对抗知识焦虑,从看懂这条开始
App 下载
让机器人不再瞎逛:EvolveNav破解导航三大死结
导航基准测试|机器人自主导航|上海交大|视觉语言导航|EvolveNav框架|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载导航基准测试|机器人自主导航|上海交大|视觉语言导航|EvolveNav框架|AI智能体|人工智能
想象一下:你对着家里的服务机器人说“去卧室把我的笔记本拿过来”,它却在客厅转了三圈,最后停在冰箱前——不是它听不懂指令,是你永远不知道它“脑子里”在想什么。这正是大语言模型加持的导航机器人最尴尬的困境:决策像个黑箱,换个房间就迷路,还总在熟悉环境里“死记硬背”。直到上海交大等团队的EvolveNav框架出现,它让机器人第一次学会了“边导航边复盘”,甚至能自己给自己“改作业”,还在四大权威导航基准上拿到了第一。
视觉语言导航(VLN)——就是让机器人听懂人话、自己找路的技术——卡在了三个几乎无解的死结里。
第一个死结是“黑箱决策”:传统模型直接把摄像头画面和人类指令翻译成动作,没有中间推理过程。就像你问朋友“怎么去地铁站”,他不告诉你走哪条路,直接拉着你走,万一走错了,你根本不知道问题出在哪。研究显示,就算用注意力机制、梯度分析这些方法,也只能摸到模型决策的皮毛,没法真正追溯它的“思考逻辑”。
第二个死结是“标签荒”:要让机器人学会推理,得给它看大量“思考样本”——比如“看到沙发就左转,因为卧室在左边”,但这种标签要人工标注,成本高到离谱,还没法覆盖所有复杂场景。
第三个死结是“过拟合魔咒”:就算有了标签,模型也容易死记硬背,换个没见过的房间就立刻“失忆”。比如在训练时只见过木质地板的卧室,到了铺地毯的卧室,它就找不到北了。
EvolveNav的破局思路,是把机器人的学习分成了两步:先教它“有条理地想”,再让它“自己改自己的作业”。
第一阶段是“形式化思维链训练”:研究者设计了一套固定模板的推理标签——“我应该前往[地标]在我[方向]的观测点”,比如“我应该前往沙发在我左边的观测点”。这个模板用Tag2Text模型自动提取环境里的关键地标,再配上方向信息,完全不用人工标注。更关键的是,这种结构化标签比自由式推理快3倍,还能让机器人的每一步决策都有迹可循。
