对抗知识焦虑,从看懂这条开始
App 下载
AI写对字的秘密:给强化学习换个好裁判
强化学习裁判|OCR模型|中文文字生成|华中科技大学白翔团队|TextPecker|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载强化学习裁判|OCR模型|中文文字生成|华中科技大学白翔团队|TextPecker|大语言模型|人工智能
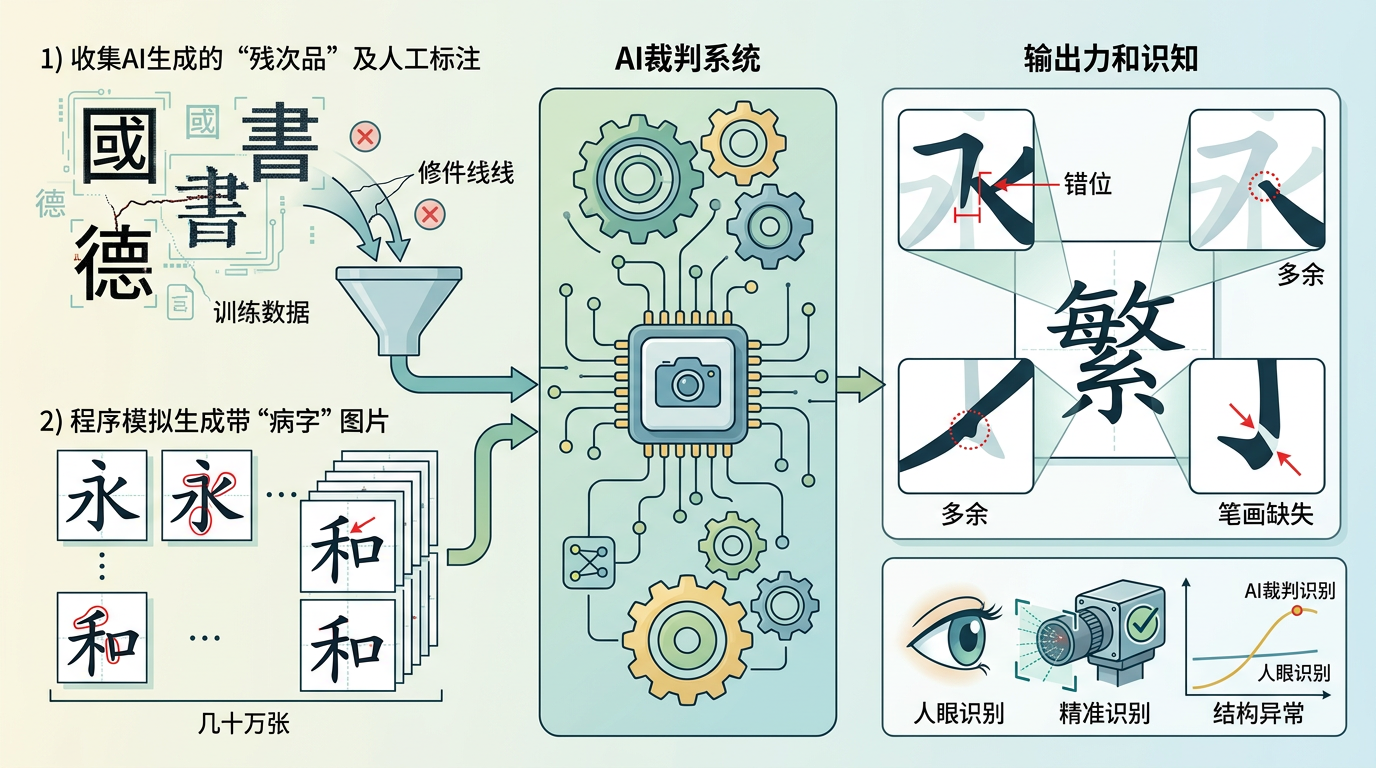
你有没有过这种经历?让AI生成一张带中文的海报,结果上面的字要么缺胳膊少腿,要么笔画拧成一团,明明语义是对的,却连“促销”两个字都认不出来。这不是AI偷懒,是它的“裁判”出了问题——过去用来评估文字生成质量的OCR模型,会把缺笔画的“销”自动脑补成正确的字,还给AI发“优秀”奖励。直到华中科技大学白翔团队的TextPecker出现,这个困扰行业多年的死结才被解开:给强化学习换个能看懂笔画的“啄木鸟裁判”,让AI终于学会写结构完整的字。
我们得先搞懂AI学写字的逻辑:现在的文生图模型大多用强化学习优化,简单说就是AI生成一张图,“裁判”打分,分高就给奖励,AI下次就照着这个方向学。过去的裁判是OCR模型或者多模态大模型——它们的问题是,只看语义对不对,不管结构完不完整。
比如AI生成的“饭”少了最后一点,OCR会自动忽略这个小缺陷,因为从语义上它更像“饭”而不是别的字,于是给AI打高分。还有更离谱的,AI把“店”的点写在了“占”的外面,OCR直接跳过这个模糊区域,当成没看见,照样给奖励。
这就像老师改作业,只看答案对不对,不管学生字写得有多乱,甚至把错别字当成对的。AI学不到正确的结构,自然永远写不出工整的字,尤其是中文这种笔画复杂的文字,问题更严重。
TextPecker的核心,就是给AI换了个“啄木鸟裁判”——它专门盯着文字的结构异常,比如笔画缺不缺、位置对不对,绝不放过任何小瑕疵。
这个裁判怎么练出来的?团队花了大功夫:先收集了大量AI生成的“残次品”,人工标注每个字的结构问题;然后针对中文的复杂结构,用程序模拟笔画缺失、错位、多余这些错误,生成了几十万张带“病字”的图片。用这些数据训练出来的裁判,能精准识别每个字符的结构异常,甚至比人眼还敏锐。
