对抗知识焦虑,从看懂这条开始
App 下载
AI视频理解分差近半,新评测戳破分数泡沫
短视频内容推荐|AI模型分数泡沫|视频理解评测体系|Google Gemini评测团队|南京大学傅朝友团队|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载短视频内容推荐|AI模型分数泡沫|视频理解评测体系|Google Gemini评测团队|南京大学傅朝友团队|多模态视觉|人工智能
打开短视频APP,AI能精准识别你爱看的美食教程;刷到科普视频,它能秒懂知识点给你推同类内容——你可能以为,AI已经能像人一样“看懂”视频了。但南京大学傅朝友团队和Google Gemini评测团队联手,用一套新评测体系戳破了这个幻觉:当前最强的商用AI模型,在视频理解上的真实得分只有49.4,而人类专家能拿到90.7。更扎心的是,那些让我们以为AI在进步的高分,很大程度上是“蒙对的”。为什么会有这么大的差距?这套新评测到底发现了什么?
你可以把视频理解看成一场三层闯关游戏——过去的评测只看最后有没有通关,不管你是靠真本事还是蒙混过关,而这套叫Video-MME-v2的新体系,要一层一层检查你到底会不会。
第一层是“信息检索与聚合”,相当于让AI从一堆散落的拼图里,准确找出指定的几块。比如看一段做饭视频,它得能认出锅里的是番茄,旁边放的是盐,而不是把酱油当成醋。这是最基础的“看得到”。
第二层是“时序理解”,考验的是AI能不能看懂“先后顺序”。还是做饭视频,它得知道是先切番茄再下锅,而不是先炒番茄再去切。很多AI在这一关就露馅了——把视频帧打乱顺序,它照样能答对问题,说明它根本没理解时间的流动。
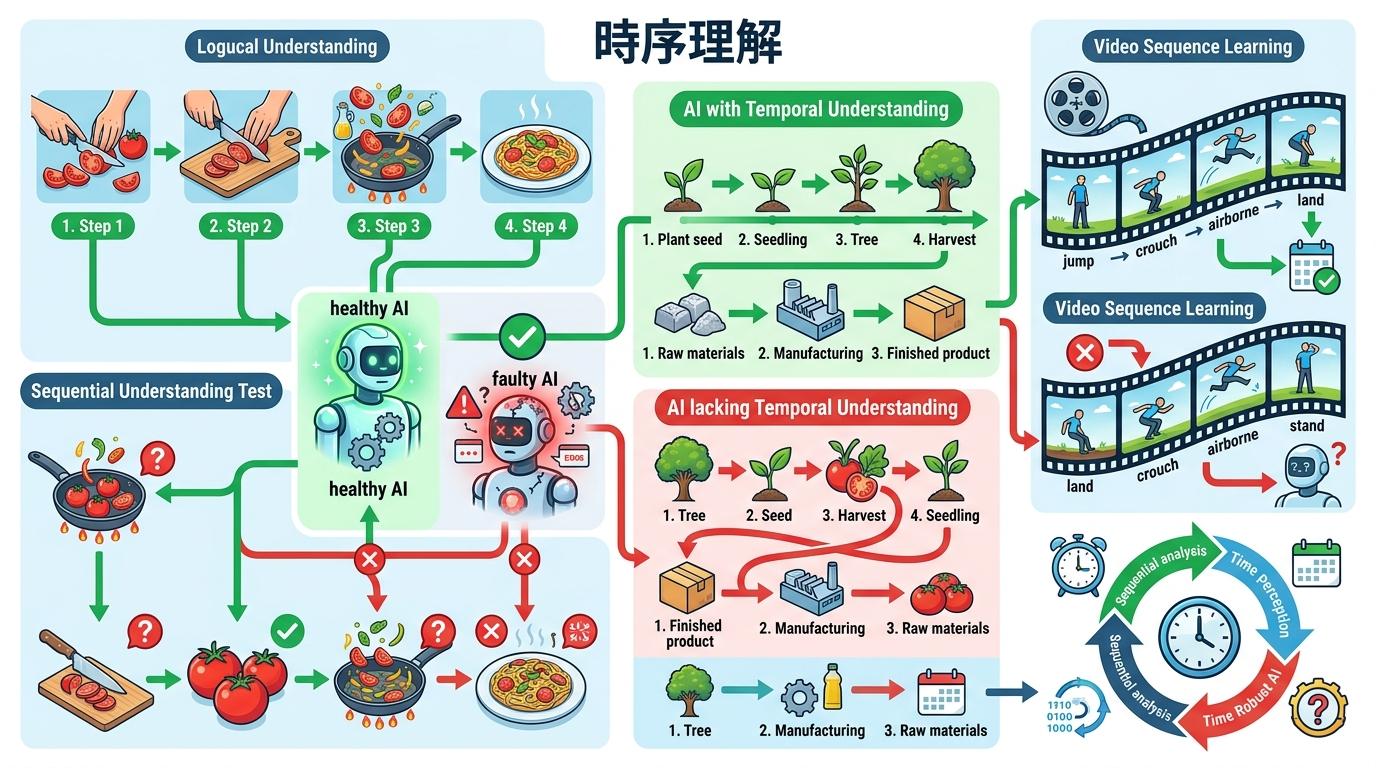
第三层是“复杂推理”,这才是真正的“看懂”。比如看完一段职场视频,它得能推断出员工为什么突然辞职,而不是只会说“他收拾东西走了”。这需要AI把看到的画面、动作、对话串起来,像人一样逻辑推理。
这套分层体系的厉害之处在于,它能精准定位AI的短板:很多AI在第一层能拿高分,到第二层就掉链子,第三层更是一塌糊涂——就像一个只会背单词的人,根本看不懂英语文章。
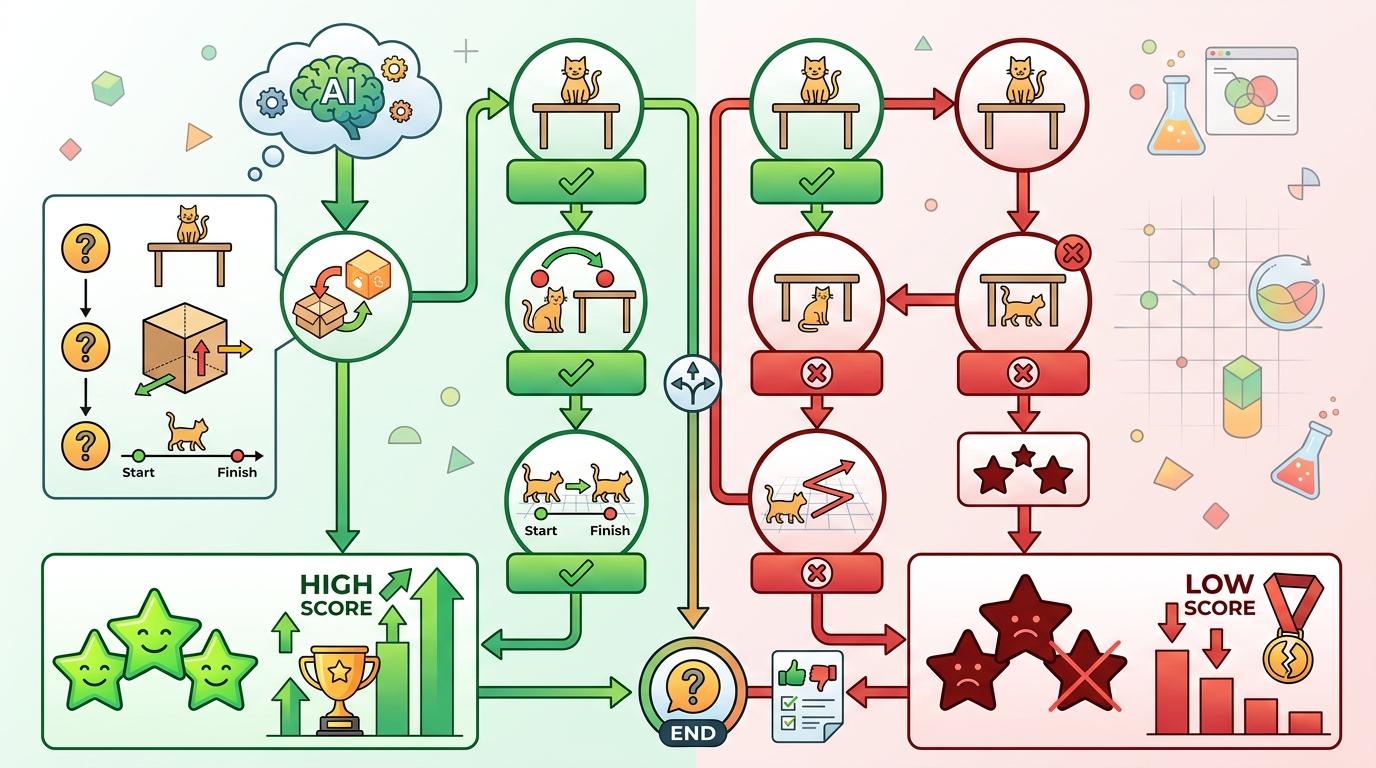
过去评测AI视频理解,就像考试里只看选择题的总分,不管你是真会还是蒙对。而Video-MME-v2用了一种“组级非线性评分”,相当于把相关的几道题捆在一起判分——要对就全对,错一个就前功尽弃。
