对抗知识焦虑,从看懂这条开始
App 下载
AI推理能力爆发,竟靠这两种后训练魔法
推理能力提升|后训练技术|SRFT|ResT|美团ASX团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推理能力提升|后训练技术|SRFT|ResT|美团ASX团队|大语言模型|人工智能
当你还在惊叹GPT-4o能解高数题时,一个40亿参数的开源模型已经在单轮工具调用上超过它4.11%,多轮任务领先1.50%。这不是参数堆出来的奇迹,而是来自美团ASX团队在ICLR 2026上公布的后训练技术——ResT和SRFT。它们没有给模型扩容,只是换了一种“教”的方式,就让AI的推理能力完成了一次跃迁。这背后藏着大语言模型“第二次成长”的核心秘密:比预训练更关键的,是后训练的策略。
你可以把大语言模型学工具调用想象成学生做应用题:一开始得先搞懂格式——要写“解”,要列公式,不能乱涂乱画;等格式熟了,再去练怎么算对答案。传统的强化学习训练就像老师只看最后得分,学生可能靠蒙答案拿高分,却没学会真正的推理逻辑。 ResT的思路是给每个“解题步骤”单独打分。它把模型输出的每个token(可以理解成语言的最小积木)分成两类:一类是低熵的“格式token”,比如工具名称、参数符号,这些是必须写对的“解题格式”;另一类是高熵的“推理token”,比如思考过程、参数计算,这才是真正体现能力的部分。
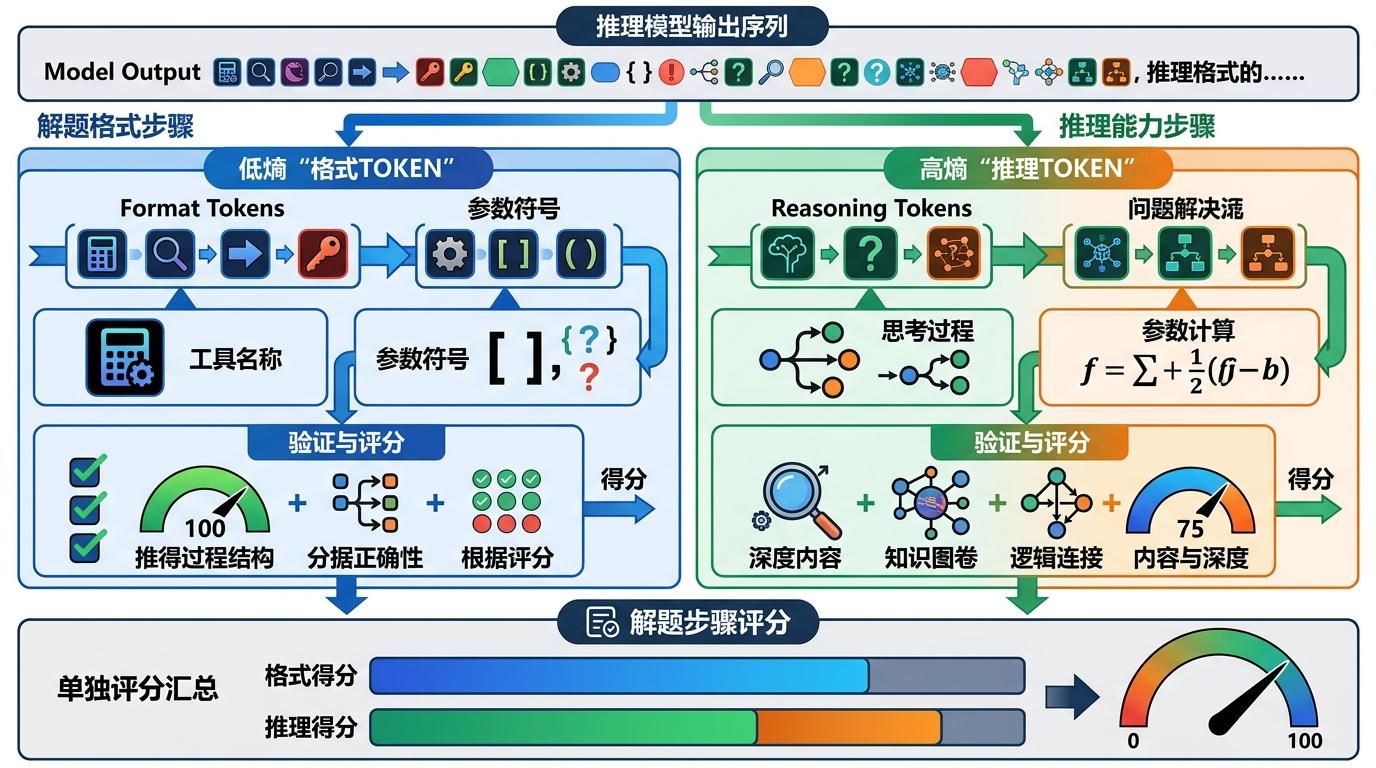
