对抗知识焦虑,从看懂这条开始
App 下载
多模态AI能看懂世界,但还没学会精准思考
信息融合|模型测试|感知能力|多模态AI|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载信息融合|模型测试|感知能力|多模态AI|多模态视觉|人工智能
凌晨的实验室里,屏幕上的AI刚准确指出了图片里奔跑的人,转头就把钟表的时间认错,还对着一块冰块答不出它的情绪。它能解开复杂的六面体展开题,却走不出简单的迷宫;能听懂7小时长音频的逻辑,却搞不定一张成语图。这不是某个半成品模型的测试记录,而是当前多模态AI最真实的能力写照——它能同时接收文本、图像、音频、视频信号,像人类一样“感知”世界,却在最基础的精准思考上频频掉链。
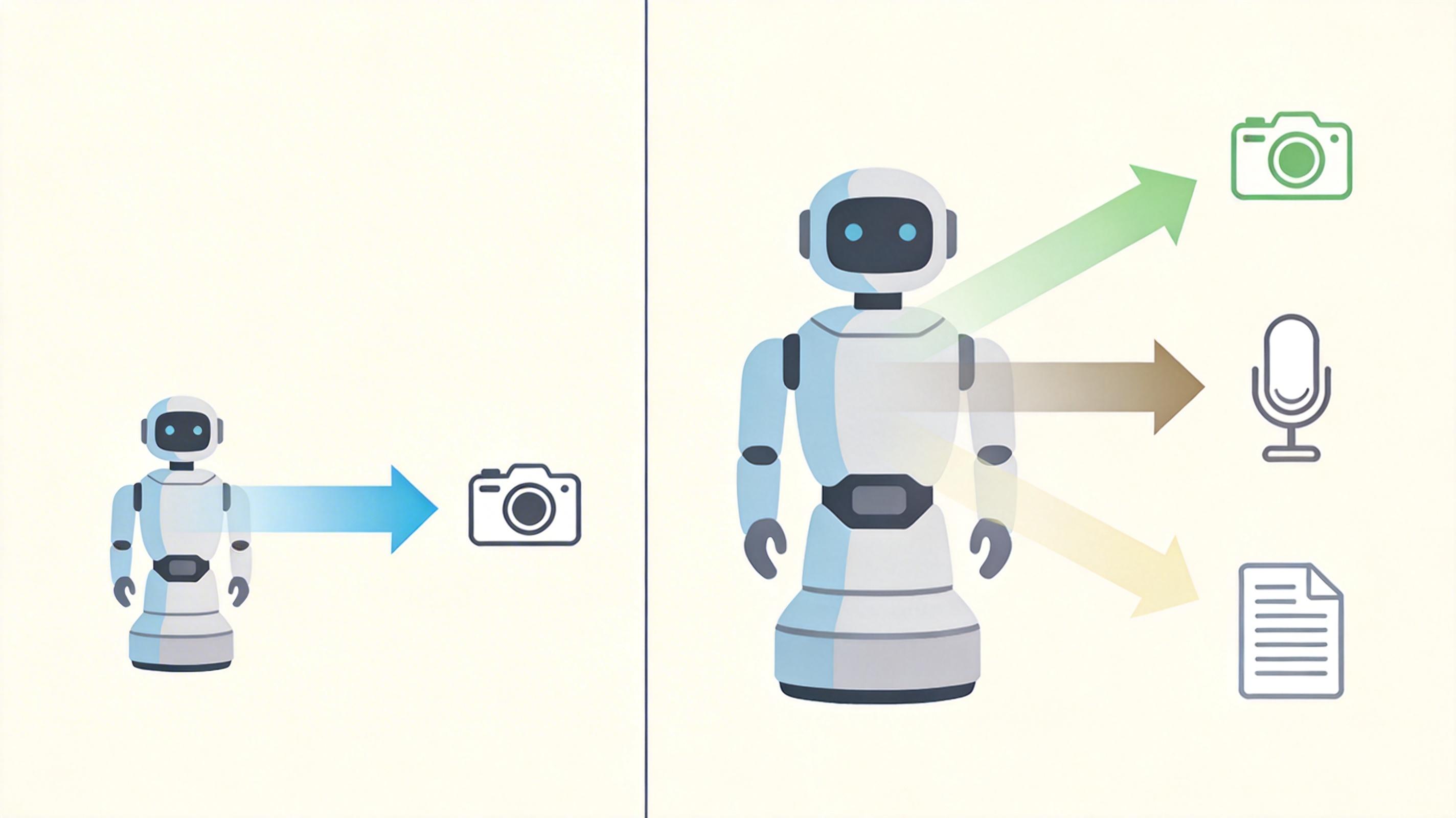
你可以把单模态AI想象成只会用眼睛看世界的人,或者只能靠耳朵听的人——它能把一件事做到极致,但换个信息形式就抓瞎。而多模态AI,是终于学会用眼睛看、耳朵听、嘴巴读的“全感官”学习者。
