对抗知识焦虑,从看懂这条开始
App 下载
大模型乱码真相:不是降智,是缓存打架
系统故障|缓存竞态|高并发请求|AI代码助手|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载系统故障|缓存竞态|高并发请求|AI代码助手|大语言模型|人工智能
当你用AI代码助手敲下一行指令,它却吐出乱码、反复复读同一个单词,甚至蹦出莫名其妙的生僻字——你大概率会以为是AI“脑子卡壳”了。但今年3月,当每日数亿次请求压向国内某大模型时,工程师们发现了反直觉的真相:这些异常和模型本身无关,只在高并发的极端压力下才会露头,本地测试根本复现不出来。每万次请求里就有十几次出错,换算成每日数亿次调用,意味着数万用户正遭遇诡异的AI输出。更棘手的是,这不是模型“降智”,而是底层系统的隐秘故障在作祟。
你可以把大模型的推理过程想象成一场高速列车运行:每生成一个新Token,都需要从“缓存车厢”里调取上下文数据。而竞态Bug,就是两列列车同时抢着往同一个车厢里塞东西,或者还没等货物卸完就强行开门取货。
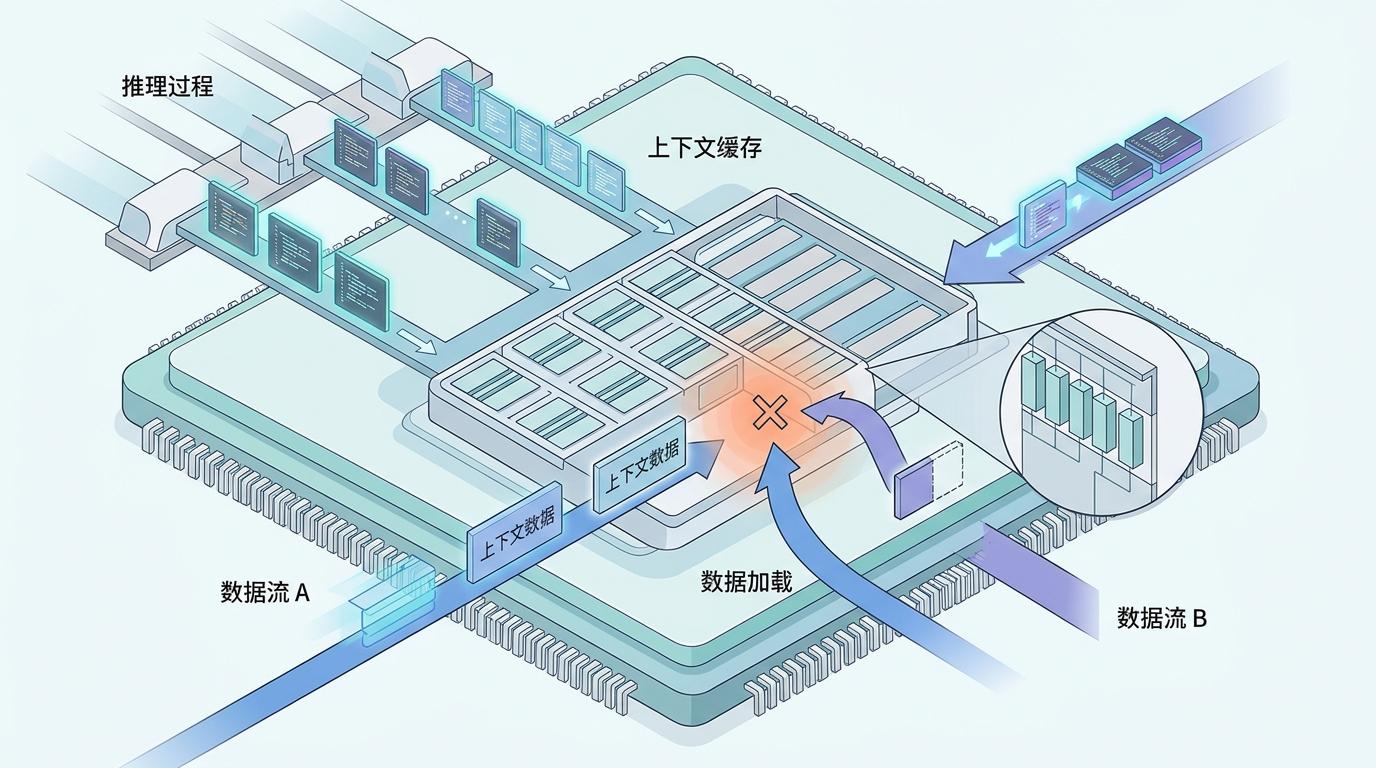
第一个Bug出现在PD分离架构的异步Abort机制里。当一个请求被中途终止,本该停止的缓存写入操作却还在后台偷偷运行,新请求已经占用了同一块显存空间——相当于前一趟列车的行李还没搬完,后一趟的行李就硬塞了进来,结果就是缓存数据彻底混乱。
