对抗知识焦虑,从看懂这条开始
App 下载
国产AI芯片不靠单芯片,靠集群追平国际巨头
系统级优化|AI芯片集群|海光信息|摩尔线程|寒武纪|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载系统级优化|AI芯片集群|海光信息|摩尔线程|寒武纪|AI算力|人工智能
2026年春,上海的财报发布会上传来一串让行业震动的数字:寒武纪一季度营收同比暴涨159%,经营现金流首次转正;摩尔线程成为首家实现季度盈利的国产GPU上市公司;海光信息单季营收突破40亿元,旗下芯片适配了全球99%的非闭源大模型。
没人会想到,三年前还在为单芯片性能差距焦虑的国产AI算力行业,如今能靠着另一条路径站稳脚跟——当国际巨头在单芯片性能上不断堆料时,中国企业选择用集群规模、系统优化和生态适配,硬生生在全球算力市场撕开了一道口子。这背后的逻辑,远不止“国产替代”四个字那么简单。
你可以把单芯片性能比作一辆跑车的百公里加速,而集群算力就是一整支专业车队的协同效率——前者靠极致的个体性能,后者靠精密的调度和配合。
海光信息的“CPU+DCU”双轮驱动战略就是最好的例子。DCU(深度计算单元)相当于专门拉货的重型卡车,负责AI训练和推理这类大负载任务;CPU则是调度全局的指挥车,处理逻辑运算和任务分配。这套组合的厉害之处在于,它能覆盖从十亿级端侧推理到千亿级模型训练的全场景需求,就像一支既能跑城市配送又能跨洲际运输的车队。
更关键的是生态适配。海光的深算三号已经和365款主流大模型完成适配,覆盖全球99%的非闭源大模型。这意味着不管客户用的是哪款大模型,都能直接在海光的算力平台上跑起来,不用再花几个月时间做适配优化——这在讲究效率的AI行业里,几乎是“即插即用”的竞争力。
