对抗知识焦虑,从看懂这条开始
App 下载
AI科学家期末考:最高分仅33,鸿沟何在?
科学家工作流|上海人工智能实验室|Gemini-3-Pro|SGI-Bench|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载科学家工作流|上海人工智能实验室|Gemini-3-Pro|SGI-Bench|大语言模型|人工智能
如果将成为“通用科学家”视为一场终极考核,那么当前最顶尖的AI大模型,刚刚交出了一份令人震惊的成绩单。在这场由上海人工智能实验室设计的全方位、高难度“期末考试”中,即便是排名第一的“学霸”Gemini-3-Pro,其最终得分也仅为33.83分(满分100)。这一分数不仅远低于及格线,更残酷地揭示了一个事实:尽管AI在特定任务上高歌猛进,但距离成为能够独立、严谨地进行科学探索的“科学家”,仍存在一道深不见底的鸿沟。
这场特殊的考试名为SGI-Bench,它并非传统的单项选择或填空题,而是首个对齐真实科学家工作流的全流程评测基准。过去,我们习惯于用解题、编程或对话能力来衡量AI的“智力”,但这好比仅通过背诵公式来评判一个物理学家。科学研究是一个复杂的循环系统,充满了试错、迭代与跨领域的整合。
为此,SGI-Bench的“出题组”——一个由多学科专家和上百位硕博研究生组成的团队,将科学探究的核心过程解构为四个环环相扣的阶段,构成了一套严苛的“考纲”:
这四个维度共同定义了“科学通用智能”(SGI)。而33.83分的惨淡成绩,正是在这四个“主科”上全面溃败的结果。
在“审思”环节,AI大模型展现了其作为信息检索工具的强大一面。它能快速从海量文献中抓取相关信息,单步操作的准确率可达50%–65%。然而,科学研究的核心并非信息的堆砌,而是构建一条严谨的逻辑链,从证据推导出结论。
这恰恰是AI的“滑铁卢”。在模拟文献元分析这类长链路任务中,模型在推理过程中哪怕出现一个微小的错误,都会导致最终“结论崩塌”。最终,答案的严格匹配率骤降至10%–20%。这就像一个学生,虽然背下了所有历史年份和事件,却无法写出一篇逻辑自洽的史论。
进入“构思”环节,AI似乎变身为一个充满奇思妙想的“点子大王”。以GPT-5为例,其创意的“新颖性”得分高达76.08,远超其他能力。然而,科学的价值在于将灵感落地。在衡量方案是否可执行的“可行性”指标上,它的得分仅有18.87。