第二个Bug则是HiCache加载流水线的“抢跑”。缓存数据还在从硬盘往显存里搬运,计算模块就已经开始读取,相当于厨师还没把菜端上桌,服务员就把空盘子端给了顾客。这种“数据未就绪即读取”的情况,直接导致模型拿到的是残缺的上下文。
这两个问题都藏在极端并发的缝隙里:本地测试时请求量小,列车运行井然有序;只有当每日数亿次请求像潮水般涌来,才会出现“抢道事故”。工程师们最终通过给缓存回收加时序锁、给数据加载加同步标记,把异常率从万分之十几压到了万分之三以下。
解决了故障问题,工程师们还要面对另一个更根本的瓶颈:缓存的显存压力。你可以把单GPU的显存想象成一节只能装下整列火车行李的车厢,当上下文长度达到10万Token时,这节车厢会被直接撑爆,导致系统吞吐暴跌。
传统的解决方案是让每张GPU都存下完整的缓存数据,这就像每节车厢都要装下整列火车的行李,严重浪费空间。而LayerSplit的思路,是把缓存按模型层拆分成小块,每张GPU只存其中一部分——相当于把行李按目的地拆分,每节车厢只装对应路段的行李,计算时再通过高速网络把需要的缓存块“广播”给所有GPU。
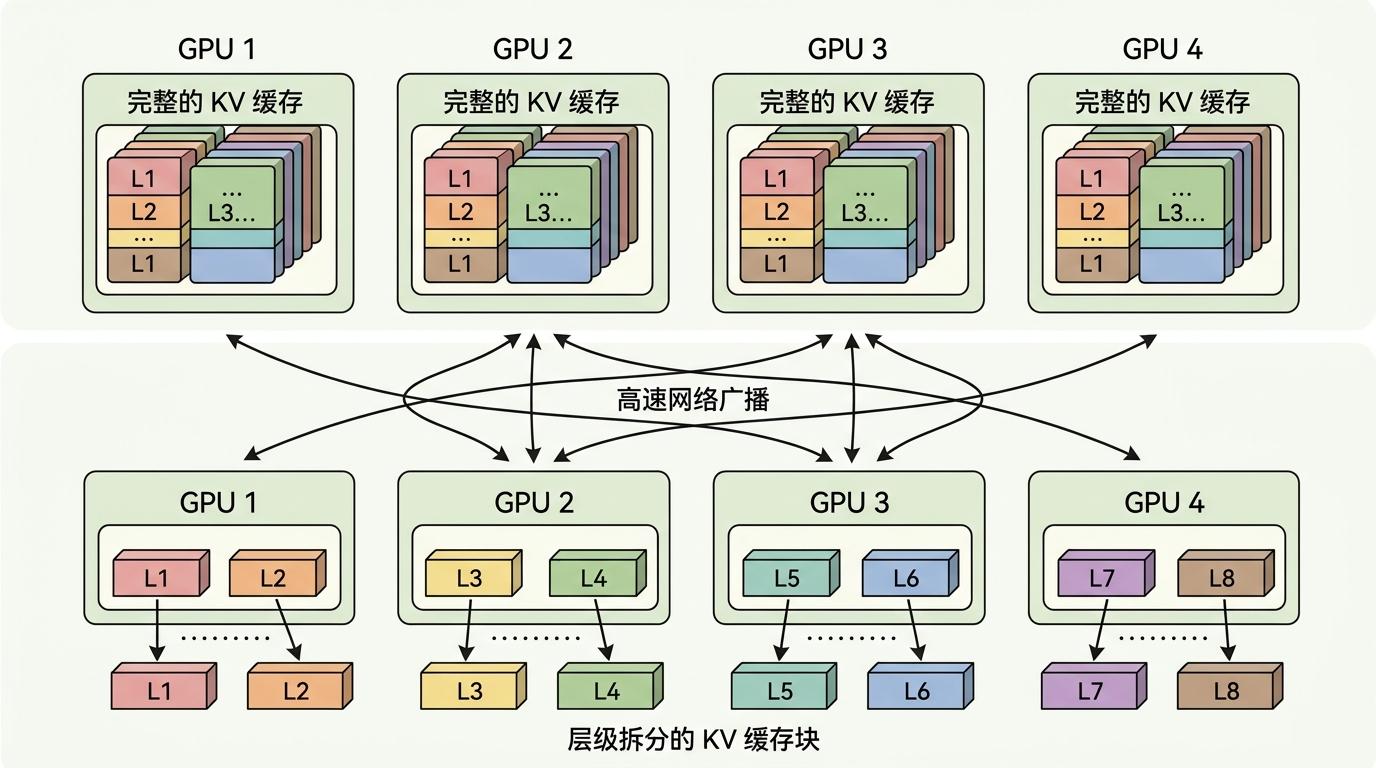
为了不让广播拖慢速度,工程师们还设计了“计算与通信重叠”的机制:当GPU在计算当前层数据时,同时在后台接收下一层的缓存块,让等待时间被彻底“掩盖”。实测显示,在上下文长度4万到12万Token的场景下,系统吞吐提升了10%到132%,上下文越长,节省的显存空间越多,提升效果越明显。