裁判的打分规则也变了:不再只看语义,而是把结构质量和语义对齐结合成复合奖励。结构质量分直接算“病字率”,哪怕只有一个字缺笔画,也会扣重分;语义对齐分则用词级匹配,就算AI把文字顺序打乱了,也能准确判断内容对不对。
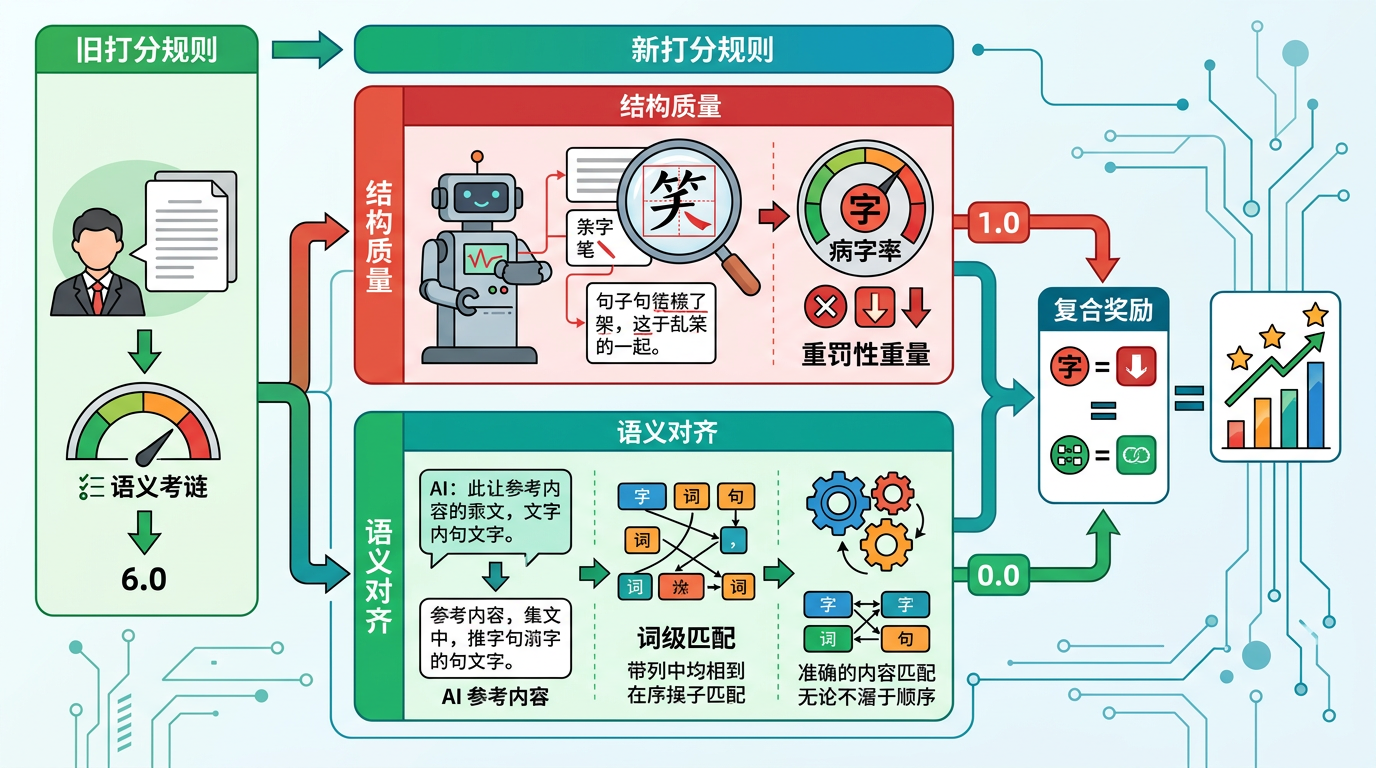
最关键的是,这个裁判是“即插即用”的,不用修改AI的底层模型,随便套在FLUX、Qwen-Image这些主流模型上就能用。测试结果吓人:FLUX的语义对齐度提升38.3%,结构保真度提升31.6%;就连已经针对中文优化的Qwen-Image,也能再提升8.7%的语义对齐度和4%的结构保真度。
别小看这几个百分点的提升,它直接把AI文字生成从“玩具”拉到了“工具”的级别。过去AI生成的海报、广告,因为文字错误百出,根本没法直接商用,设计师得花大量时间修改。现在有了TextPecker,AI生成的文字不仅语义正确,笔画也工整清晰,直接就能用在电商详情页、广告海报这些商业场景里。
更重要的是,TextPecker给AI生成内容的“可信度”打了底。文字是信息传递的核心,如果AI连字都写不对,生成的内容再好看也没用。现在有了能看懂结构的裁判,AI终于能生成让人放心的内容,这为AI Agent自主设计海报、多模态大模型输出图文内容铺平了道路。
当然,它也不是完美的——在极端艺术字体里,结构异常和艺术变形的界限太模糊,裁判偶尔也会出错。但这已经是巨大的突破,至少现在,AI终于能写对一句完整的、结构工整的中文了。
我们总说AI要“理解人类”,但很多时候,AI缺的不是理解能力,而是一个能精准反馈的“老师”。TextPecker的意义,不止是让AI写对了字,更在于它指出了一个方向:AI的进步,有时候不需要复杂的模型架构革新,只需要把“裁判”的标准搞对。
当AI终于能写出结构完整、语义准确的文字,它和人类的视觉沟通才算真正打通了最后一公里。毕竟,能看懂笔画的AI,才能真正看懂人类的表达。
好的AI,先从写对一个字开始。