对抗知识焦虑,从看懂这条开始
App 下载
Karpathy用AI搭了个会自己进化的知识库
智能知识网络|Markdown文章|自动生长知识库|个人维基|安德烈·卡帕锡|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载智能知识网络|Markdown文章|自动生长知识库|个人维基|安德烈·卡帕锡|AI产业应用|人工智能
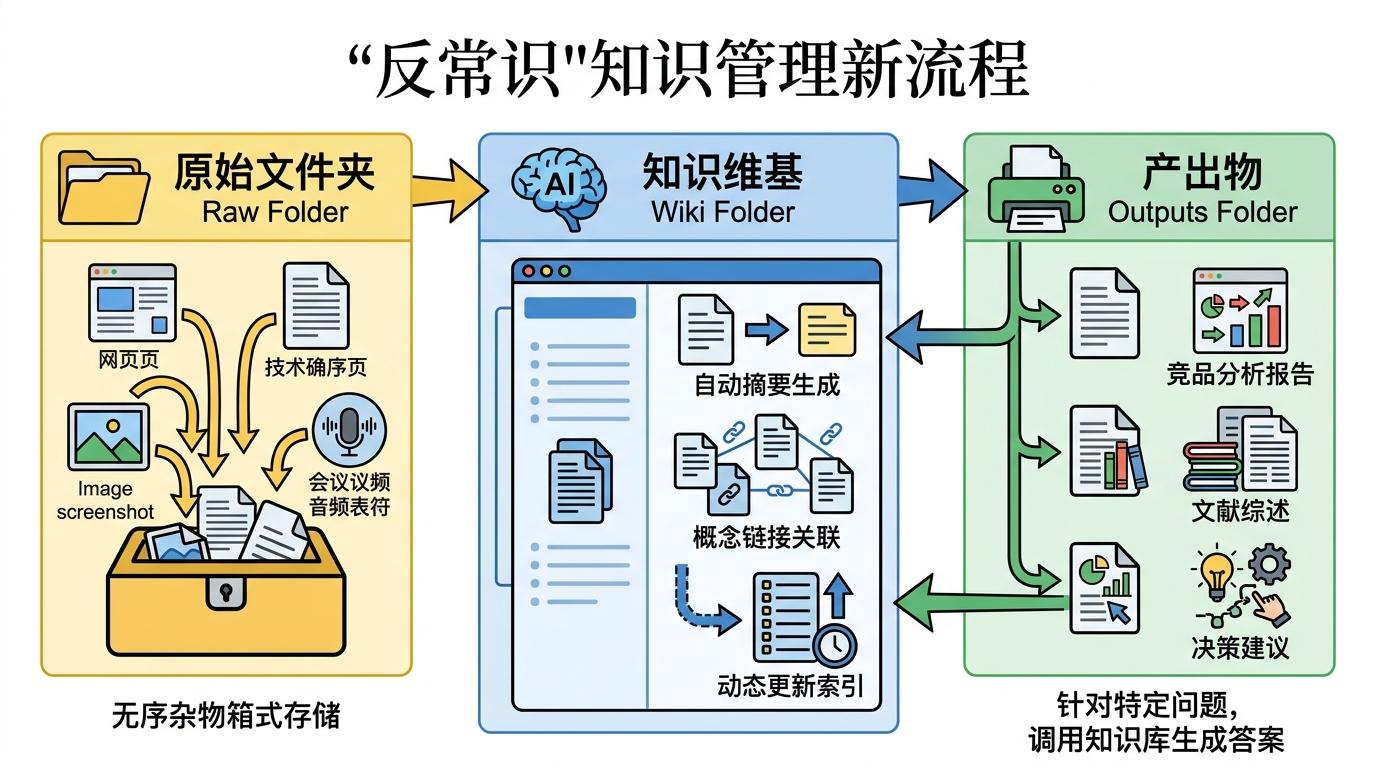
当你还在为散落各处的笔记抓耳挠腮时,有人已经把AI训成了专属图书管理员——前OpenAI研究员安德烈·卡帕锡的个人维基,靠100多篇Markdown文章、40万字内容,实现了知识的自动生长。不用复杂数据库,不用昂贵插件,三个文件夹加一份AI说明书,就完成了从信息碎片到智能知识网络的跃迁。
核心逻辑其实反常识:不是先整理再存储,而是先存储再让AI编译。raw文件夹像个不用分类的杂物箱,网页、论文、截图甚至会议录音转写,什么都能往里扔;wiki文件夹是AI输出的结构化知识,它会自动给每份资料写摘要、给相关概念加链接,还会维护一份随时更新的索引;outputs文件夹则存放针对特定问题的回答——从竞品分析到文献综述,AI会调用整个知识库的内容给出答案。
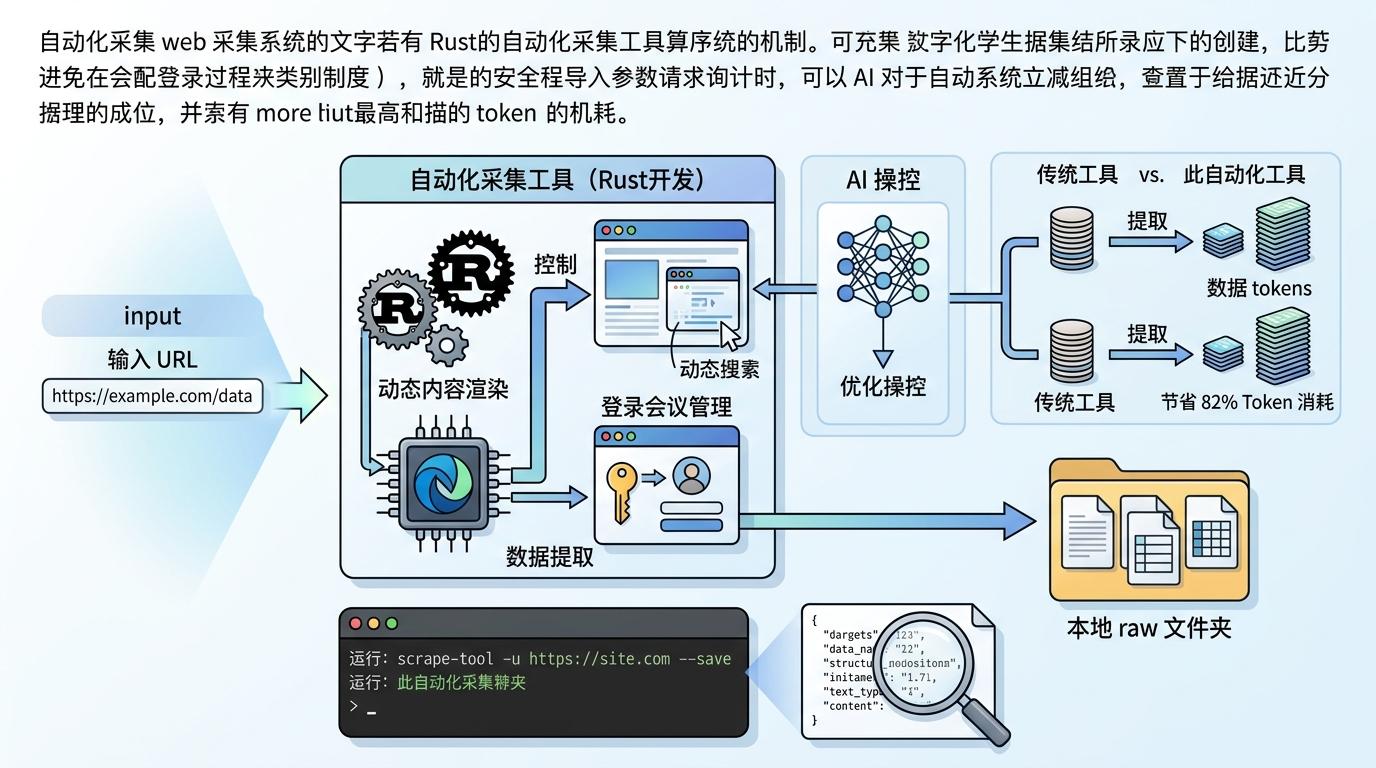
