对抗知识焦虑,从看懂这条开始
App 下载
AI推理成本大降,产业跃迁的关键杠杆已至
自动化执行|算力效率|开源项目|AI推理成本|OpenClaw|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动化执行|算力效率|开源项目|AI推理成本|OpenClaw|AI智能体|人工智能
2026年春天,OpenClaw的GitHub星标冲破35万,成为史上增长最快的开源项目之一——它不是又一个聊天机器人,而是能跨软件系统帮人真干活的AI代理。当开发者们忙着用它自动写代码、调流程时,企业老板们盯着的却是另一个数字:一次AI调用的算力成本。毕竟,模型越聪明,推理时吃掉的算力就越多,当智能体要支持长时运行、工具调用的完整链路,推理成本可能先于业务价值失控。这背后,一场关于AI推理范式的革命正在发生,而效率,成了决定产业能否真正跃迁的核心。
你可以把AI推理的演进看成一场能力升级:最早的Chat阶段,就像你问朋友一个问题,他张嘴就答,处理的内容不过几百到一千个Token——相当于几百字的对话;到了Thinking阶段,朋友会先在心里过一遍推理步骤,再给你答案,这时候要处理的Token能到几千个;而到了Agent阶段,朋友不仅要帮你想,还要自己查资料、用工具、甚至帮你把事做完,10分钟内处理百万级Token都成了常态。
这不是简单的量的变化,而是推理范式的质变。在Chat阶段,推理只是单次问答;到了Agent阶段,它要支撑长时记忆、工具调用、多轮决策的完整链路。比如企业智能体,能像一个全职员工那样,记住客户的历史需求,调用公司的业务系统,甚至自主完成合同初稿的生成和审核。但这种能力的代价是,对推理系统的吞吐量、上下文长度和稳定性要求,都被推到了前所未有的高度。
要支撑Agent这样的复杂推理,光靠模型升级远远不够,得靠软硬件的协同优化——就像给一辆跑车换引擎的同时,也要重新调校底盘和变速箱。
其中最核心的技术是模型量化。你可以把它理解成给AI模型“减肥”:原来的模型用FP32格式存储参数,就像用高清照片存每一个细节;现在降到FP8甚至FP4格式,就像把照片压缩成画质损失不大的缩略图,内存占用和计算需求能直接降几倍。比如NVIDIA的NVFP4格式,能实现3.5倍于FP16的内存压缩,关键任务的准确率下降还不到1%。