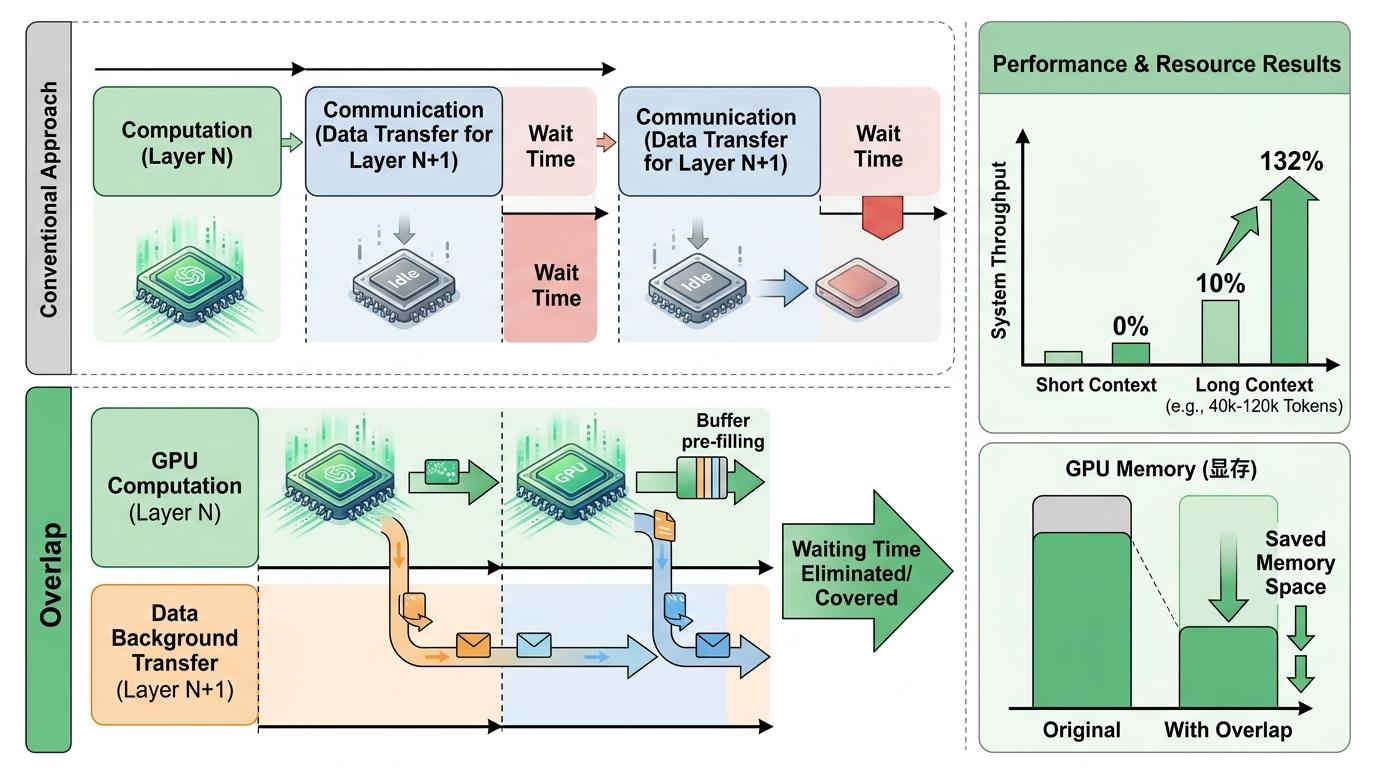
更关键的是,这个方案没有牺牲模型精度——它只是让缓存的利用效率变得更聪明了。
在排查故障的过程中,工程师们还意外发现了一个“副产品”:把原本用来提升推理速度的投机采样,变成了检测缓存故障的“照妖镜”。
投机采样本来是个性能优化技巧:用一个轻量的“草稿模型”先快速生成候选Token,再让主模型校验是否采纳,以此提升解码效率。而当缓存出现故障时,这个机制的两个指标会出现异常:如果缓存数据混乱,草稿模型生成的Token会几乎全被拒绝,spec_accept_length指标会暴跌;如果缓存导致模型陷入复读循环,草稿模型的Token会被大量采纳,spec_accept_rate指标会飙升。
工程师们把这两个指标变成了实时监控信号,相当于给系统装了个“故障预警灯”——不用等用户反馈异常,系统自己就能提前发现缓存的隐秘问题。这也让人们意识到:大模型的性能指标和质量指标,其实是紧密关联的。
当我们谈论大模型的能力时,目光总是聚焦在模型参数、训练数据这些“看得见”的部分,却常常忽略底层系统的“隐形地基”。这次的故障排查就像一场外科手术:看似是AI“脑子出问题”,实则是“神经通路”里的信号冲突。
大模型的时代,早已不是单靠堆参数就能赢的时代。真正的竞争力,藏在每一次缓存写入的时序里,藏在每一块显存的利用率里,藏在那些用户看不见的底层细节里。
地基稳了,AI才能走得更远。