这种巨大的反差暴露了AI的致命缺陷:“概念丰富”不等于“可执行方案”。模型提出的计划往往漏洞百出:缺少关键的数据处理步骤、输入输出不匹配、流程依赖关系模糊。它们能描绘一幅宏伟的蓝图,却给不出具体的施工图纸,使得“创意→蓝图→执行”的闭环在源头就已断裂。
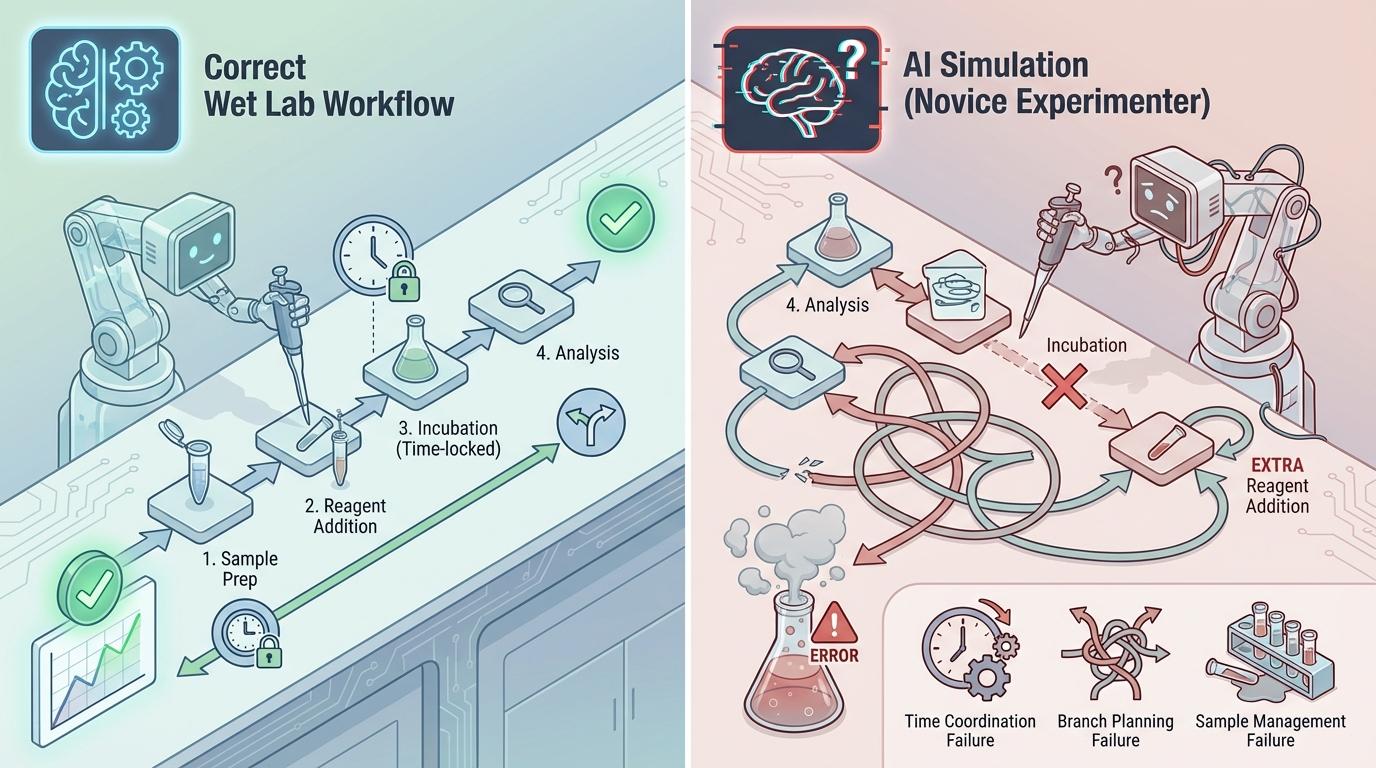
“行动”是检验真理的唯一标准,它被分为“干实验”(代码编程)和“湿实验”(实验流程规划)。
在科学代码生成测试中,AI再次陷入了“形似而神不似”的窘境。超过90%的模型生成的代码都能顺利运行、不报错,堪称“语法大师”。然而,代码能跑,不代表算得对。在涉及精密数值计算和科学仿真的任务中,即使是表现最好的Gemini-3-Pro,其代码完全通过所有测试用例的“严格通过率”也仅有36.64%。
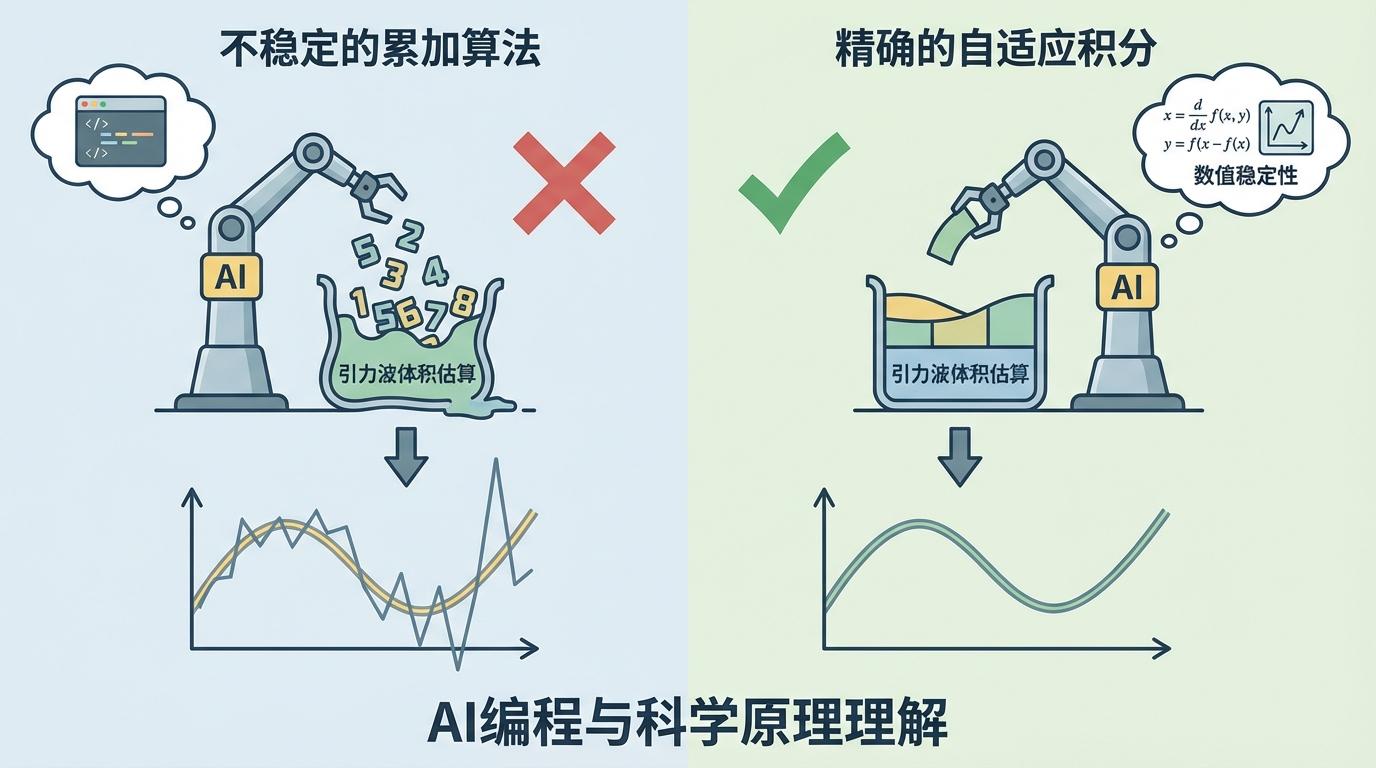
一个典型的例子是,在估算引力波体积时,模型可能会选择一个在数值上不稳定的累加算法,而非更精确的自适应积分,导致最终结果严重偏离真实值。这揭示了AI在编程时,仍停留在语法层面,缺乏对背后科学原理和数值稳定性的深刻理解。
而在模拟“湿实验”流程规划时,AI的表现更像一个新手实验员。它们会频繁地遗漏关键步骤、插入多余操作,或完全打乱正确的实验顺序。在复杂的生物实验中,这种错误是致命的,反映出模型在处理时间协调、分支规划和样本管理上的严重不足。