比如测试AI的空间理解能力,会出一组题:“猫在哪里?”“猫和桌子的相对位置是什么?”“猫后来移动到了哪里?”如果AI真的理解了空间关系,这三道题应该全答对;但如果它只是蒙对了第一题,后面两道答错,那这一组的得分就会很低。
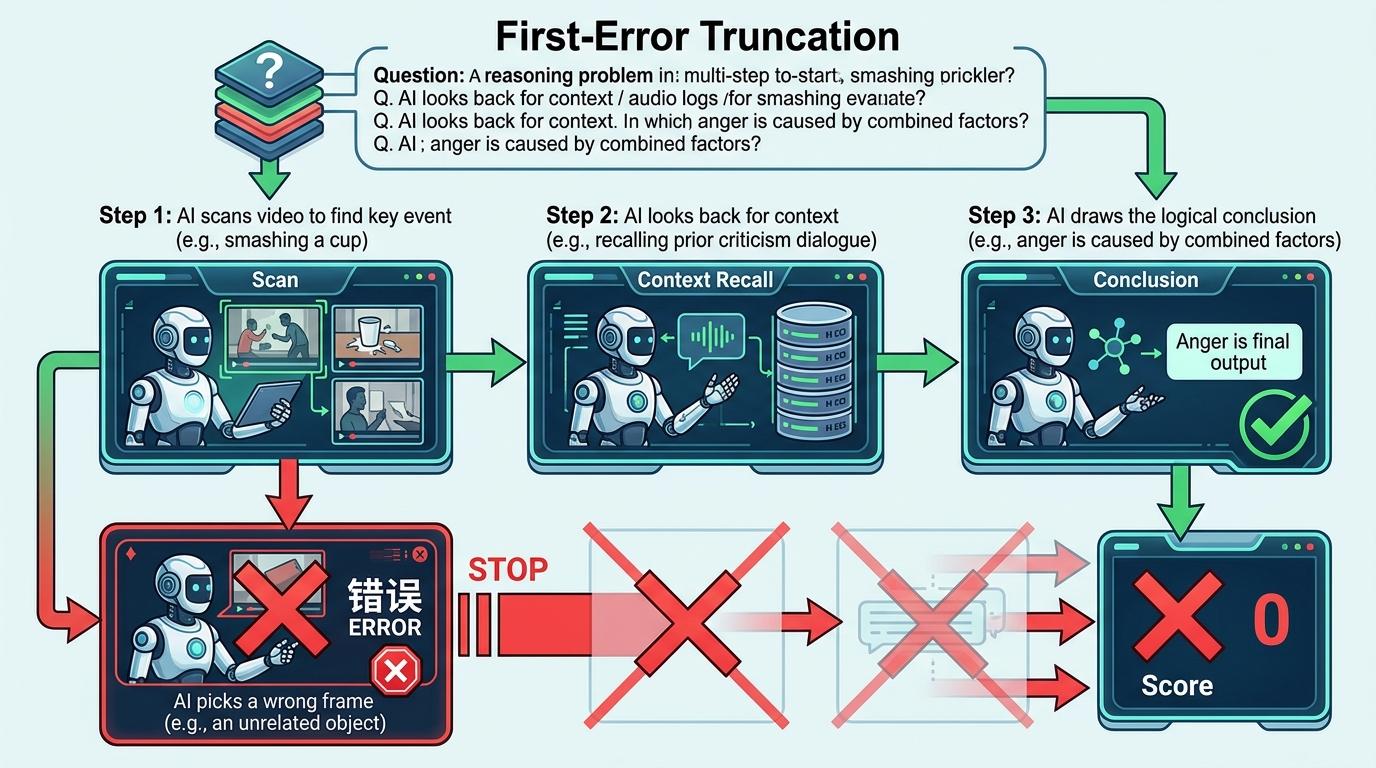
针对需要多步推理的问题,评测还用上了“首错截断”——比如要推断一个人为什么生气,得先找到他摔杯子的画面,再回忆之前老板批评他的对话,最后得出结论。如果AI第一步就找错了画面,哪怕最后碰巧猜对了原因,也不算分。
这种打分方式一下就戳破了AI的“高分泡沫”:过去用单题准确率,很多AI能拿到60分以上,但用组级非线性评分,最高的商用模型也只有49.4分。更能说明问题的是,AI的组级得分和单题得分的比值只有75%左右,而人类能达到95%——这意味着AI的“懂”是零散的、不稳定的,而人类的“懂”是连贯的、稳定的。
现在的AI都流行加个“思考模式”,让它像人一样一步步推理。但这次评测发现,这个“思考”其实是个“偏科生”——它严重依赖文本线索,没了字幕就寸步难行。
