对抗知识焦虑,从看懂这条开始
App 下载
机器人不用练动作,看视频就会干活
透明物体操作|视频学习|物理直觉|机器人抓取|中山大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载透明物体操作|视频学习|物理直觉|机器人抓取|中山大学|多模态视觉|人工智能
想象一下:给机器人看100万条人类拿杯子、推箱子的视频,它不用被手把手教动作,就能直接抓起桌上的透明玻璃杯,还能精准把方块堆到指定位置。这不是科幻——中山大学的研究团队让机器人做到了:在没有任何专属动作训练数据的前提下,它推方块的成功率达到100%,抓取透明物体的表现甚至超过了靠百万条动作数据喂出来的传统模型。这背后的秘密,是机器人从视频里「偷」到了人类天生就有的东西:物理直觉。它到底是怎么做到的?
过去教机器人干活,就像把人拆成两半:先训练它「看」——识别环境里的物体;再训练它「做」——记住一套套动作指令。就像你先死记硬背菜谱里的步骤,却完全不知道「倒半杯水」会有什么结果,更别说根据杯子的形状调整手势了。
PAR模型彻底推翻了这套逻辑。它把机器人看到的每帧画面和要做的每个动作,都编码成同一种「物理token」——你可以把它理解成机器人眼里的「动作-画面配对卡」。模型不再分开处理「看」和「做」,而是像人一样,边看边想:「我现在推一下,这个方块会滑到哪里?」然后直接输出对应的动作。
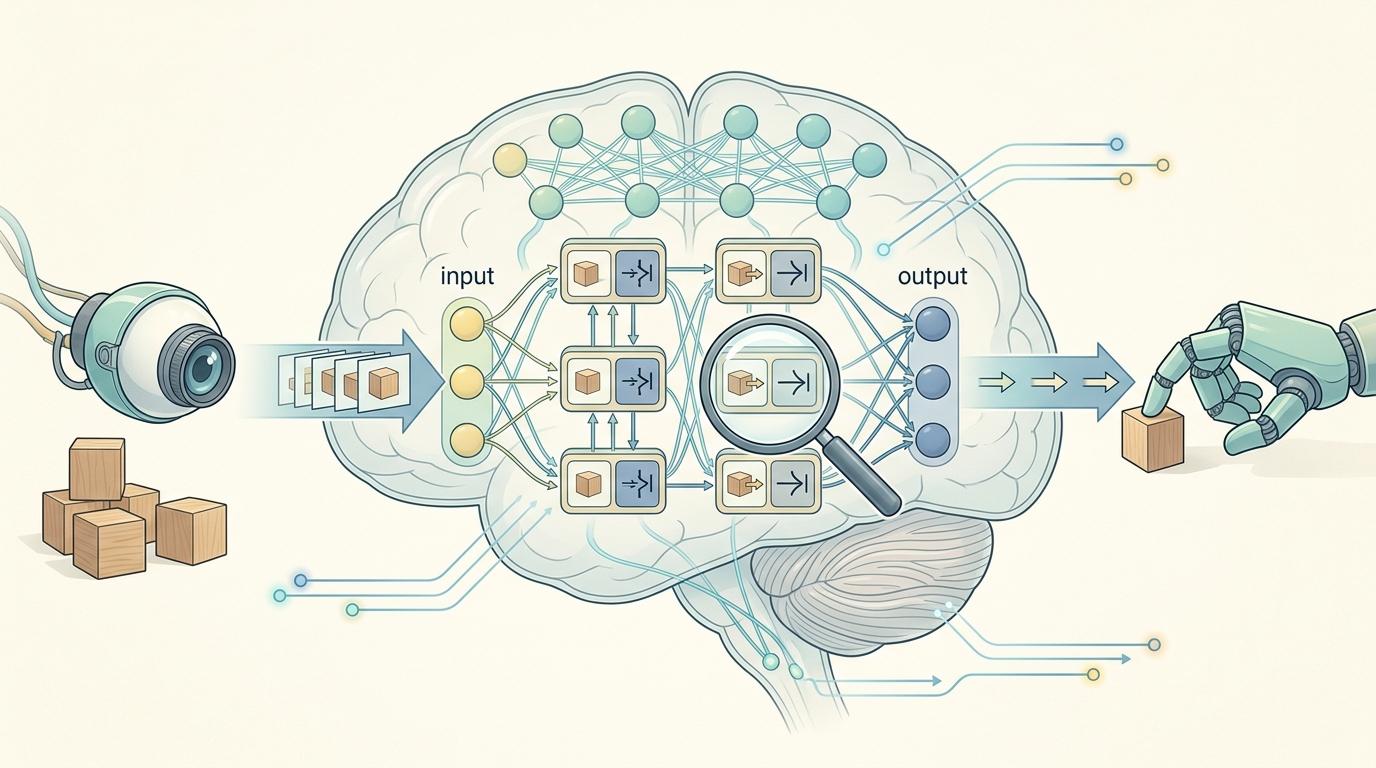
关键的设计藏在因果掩码里:模型能「提前看到」自己动作会导致的画面,再反过来调整当下的动作——这就像你伸手去拿杯子时,眼睛已经预判了手的位置,大脑自动调整手指的弯曲程度。没有离散化的误差,没有割裂的感知和决策,机器人的动作第一次和环境的物理变化紧紧绑在了一起。
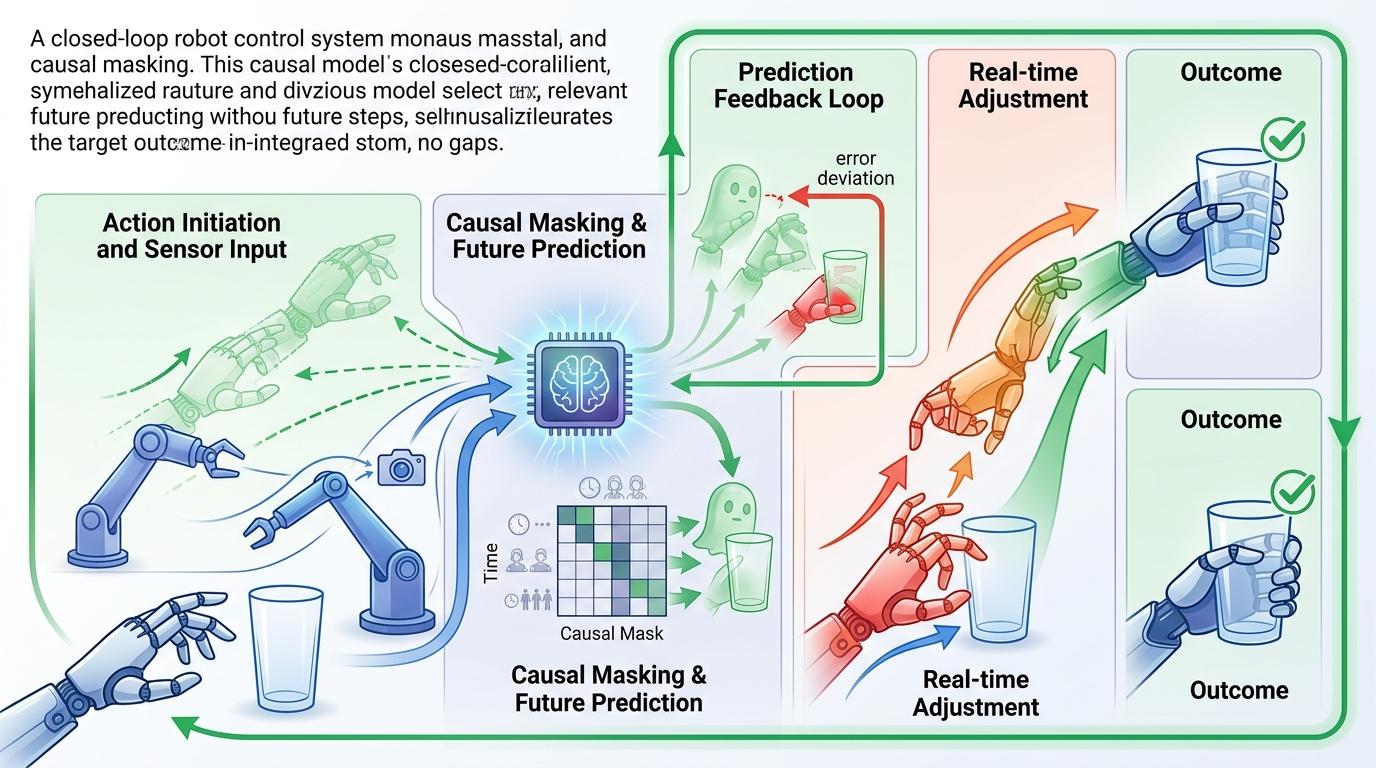
你刷短视频时,其实也在无意识地学物理:看到杯子被碰倒会洒出水,看到球滚下斜坡会加速。这些藏在视频里的物理规律,就是机器人最需要的「直觉」。