最关键的是自动化采集工具的加入。一款基于Rust开发的命令行工具,能让AI操控浏览器抓取网页,哪怕是需要登录、动态加载的内容也能轻松获取,还比传统工具节省82%的token消耗。你只需扔给它一个URL,它就会自动提取文本存进raw文件夹,彻底解放了复制粘贴的双手。
但这一切的前提,是给AI一份清晰的规则说明书。这份用Markdown写的文件,会告诉AI如何命名页面、怎么添加交叉链接、哪些内容需要重点标注——相当于给图书管理员定下了馆内守则。AI会严格按照规则整理内容,甚至能像代码检查工具一样,定期扫描知识库中的逻辑矛盾、信息遗漏,自动提出修正建议。
不过,这套系统也并非完美无缺。AI生成的内容可能存在“幻觉”,如果错误未被及时发现,会随着知识库的更新不断放大,形成“错误复利”。有从业者就建议,要将AI生成内容与人工整理的核心知识分开存储,定期进行人工审核,避免错误知识污染整个体系。
更值得关注的是,这种模式正在重构人与知识的关系。你不再是信息的搬运工,而是知识的策展人——负责筛选值得存入的内容,提出需要解答的问题,AI则承担了整理、链接、更新的机械性工作。当知识库积累到一定规模,甚至可以用它生成的内容微调专属小型语言模型,让AI真正“内化”你的知识体系。
未来的个人知识库,或许会成为每个人的“第二大脑”。它能跨文本、图像、音频等多模态整合信息,能在你研究某个课题时主动推送关联资料,甚至能模拟你的思考逻辑给出建议。而这一切的起点,可能只是三个简单的文件夹,和一份写给AI的说明书。