比如给AI看一段带字幕的视频,开启思考模式后,得分能提升5.8分;但如果把字幕去掉,同样开启思考模式,得分反而会下降0.6分。这说明AI的“思考”并不是真的在分析画面,而是在抠字幕里的关键词——就像学生做阅读理解,只看题干里的提示词,根本没读文章。
更有意思的是,不是所有AI都适合开思考模式。有些小模型开了思考模式后,得分反而更低,因为它会把简单的问题复杂化,越想越错。这就像一个学习不好的学生,硬要模仿学霸的解题步骤,结果画蛇添足。
这背后暴露的是AI的核心短板:它还不会从视频的画面、声音里提取推理的线索,只能靠文本当“拐杖”。真正的视频理解,应该是像人一样,哪怕没有字幕,也能通过画面里的表情、动作、场景,推断出发生了什么。
当我们为AI的每一个“小进步”欢呼时,这套新评测体系给我们浇了一盆冷水——它让我们看到,AI的“理解”和人类的“理解”,还差着一条巨大的鸿沟。过去我们追求的“高分”,更像是AI在评测体系里练出的“应试技巧”,而不是真正的智能。
真正的理解,是连贯且稳定的。 未来的AI视频理解,不应该再追求“蒙对多少题”,而应该像人一样,从看到画面的那一刻起,就开始构建一个连贯的、有逻辑的世界模型。只有这样,AI才能真正看懂视频,而不是只会在评测里“考高分”。毕竟,我们需要的不是一个会做题的AI,而是一个能和我们一起看懂生活的伙伴。