PhysGen模型把这个思路推到了极致。它直接从预训练好的视频生成模型里「借」物理知识——那些模型已经看过了几百万小时的人类视频,早就学会了「力会传递」「物体有重量」这些底层逻辑。研究团队只需要做一件事:用LoRA微调技术,给这个大模型装一个「机器人动作接口」,让它把视频里的人类动作,转换成机械臂能执行的指令。
单张A100显卡,60小时就能完成训练。在真实的Franka Panda机械臂上,它能精准抓起透明玻璃杯——这种连人类都要仔细瞄准的任务,它的成功率超过了靠海量动作数据训练的传统模型。不是它比传统模型更聪明,而是它没在重复死记硬背的老路,而是直接站在了人类视频数据的肩膀上。
这不是视频生成模型第一次跨界,但却是它第一次找准了自己在机器人领域的位置。
过去的视频生成模型,比如Sora,追求的是「看起来真实」——生成的视频要流畅、美观,哪怕里面的物理规律偶尔出错也没关系。但对机器人来说,视频好不好看根本不重要,重要的是「做这个动作,会不会真的把杯子抓起来」。
PhysGen和同期英伟达发布的DreamDojo,都踩中了同一个核心:世界模型的价值,从来不是生成视觉逼真的画面,而是生成「对动作有指导意义的物理预测」。PhysGen只用732M参数,就打败了7B级的传统模型——不是因为它参数更多,而是它把所有算力都用在了「预测物理结果」上,没有浪费在让视频更精美上。
当然,这条路还没走到头。它还不会处理长时序的复杂任务,也缺少触觉感知——比如抓鸡蛋时,它不知道该用多大的力。但最关键的窗户纸已经被捅破了:机器人不需要从零开始学物理,人类已经把答案拍进了视频里。
我们花了几十年,想让机器人像人一样干活,却一直卡在「数据匮乏」的死胡同里——要让机器人学会一个动作,就得有人反复示范,录下数据,再喂给模型。但人类的学习方式从来不是这样:我们看别人做一遍,就知道该怎么模仿,因为我们天生懂物理。
现在,机器人终于跟上了人类的思路。它不需要被手把手教,只需要看——看人类怎么和世界互动,看物理规律怎么起作用,然后把这些直觉变成自己的动作。
视频里的物理,是机器人的新老师。
未来的机器人,或许会像我们刷短视频一样,在互联网的视频海洋里自学成才。而我们要做的,或许只是给它指个方向:「看,人类是这么干活的。」