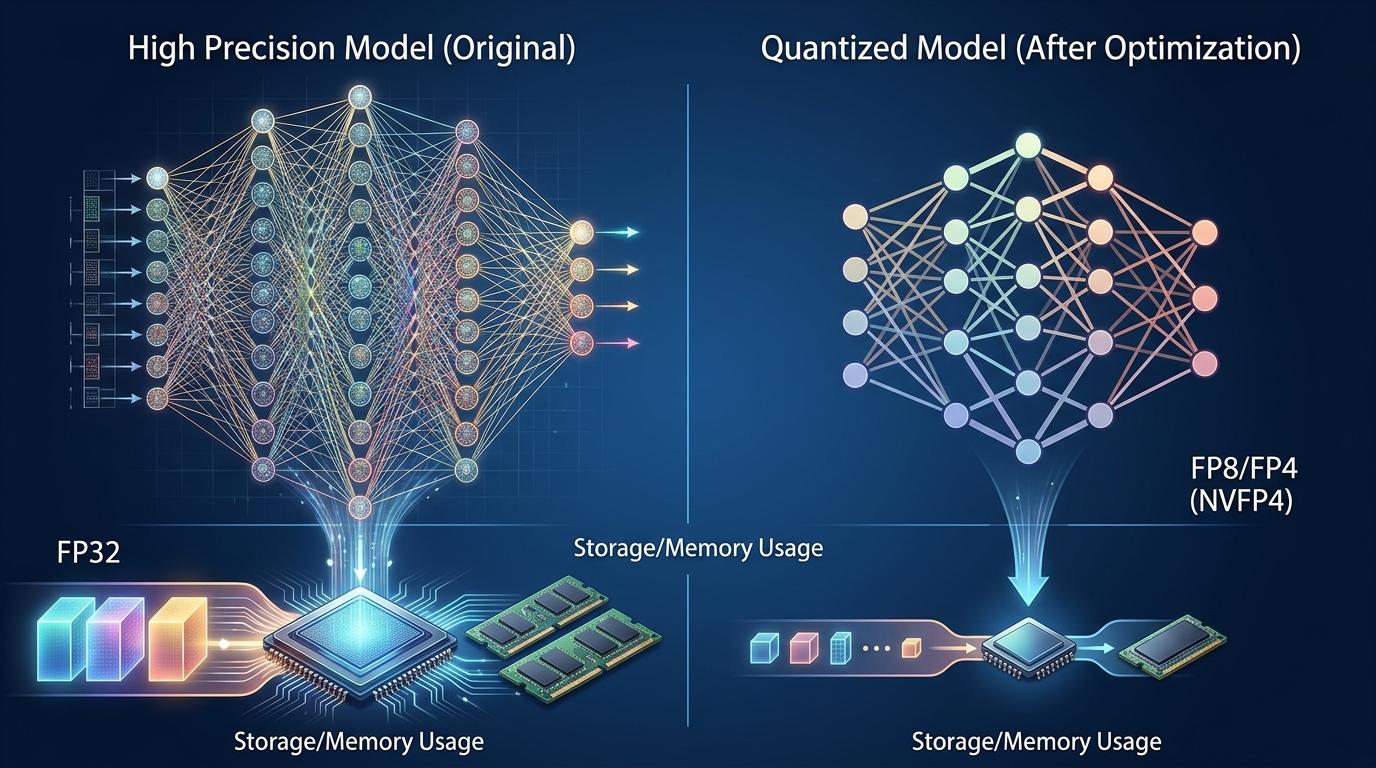
国内的技术团队也在这方面跑出了速度。阿里云基于自研PPU芯片,通过模型瘦身、算子优化和专家路由创新,实现了推理性能13.1倍的提升,直接把推理成本砍到了原来的一半。他们甚至把传统“先传输、后量化”的模式反过来,先量化再传输,让数据量减半,单算子性能提升了1.7倍。
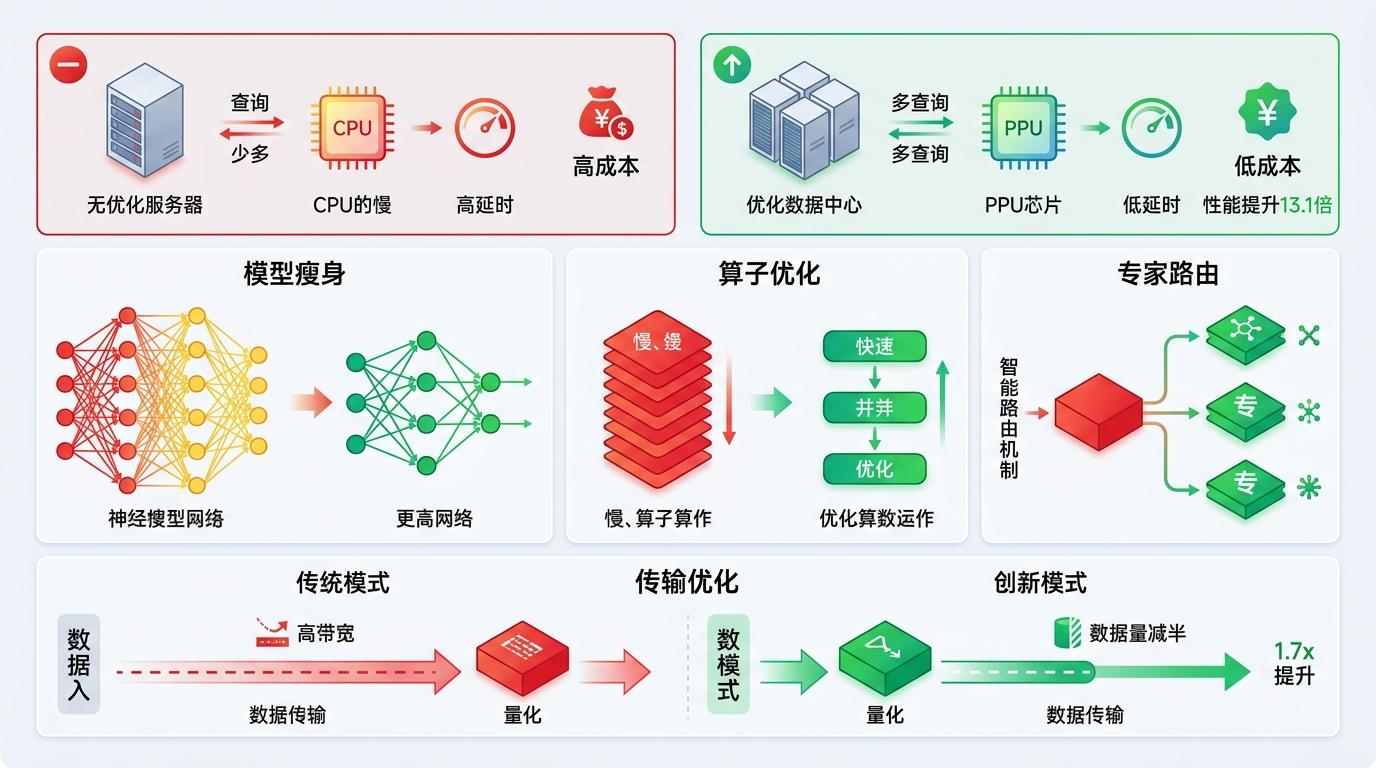
但这一切的前提是软硬件的深度适配。比如平头哥的芯片,从架构到软件栈都是自研的,能把很多复杂性留在底层消化,让企业不用太费劲就能把原来的模型迁移过来,用上新的算力体系。
过去AI行业拼的是模型参数谁更大、能力谁更强,现在大家突然发现,推理效率才是决定AI能不能真正落地的关键。毕竟,要是调用一次AI的成本比雇人还高,再聪明的模型也没法规模化应用。
这已经在改变整个产业的格局。比如AI Coding工具,大家讨论的不只是它能写多少代码,而是它能帮企业省多少算力成本;企业选AI模型的时候,也不再只看模型的智商,还要看每处理一个Token要花多少钱。
当然,挑战也依然存在。比如国内芯片和顶尖GPU还有差距,通信成本已经成了大规模集群推理的瓶颈;Agent的安全问题也让人头疼——要是它拿着企业的权限乱操作,后果可能比成本失控更严重。但这些问题,也正在倒逼行业从更底层去思考:推理不只是要算得更快,还要更懂业务、更贴近场景。
当OpenClaw把AI从聊天窗口里放出来,当企业智能体开始走进真实的生产流程,AI的价值终于不再停留在实验室的报告里,而是变成了能帮人省时间、省成本的真实生产力。
推理效率的提升,就像给AI产业装上了一个高效的引擎。它不仅能让AI的成本降到企业能接受的程度,还能催生出更多原来不敢想的应用——比如让AI直接参与科学实验的设计,或者让工厂的生产线自主调整参数。
**推理效率,是AI产业跃迁的关键杠杆。**未来的AI,会越来越懂怎么“干活”,也会越来越便宜,而这一切,都始于我们对推理效率的重新定义。