而寒武纪则靠软件平台的普适性站稳了脚跟。它的产品能同时服务运营商、金融、互联网等多个行业,就像一个能同时搞定快递、生鲜、大件运输的物流平台。2026年一季度,寒武纪的合同负债同比增长超3亿元,相当于手里握着一大笔提前付款的订单,这是市场用真金白银投下的信任票。
在AI算力的世界里,“精度”是个绕不开的词。你可以把它想象成厨房的调料:做凉拌菜需要精准的盐量(高精度),做大锅菜可以适当放宽(低精度)。以前的AI芯片大多只能处理某一种精度的计算,就像只会做西餐的厨师,遇到中餐就抓瞎。
而新一代国产AI芯片已经能实现“全精度张量计算”——从FP4(最低精度)到FP64(最高精度)通吃,就像一个既能做分子料理又能做大锅饭的全能厨师。比如摩尔线程即将推出的“华山”芯片,集成了全精度张量计算单元,能支持从万亿参数大模型训练到端侧推理的所有任务。
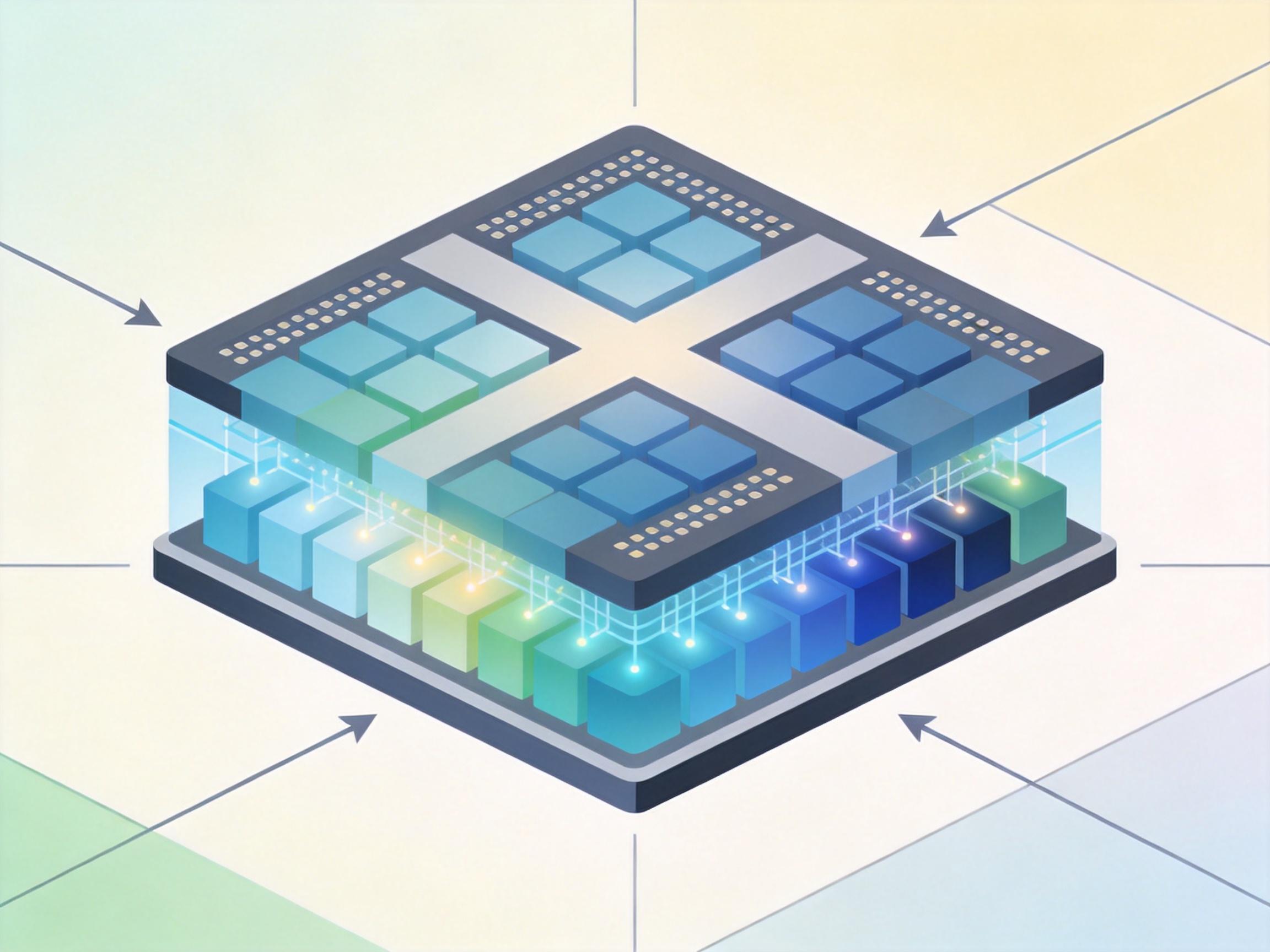
这背后的技术逻辑其实很简单:不同的AI任务需要不同精度的计算。训练大模型时需要高精度来保证模型准确性,而推理时用低精度就能满足需求,还能节省算力和能耗。全精度计算就像是给芯片装了一个自动调节的“精度开关”,让它能根据任务自动切换,不再“挑食”。
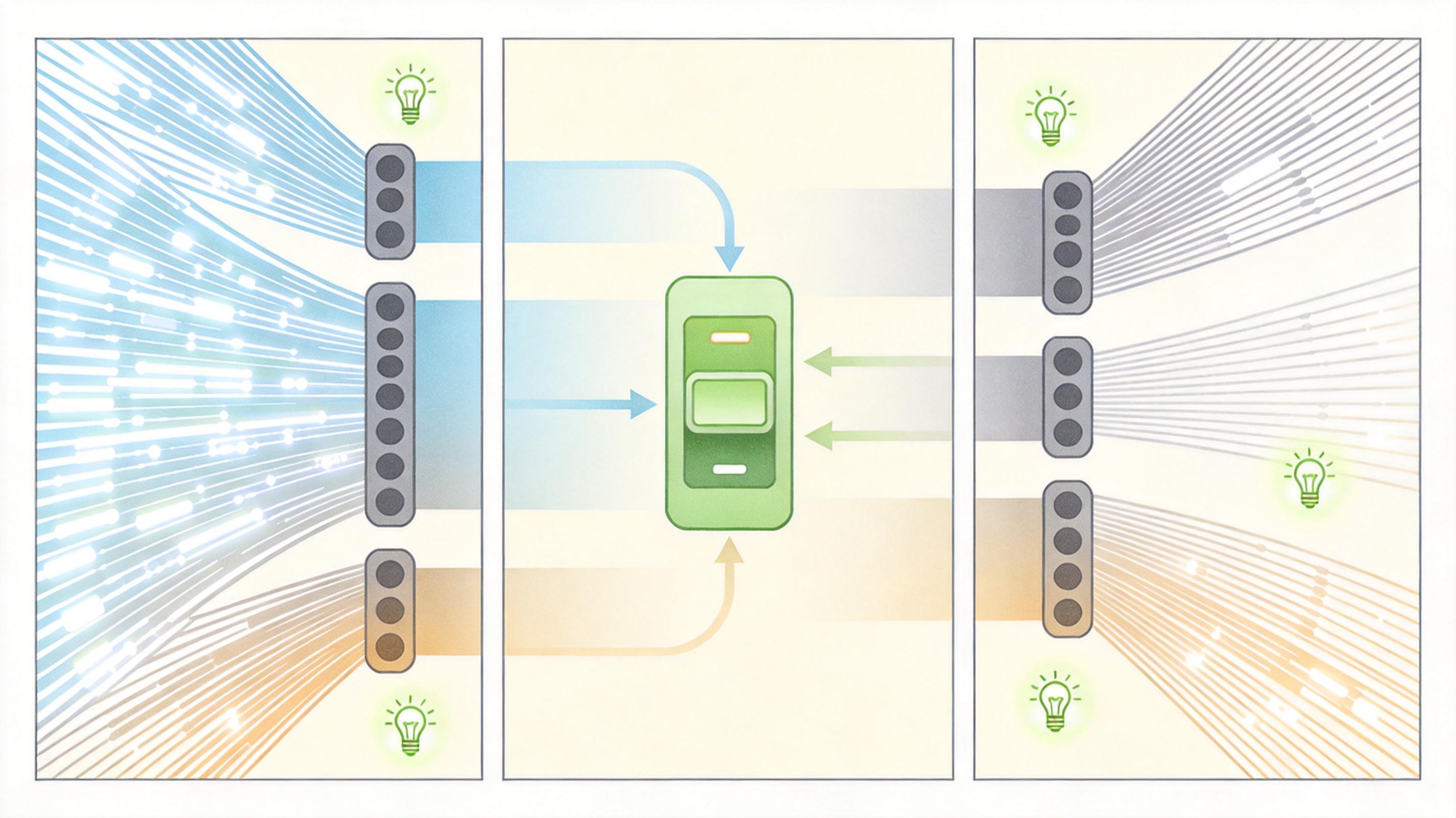
这种技术突破带来的直接好处就是成本下降。以前企业可能需要买好几款芯片才能覆盖所有任务,现在一款全精度芯片就能搞定,相当于用一套厨房设备做出了所有菜系。摩尔线程能在2026年一季度实现盈利,全精度计算带来的效率提升功不可没。