训练时,ResT会先盯着低熵token,确保模型把工具调用的“格式”练熟,随着训练推进,慢慢给推理token增加权重,让模型从“凑格式”转向“真思考”。这种熵感知的动态调整,就像老师先抓卷面整洁,再抓解题思路,既避免了学生一开始就跑偏,也不会让他们困在格式里出不来。 在BFCL和API-Bank等工具调用基准测试中,ResT比传统方法最高提升8.76%的准确率,在4B参数模型上实现了对GPT-4o的局部反超——这证明,给模型找对学习节奏,比单纯堆参数更高效。
过去训练大模型推理能力,得先让它“模仿做题”——用监督微调(SFT)把专家的解题步骤刻进模型;再让它“刷题改错”——用强化学习(RL)让模型自己试错,靠奖励信号优化。但这两步分开走,很容易出问题:要么模仿太死,模型只会套模板;要么刷题太野,模型学偏了方向。 SRFT的创新在于,把“模仿”和“刷题”放进了同一个课堂。它发现,监督微调是给模型做“粗粒度的全局塑形”,就像老师给学生讲一遍解题框架;而强化学习是做“细粒度的局部修正”,像学生自己刷题时调整思路。如果能让这两个过程同时进行,模型就能一边学框架,一边练细节。 具体来说,SRFT会同时给模型喂两种数据:一种是专家的示范题,让模型模仿;另一种是模型自己生成的练习题,让它自己试错。它还会用策略熵当“学习进度条”:当模型还在摸索框架时(熵高),就多给模仿任务加权重;等模型框架熟了(熵低),就多给刷题任务加权重,避免模型过早陷入固定套路。
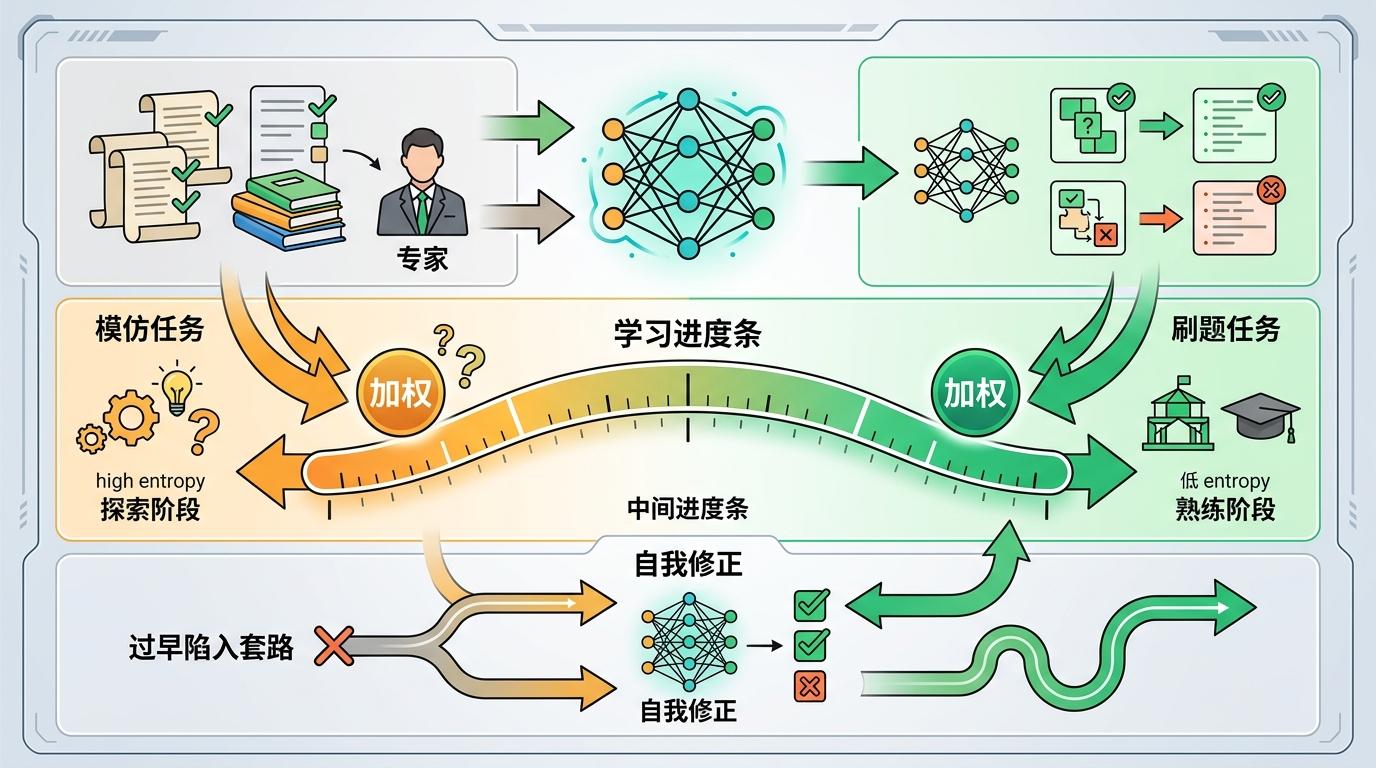
在数学推理基准测试中,SRFT比纯监督微调提升4.8%,比零强化学习的基线提升9%,在分布外的陌生题目上,准确率领先最佳基线4.7%。这说明,让模型边学边练,比先学后练的效果要好得多。 当然,这些技术也不是万能的。