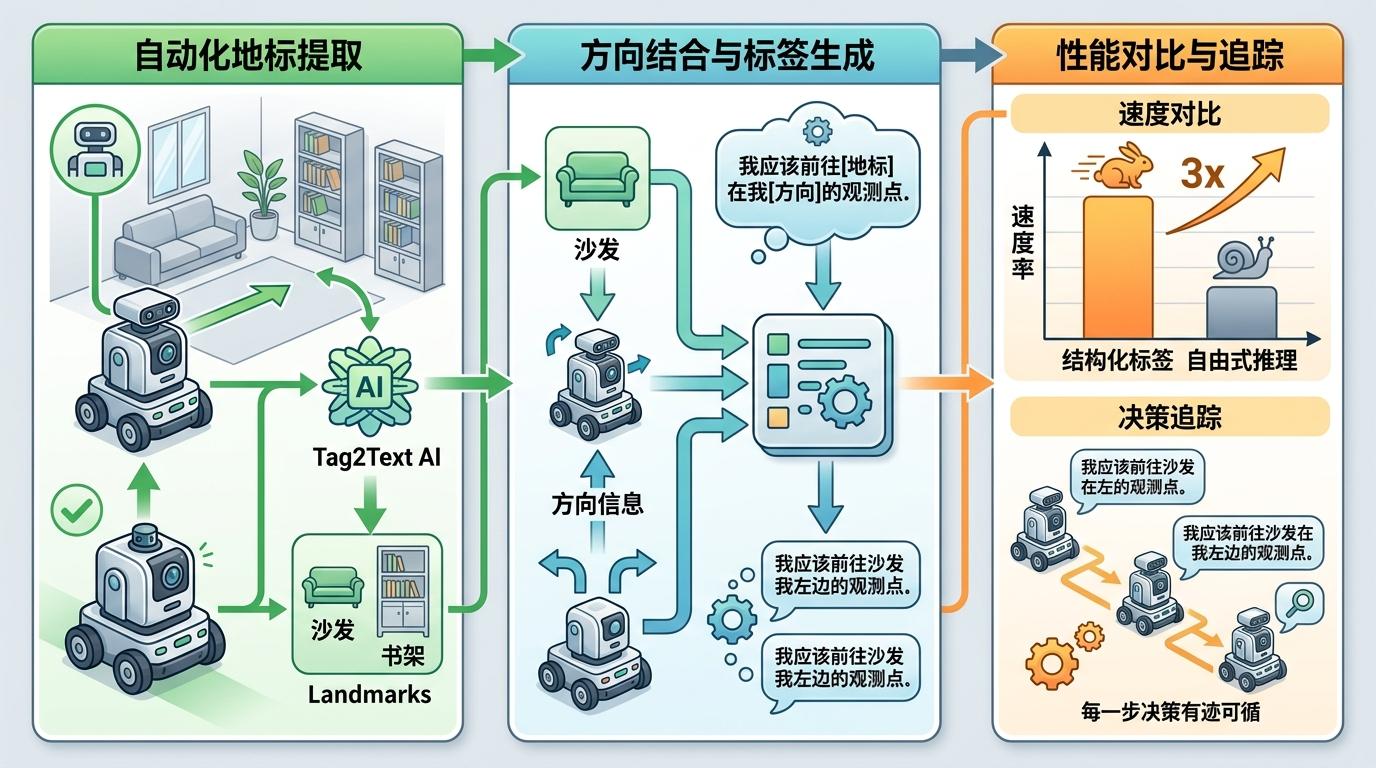
第二阶段是“自反思后训练”:这才是EvolveNav的核心。机器人导航时,如果某一步走对了,就把自己当时的推理当成新的“标准答案”存起来;如果走错了,就把正确推理和错误推理放在一起对比,自己总结“为什么错了”。相当于每次导航后,机器人都能给自己“改作业”,还能把错题整理成“错题本”,下次就不会再犯同样的错。
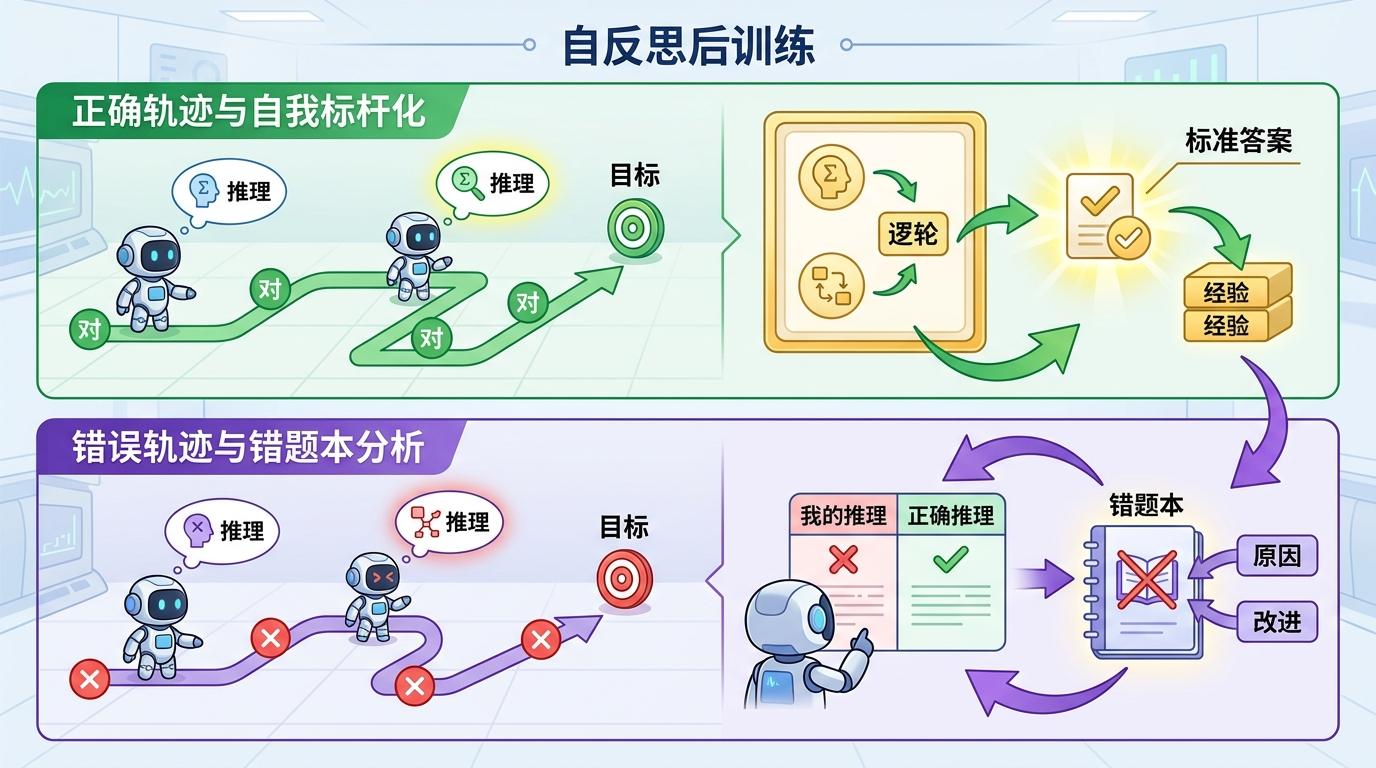
直给地说:
实验数据最能说明问题:在R2R数据集上,EvolveNav的路径加权成功率比基线模型提升了3.2%,导航误差明显降低;在CVDN对话导航数据集上,它的目标进度达到7.07,远超所有对比模型。更重要的是,它能在四个数据集上用同一个模型实现通用导航,不用针对每个场景单独训练。
但EvolveNav也不是完美的。比如在极端复杂的环境里——比如堆满杂物的房间,或者光线突变的场景,它的推理鲁棒性还有待提升;而且虽然它比传统模型省了人工标注成本,但训练时的算力消耗依然不小,要真正落地到低成本的服务机器人上,还需要进一步轻量化。
更值得关注的是,EvolveNav的思路不止适用于导航。这种“自进化推理”的框架,其实可以用到所有需要“边做边想”的具身AI任务里——比如机器人抓取、巡检,甚至是自动驾驶。它给具身AI指出了一条新的路:不是让模型“记住更多答案”,而是让它“学会怎么思考”。
我们总说要让机器人更“智能”,但很多时候,我们只是在让它“记住更多指令”。EvolveNav的突破,是第一次让机器人拥有了“自我迭代”的能力——它不用人类一遍遍教,而是能自己在实践中复盘、改进。
智能的本质,是学会自我进化。
未来的服务机器人,或许不会再是那个只会执行指令的“工具人”,而是能像人类一样,在错误中学习,在陌生环境里适应,甚至能告诉你“我刚才为什么走这条路”。而这一切的起点,就是让机器人先学会“思考”。