如果说芯片是算力的“硬件骨架”,那软件生态就是“神经脉络”。没有生态的芯片,就像一辆没有加油站和维修站的跑车,跑得再快也开不远。
这曾经是国产AI芯片最大的短板。国际巨头的CUDA生态已经积累了17年,拥有300多万开发者,形成了一个闭环的生态系统——开发者习惯了用CUDA写代码,企业习惯了用基于CUDA的芯片,新玩家很难打破这个循环。
但国产企业没有硬刚,而是选择了“补位”。海光信息依托“光合组织”聚集了6000多家生态合作伙伴,推出“星海计划”和“强芯固基”计划,从核心部件到应用软件全面打通生态链路;摩尔线程通过“摩尔学院”培养了45万开发者,让更多人学会用国产芯片的平台写代码。
更聪明的做法是兼容。很多国产芯片选择兼容CUDA生态,让开发者不用改写代码就能直接在国产芯片上运行程序,相当于给国产芯片装了一个“CUDA适配器”。这种渐进式的生态建设,虽然慢,但稳——就像在别人的公路旁边慢慢修自己的路,等路修到一定程度,自然会有车开上来。
当我们谈论国产AI芯片的突破时,很容易陷入“单芯片性能追平国际巨头”的误区,但其实中国企业已经走出了一条完全不同的路——不靠单点突破,靠系统协同;不靠硬刚生态,靠渐进补位;不靠短期盈利,靠长期布局。
“算力的未来,不在单芯片,在全生态。”这句话正在被越来越多的行业人认同。国产AI芯片的崛起,不是某一款芯片的胜利,而是整个产业链从设计、制造到应用的集体突围。
未来三年,当智算中心的竞争从比拼规模转向比拼能效比和集群利用率时,中国企业靠集群和生态积累的优势,或许会成为真正的制胜法宝。毕竟,在算力的世界里,跑得最快的不一定能赢,能跑最久、最稳的,才是最终的赢家。