
19 小时前
19 小时前
你珍藏了10年的旅行视频,因为硬盘老化满是马赛克和色块。打开修复软件,却被要求用画笔一帧一帧圈出损坏区域——10分钟的视频有18000帧,光是圈完就得花掉3天。这不是虚构的场景,是传统视频修复技术的真实门槛。直到2026年4月,昆士兰大学和CSIRO的团队彻底推翻了这个规则:他们让AI自己看懂视频里的「隐形线索」,不用人画一个圈,就能精准修复所有损坏。
你可以把视频压缩的过程想象成打包行李:为了省空间,不会把每件衣服都单独装箱,而是先把同款叠在一起(帧间运动),再标记好每件衣服的位置(运动向量),最后贴上箱子标签(帧类型,I/P/B帧)。这些标记就是视频的「元数据」——它们不是画面本身,却是画面能被正确解码的关键。
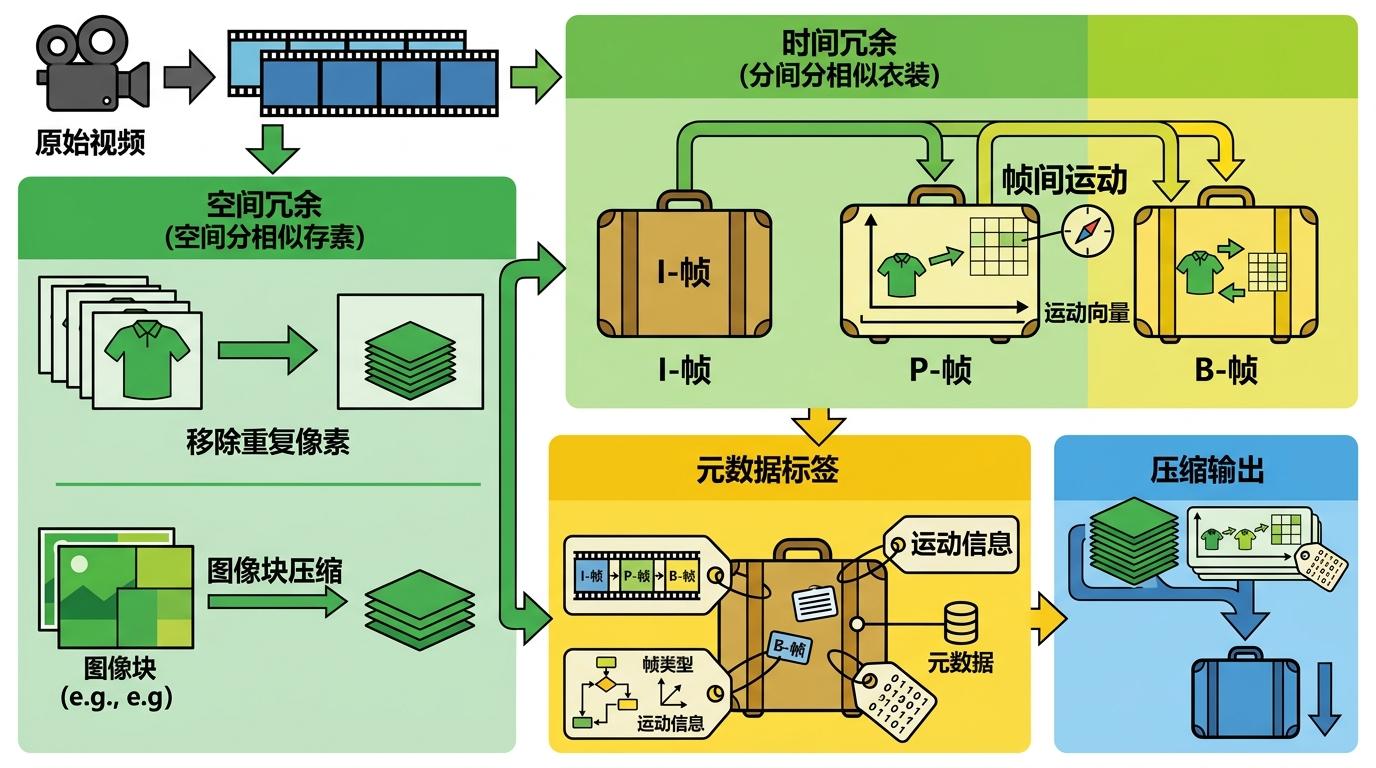
当视频文件损坏时,这些元数据会先出问题:运动向量乱了,对应画面就会出现块状错位;帧类型标记错了,整段画面都会色彩失真。就像行李标签被撕坏,你能通过混乱的打包痕迹,立刻判断哪箱行李出了问题。
过去没人把这些元数据当回事,修复视频时总在画面本身上下功夫。这次的研究团队反其道而行:直接把元数据当成AI的「诊断报告」,让它顺着元数据的异常,反向定位画面里的损坏区域。
光有线索还不够,得给AI配上「手术刀」。团队用扩散模型作为核心修复引擎——这是当前最擅长生成逼真画面的AI,但它有个致命缺点:会把整段视频都重新画一遍,连完好的部分也不放过。
于是他们搭了一套「三驾马车」架构:
第一驾:双流元数据编码器。把运动向量和帧类型这两种元数据,翻译成AI能看懂的语言,通过交叉注意力机制,在扩散模型的每一步去噪过程中提醒它:「重点看这里」。