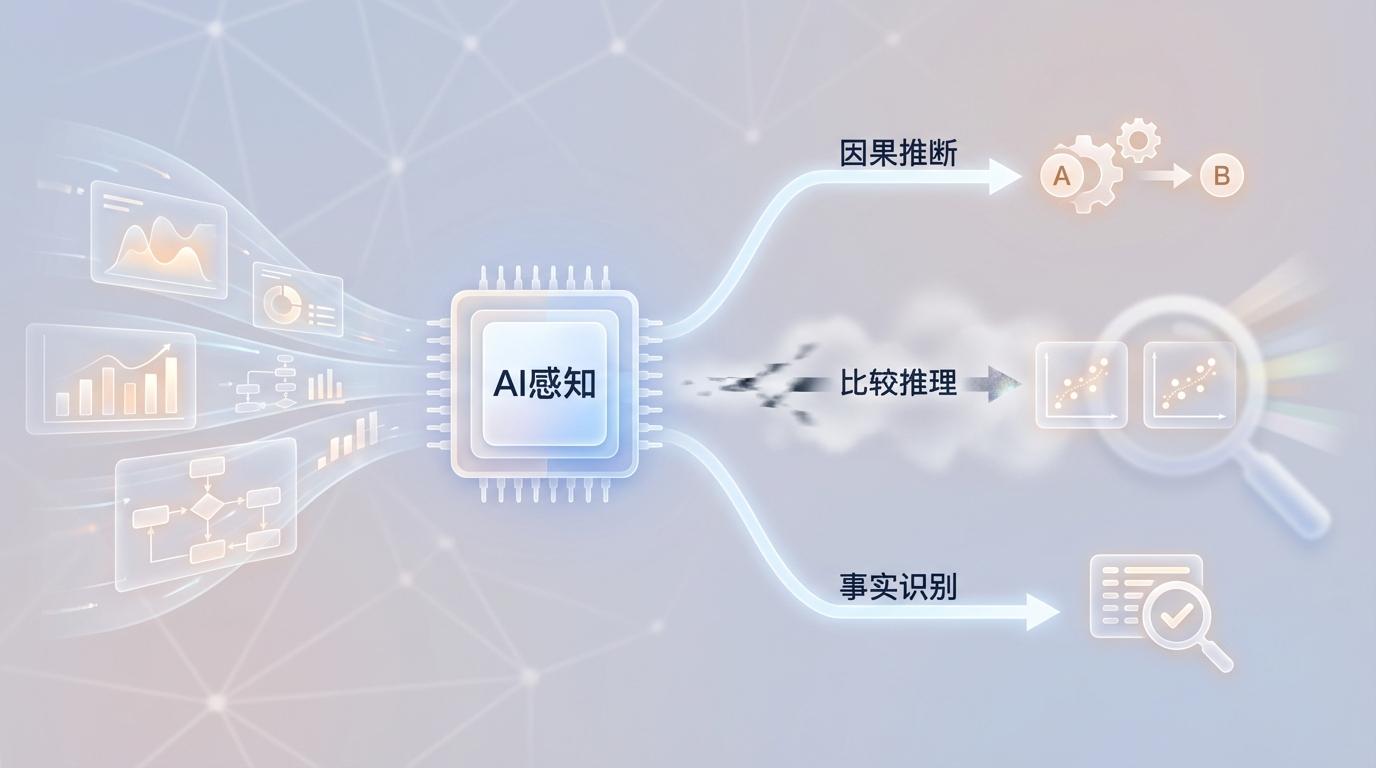
在最后的“感知”环节,AI需要解读图表、流程图等多模态信息,并做出判断。结果显示,模型进行因果推断和事实识别的能力尚可,但在“比较推理”上表现最弱。当被要求对比不同样本间的细微差异时,AI往往会失焦。
多数模型的“推理有效性”(过程看起来合理)得分高于“答案准确率”(结论正确),这意味着它们常常能编织一个看似头头是道的推理故事,但这个故事的结局却是错的。这再次证明,AI的“推理”更多是基于概率的文本生成,而非真正建立在逻辑和事实基础上的严谨分析。
SGI-Bench这份“成绩单”并非为了唱衰AI for Science,恰恰相反,它提供了一张极为宝贵的“路线图”。它清晰地标示出当前AI能力的系统性短板,为未来的技术突破指明了方向:
AI大模型距离成为真正的“科学家”依然道阻且长。科学的本质,不仅是对海量知识的记忆和关联,更是一种建立在批判、创造和严谨验证之上的思维范式。这场33分的“期末考”是一个冷静的提醒:在为AI的每一次进步欢呼时,我们更应清醒地认识到,通往通用科学智能的征途,才刚刚开始。