ResT在超复杂多轮工具调用任务中,仍会出现推理链条断裂的情况;SRFT的单阶段训练对计算资源的调度要求更高,普通实验室很难复刻。但它们的核心思路——用更精细的策略引导模型学习,而不是靠堆数据和参数——已经成为后训练的新方向。
除了ResT和SRFT,美团ASX团队还公布了另外4项研究:用多智能体辩论提升逻辑推理的MAD-Logic,能预测模型迁移能力的SAE评分系统,评测逻辑一致性的LogiConBench,还有让视觉语言模型自主进化的ViPER。这些研究指向了同一个趋势:大语言模型的竞争,已经从预训练的“参数军备竞赛”,转向后训练的“能力精细化战争”。 比如LogiConBench这个评测基准,它能生成无限量的复杂逻辑题,当前最先进的模型在最难的任务上准确率也只有34%——这暴露了大模型在逻辑一致性上的短板,而这恰恰是医疗、法律等严肃场景最看重的能力。再比如基于SAE的迁移能力预测,能在模型微调前就判断它在新领域的表现,相当于给模型做“能力体检”,避免了盲目训练的浪费。 这些技术已经开始落地:ResT方法被用到了美团的小团算法自训练模型中,在离线和在线评测中都拿到了实际收益;SRFT的单阶段训练思路,也被用于优化数学推理模型的训练效率。
当我们谈论大模型的“智能”时,往往会盯着参数规模、预训练数据量这些显性指标,却忽略了后训练这个“隐形的老师”。ResT和SRFT的成功证明,AI的能力提升,本质上是人类对“教AI学习”这件事的理解在加深。 未来的大模型,可能不再是靠堆参数堆出来的“超级学霸”,而是靠精准训练策略教出来的“会思考的学生”。预训练给AI知识,后训练给AI智慧。这句话或许会成为大语言模型下一个阶段的核心注脚。