第二驾:先验驱动掩码预测器。相当于AI自己画的「手术范围」,它结合元数据和扩散模型的注意力输出,自动生成损坏区域的伪掩码,把完好区域和待修复区域严格分开,避免AI「误伤」。
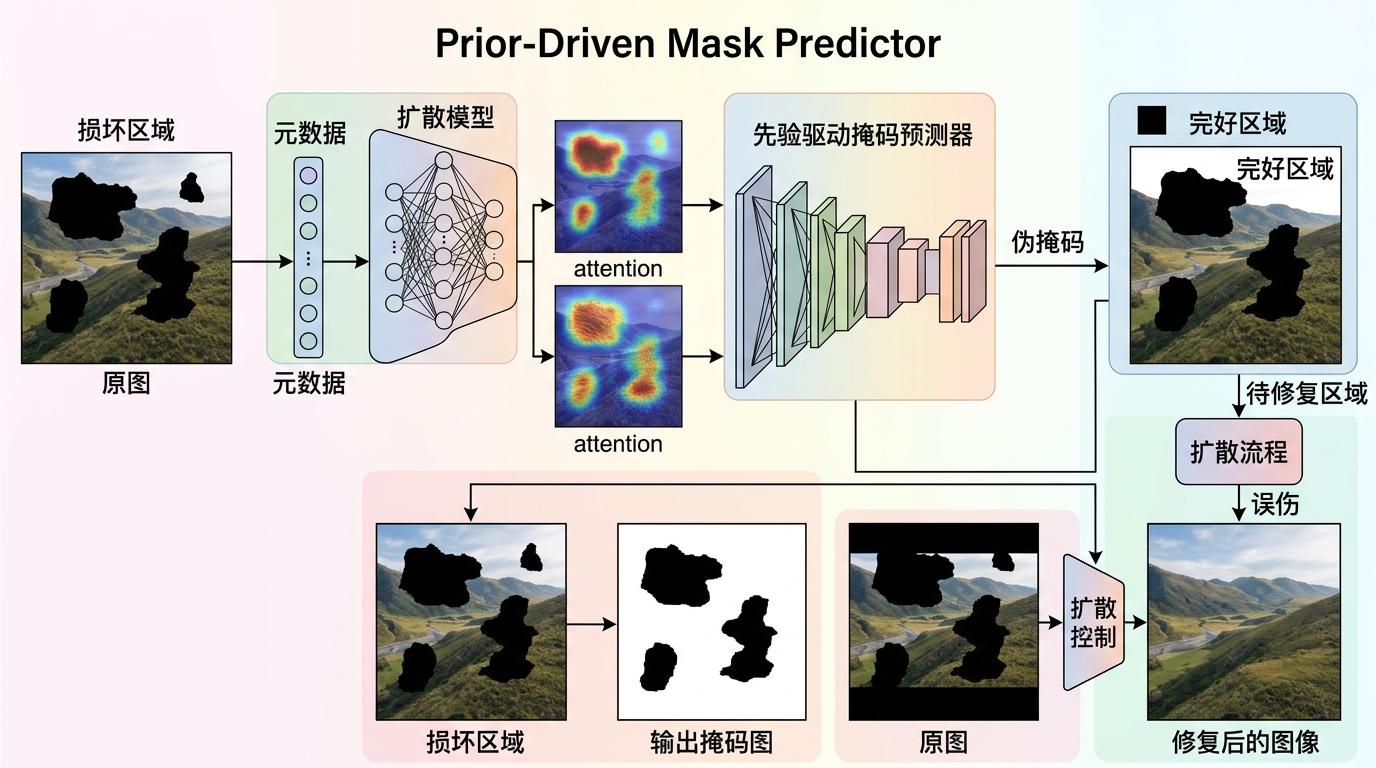
第三驾:后处理精修模块。就算是最精准的手术也会有缝合痕迹,这个模块用残差Swin Transformer块打磨边界,消除修复区和完好区之间的接缝,让画面完全自然融合。
在YouTube-VOS和DAVIS数据集上,这套方法的PSNR指标(衡量画面精度)比第二名高出1.55,修复的水波纹、动物毛发细节,甚至比原始损坏前的画面更连贯。
当然,这套方法也不是完美的。它目前只能处理H.264编码的视频,对AV1、VP9等新编码格式的元数据还不兼容;扩散模型的计算量很大,16张H20 GPU训练一次要花数周,推理速度慢,暂时只能用于离线修复,没法支持实时流媒体。
更关键的是,它的「诊断能力」依赖元数据的异常模式——如果视频是直接被物理损坏(比如胶片刮花)而不是比特流损坏,元数据没出问题,AI就会「失明」。
但这些局限反而指向了更有价值的方向:既然视频的元数据能当线索,那音频的编码参数、医学影像的扫描参数、工业传感器的环境参数,这些被当成「副产品」的元数据,会不会都是AI的「隐形说明书」?
我们总在抱怨AI需要太多标注数据,却常常忽略:很多数据已经「免费」存在于我们生产的内容里。就像视频压缩时自动生成的元数据,它们不是垃圾,是被藏起来的「解题思路」。
这次的视频修复技术,本质上是一次「价值重发现」——当我们不再只盯着画面本身,而是去看那些支撑画面的「隐形逻辑」,AI的能力边界就被拓宽了。
金句:别只看内容本身,要看内容的「生成逻辑」。
点击充电,成为大圆镜下一个视频选题!