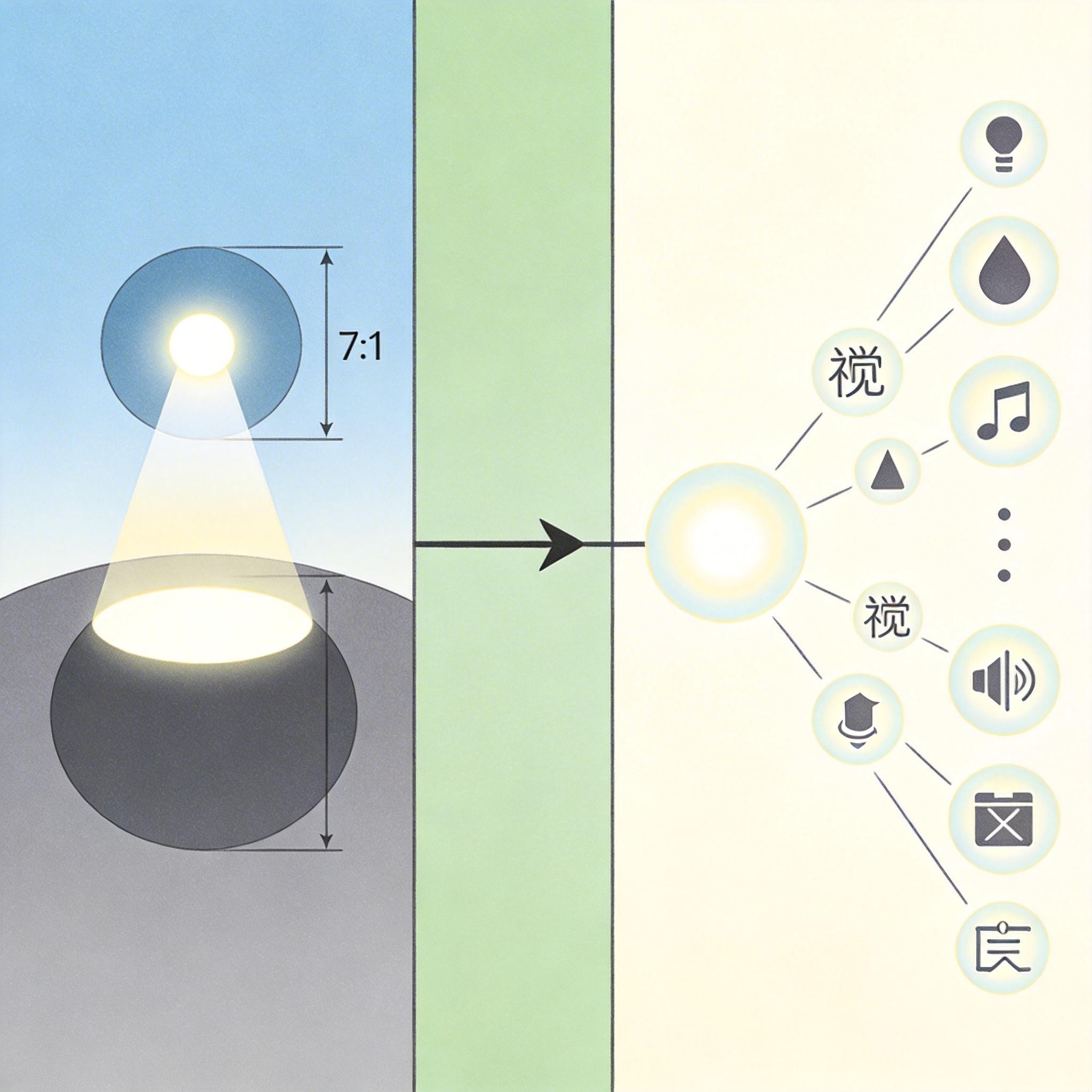
它的核心秘密藏在两个关键技术里:一个是**混合注意力机制——就像你看书时,会重点盯着关键词,同时用余光扫过上下文,模型把局部细节注意力和全局整体注意力的比例从5:1调到7:1,既能抓住重点,又不会漏掉全局;另一个是统一多模态骨干网络**,把图像、声音、文字都转换成同一种“通用语言”,让模型能在不同信息间自由翻译。
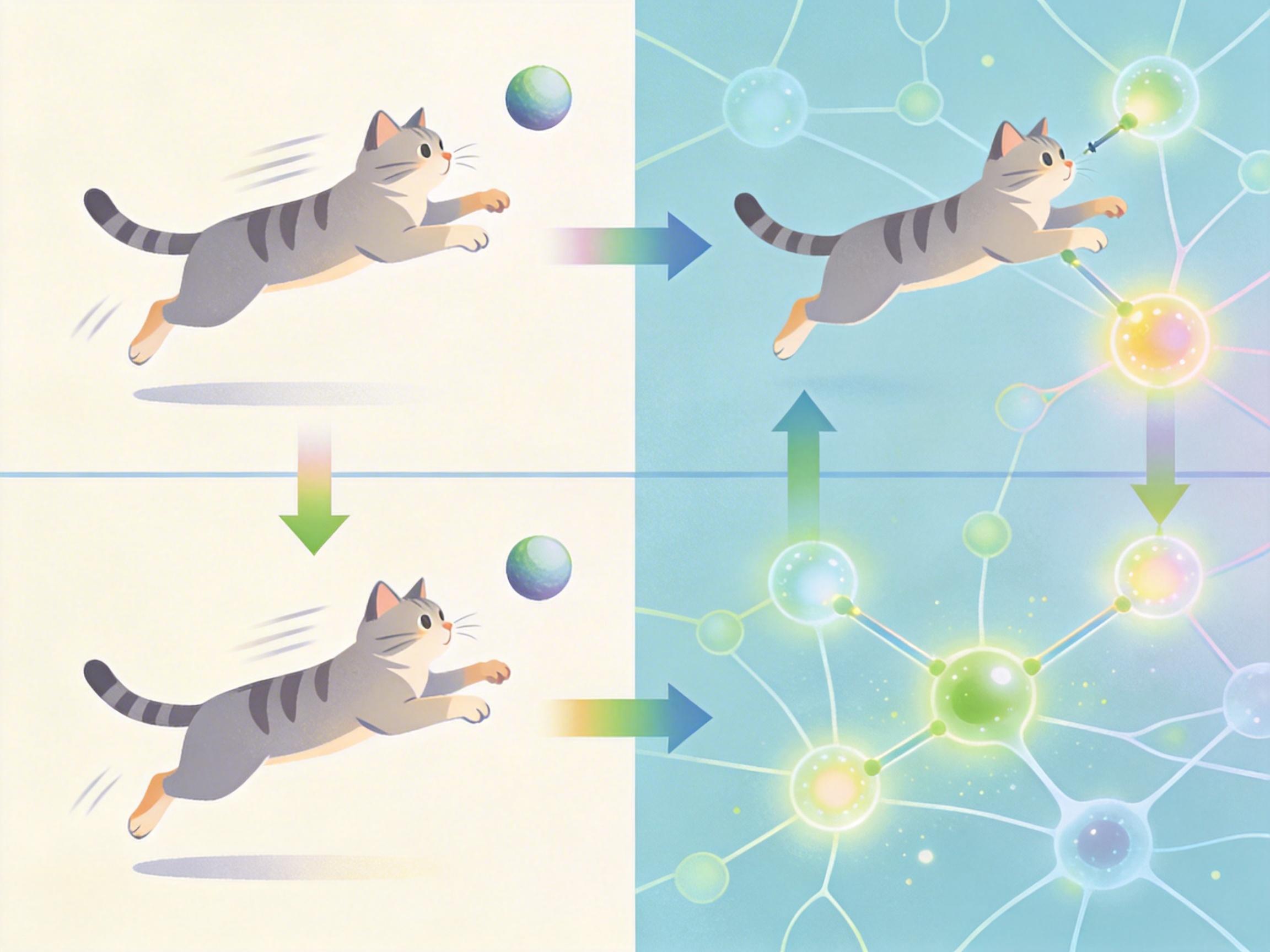
举个直观的例子:当你给它一张“猫咪接球”的视频,它不再只识别“猫咪”和“球”这两个物体,而是能看懂“猫咪在第3秒接到了球”这个动态过程,还能把这个过程用文字描述出来。这种跨模态的理解能力,是单模态AI永远做不到的。
但真实的测试数据会给这种“全感官”能力泼冷水。
在空间推理题里,它能准确判断六面体的展开图,却走不出简单的迷宫——因为前者是固定规则的匹配,后者需要连续的逻辑推导;在图像识别里,它能找到奔跑的人、磨损的眼镜,却认不出“不开心的冰块”——因为情绪是抽象的,没有固定的视觉特征可以匹配;它能处理7小时长音频的完整逻辑,却搞不定一张钟表图的时间——因为钟表的指针位置需要精确的空间计算,而模型更擅长“模糊匹配”常见的时间样式。
