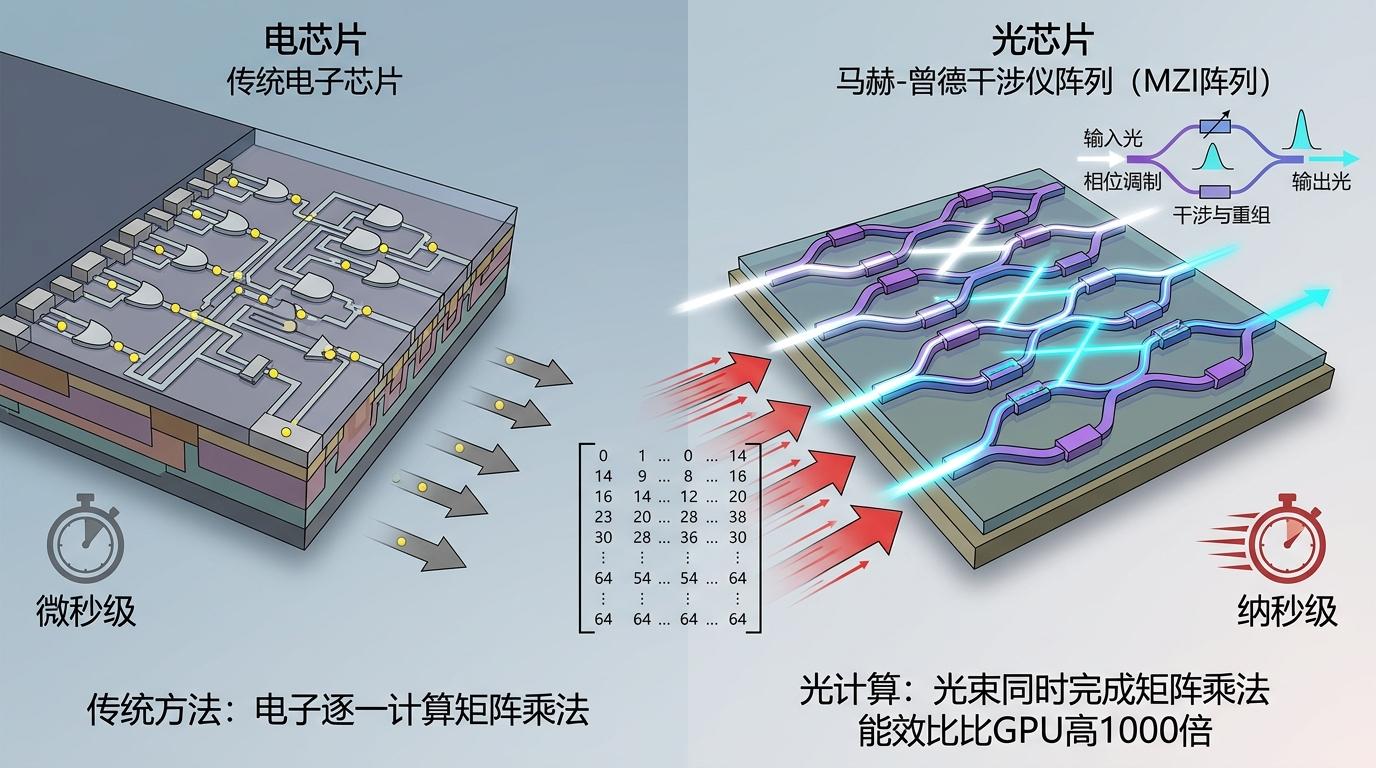
最核心的突破在矩阵乘法——这是AI大模型最耗算力的工作。传统电芯片要算一个64×64的矩阵,得让电子挨个跑遍所有节点;而用光计算的马赫-曾德干涉仪阵列,一束光就能同时完成所有乘法运算,延迟从微秒级降到纳秒级,能效比能比GPU高1000倍。
2017年,沈亦晨在《自然·光子学》发表的封面论文,给光计算的产业化画了第一张施工图。9年后,他创立的公司成了“全球光计算芯片第一股”——不是因为盈利,而是因为它把实验室里的原型,变成了能卖出去的产品。
这家公司的光互连产品,已经能把GPU集群里的数据传输延迟降低90%,让原本闲置的计算资源多跑50%的任务。在中国的光互连市场,它占了88%的份额,连续两年光计算芯片出货量全球第一。英伟达砸40亿美元抢光通信产能、AMD收购光互连公司,巨头的动作其实在给它背书:光互连就是下一代AI基础设施的标配。
但光鲜的技术背后,是烧钱的无底洞。三年研发砸了11亿,2025年一年就亏了13亿——相当于每赚1块钱,要亏12块多。它的客户集中度超过80%,面对头部客户连定价权都没有,2025年给某大客户的产品毛利率只有23.4%。更棘手的是,它的资产负债率高达473%,IPO募的24亿港元,按现在的烧钱速度,只够撑四五年。
光计算不是要完全取代电芯片,而是要和电芯片搭伙干活——光子负责高速传输和矩阵运算,电子负责存储和非线性逻辑,就像让快递员管运输,办公室职员管处理。但这个“搭伙”的过程,满是技术坑。
首先是制造难。光子芯片对精度的要求是纳米级,一根光纤和芯片的对准误差不能超过头发丝的万分之一,稍微偏一点信号就没了。磷化铟激光器是光芯片的核心,但全球产能被几家公司垄断,连英伟达都要砸钱抢产能。其次是光电转换的损耗:光信号进芯片要转成电,出芯片再转成光,这两步的能耗和延迟,至今还没降到理想水平。
更现实的是市场的慢热。现在光计算的主要客户是数据中心和AI公司,但这些客户已经在电芯片上投了万亿级的成本,要让他们换赛道,光有技术优势不够,还得把成本降到和电芯片差不多。2025年国内光互连市场规模57亿,这家公司只拿到了7500万——从千万到数十亿的鸿沟,它得在钱烧完之前跨过去。
当我们为AI大模型的参数突破欢呼时,很少有人注意到,支撑这些参数的电芯片,已经摸到了物理的天花板。光计算不是什么遥不可及的黑科技,它是被逼出来的破局者——用光子的速度,补电子的短板;用资本的烧钱,换技术的时间。
光的速度有多快,光计算的未来就有多诱人,但这条路的每一步,都要踩着烧钱的火焰前进。算力的未来在光,但光的落地在人。我们赌的不是某家公司的成败,而是人类能不能用更聪明的方式,突破物理世界给我们设下的限制。毕竟,从电到光的跨越,从来都不是技术的革命,而是认知的突围。