这些失误的本质,是多模态AI的“思考”方式和人类不同:人类是先理解逻辑,再匹配信息;而AI是先匹配海量数据里的相似案例,再用逻辑去“圆”答案。当遇到没有足够训练案例的抽象问题,或者需要精确计算的问题时,它就会露馅。
更关键的是,多模态数据的“对齐难题”一直在拖后腿。比如视频里的声音和画面差了0.1秒,人类能自动修正,但AI会把“猫咪叫”和“狗狗跳”错误关联;不同语言的图文对里,同一个手势的含义可能完全相反,AI没有人类的常识储备,很容易被误导。
现在的多模态AI,就像刚学会走路的孩子——能跑能跳,但还走不稳,离真正的实用还有三道关要过。
第一关是数据关。高质量的多模态数据集比黄金还贵:标注一张图片的成本是几块钱,标注一段视频的成本是几百块,还要保证声音、画面、文字的完全对齐,目前全球公开的高质量多模态数据,还不到单模态文本数据的1%。而且不同领域的数据壁垒严重,医疗影像、自动驾驶的多模态数据,几乎不可能公开共享。
第二关是效率关。现在的多模态模型动辄万亿参数,训练一次要花上亿元,推理一次的成本是单模态模型的5-10倍。要让它能在手机、汽车这些边缘设备上运行,就必须把模型“减肥”到原来的1/100,同时还要保证性能不下降——这相当于把一本百科全书压缩成一本小册子,还要让读者能找到所有信息。
第三关是信任关。AI的“幻觉问题”在多模态领域被放大:它可能会给一张不存在的图片编出详细的文字描述,或者把一段音频的内容完全曲解。在医疗、自动驾驶这些高风险领域,哪怕一次失误,都可能造成严重后果。
我们总说,AI要像人类一样思考,但多模态AI的进化路径告诉我们:先学会“感知”世界,再学会“理解”世界,可能更符合技术的逻辑。它不需要像人类一样拥有情感和意识,但需要学会像人类一样“较真”——在模糊的信息里找到精确的逻辑,在复杂的场景里抓住核心的问题。
感知是基础,精准才是核心。 当多模态AI终于能准确认出钟表的时间,能走对每一个迷宫,能听懂每一句弦外之音时,它才真正具备了改变世界的能力。而那一天,可能比我们想象的还要远,但每一次测试里的失误,都是在往那个方向靠近一步。